쿠버네티스 내부에 있는 애플리케이션들은 pod가 될 수도 있고 replicaset이 될 수도 있고 deployment가 될수도 있고 서비스가 될 수도 있다.
서비스에도 타입이 3가지가 존재한다(clusterip, nodeport, LB).
이것들이 kubernetes 안에 object 형태로 제공되고 있다.
이 서비스들을 만들기 위해서는 아래쪽에 시스템이 컨테이너 형태로 제공되고 있다.
사용자가 이 쿠버네티스에 접근하기 위해서는 api-server를 따라서 접근해야만 한다.
api-server에 접속할때에도 인증된 사용자만 접속이 될 수 있도록 하기 위한 설정이 필요한데 이때 필요한 것이
export KUBECONFIG=/etc/kubernetes/admin.conf
이 안에는 인증서가 있어서 그걸 현재 환경으로 불러오겠다는 것이다. 이것에 대한 권한을 root들에게 전달해주겠다는 것이다.
이걸 아침마다 입력하는게 너무 귀찮기 때문에 이걸 지정해놓자
auth -> authentication(인증)=사용자 확인(user,pwd), authorization(인가)=인증 통과 사용자에게 권한 부여


kauth라는 파일을 만들어서 위와같이 내용을 작성해주자
권한은 700으로 부여해주자
```
mv kauth /usr/bin
```
으로 이동시키어서 명령어서처럼 실행시킬 수 있도록 만들어주자

클라우드의 노드 이름
- control node (인증, 전체 관리)
- compute node (컨트롤노드로 부터 작업 지시서를 받고 이를 수행)
- network node (전체 오버레이 네트워크를 만들고, 외부 연결을 담당 - 별도의 add-on 사용(calico, weavenet, flannel))
- storage node (별도의 스토리지를 사용하여 인스턴스 | 컨테이너에게 볼륨을 제공한다. 인스턴스나 컨테이너가 이동하더라도 볼륨의 위치는 고정되어 있으므로 지속적으로 영구적으로 볼륨을 연결하여 사용할 수 있다 = Persistent Volume)
????
이제 컨트롤 노드가 함께 연결된 컴퓨트 노드들에게 작업지시를 내리게 된다.
그러면 컴퓨트노드들은 각자의 Hypervisor(kvm, Esxi) 혹은 Docker(containerd), Podman, Rocket, CRI-O 등이 이 작업을 수행하게 된다.
결과 인스터트 혹은 컨테이너가 각 노드 위쪽에 생성되게 된다. 얘네들이 마치 overlay network에 붙어 있는것과 같이(L3->L2)로 만드는 과정을 거치게 된 것이다.
L2를 쓰는 이유는 L2 헤더는 계속 떨어졌다 붙었다 하기 때문에 동일 네트워크에서 유효하다.
L3 라우터(라우팅, 포워딩)의 작업을 수행하게 되기 때문에 헤더를 떼었다가 붙이는 작업을 하게 된다. 이는 시간 소요가 되기때문에 사설간의 소통을 위해서는 L2 스위치로 연결할 필요가 생기게 된다.
이러한 것들을 k8s에서는 별도의 add-on으로 동작시킨다.
---
????
storage node가 필요한 이유. 컨테이너 이미지는 정적이지만 이것에 대한 정보를 가지고 있는 것은 스토리지이다. 스토리지 없이 생성할 경우 데이터는 휘발성이다. 그래서 각 노드에 디스크를 만들어서 컨테이너의 디스크와 연결하는 작업을 했다. 그러면 스토리지의 데이터가 삭제되지 않는 한 유지는된다.
문제는 컨테이너가 다른 노드에서 생성된 경우 정보를 못 불러올 수 있다. 이를 방지하기 위해서 외부에 스토리지 노드를 따로 지정해놓을 필요가 생기는 것이다.
---
????
k8s의 특성
- 모든 리소스는 오브젝트 형태로 관리
- 명령어의 사용보다. YAML 파일의 사용빈도가 높다.
- 여러 개의 컴포넌트로 구성되어 있다.
모든 리소스는 오브젝트 형태로 관리
- 오브젝트는 추상화된 집합
- 도커 스웜모드의 서버스도 컨테이너 리소스의 집합을 정의한 것이므로 일종의 오브젝트
- Pods, Replica Set, Account, Node 등을 하나의 오브젝트로 사용할 수 있다.
- kubectl api-resources 를 통해 오브젝트 확인가능
YAML 파일의 사용빈도가 높다
- kubectl 명령어로 쿠버네티스 관리 가능
- docker stack과 달리 yaml로 사용 가능
- yaml 파일을 정의하여 k8s에 적용시키는 방식으로 배포
여러 개의 컴포넌트로 구성되어 있다.
- 마스터 노드 : kube-apiserver, kube-controller-manager, kube-scheduler, coreDNS
- 모든 노드 : 오버레이 네트워크 구성을 위한 프락시 kube-proxy(클러스터 내부에서 연결), 네트워크 플러그인 calico/flannel(클러스터 외부에서 연결 -> 외부 서비스시에는 필요), 클러스터 구성을 위한 kubelet 에이전트()
- k8s 입장에서는 도커 데몬 또한 하나의 컴포넌트이다. k8s에서는 반드시 도커를 사용해야 하는 것은 아니며, OCI(Open Container Initiative)라는 런타임 표준을 구현한 CRI(Container Runtime Interface)를 갖추고 있다면 어떠한 컨테이너를 써도 문제없다.
* kubelet 에이전트가 모든 노드에서 실행, 마스터에서 API 서버 등이 컨테이너로 실행
---
도커구조
????
도커와 같은 경우 리눅스 커널의 cgroups와 namespaces 기능을 이용하게 된다.
cgroup은 물리자원 사용량을 결정하게 된다. 이게 물리자원을 공유해서 사용할 수 있기 때문에 서비스 로드율에 따라 RAM의 사용량이 원했던것과 같이 정확하게 나누어지지 않을 수도 있다.
namespaces는 파티셔닝 작업으로 각각의 애플리케이션을 컨테이너 환경으로 구분시키어서 첫번째 httpd와 두번째 httpd가 서로에게 간섭이 일어나지 않게 해준다.
그런데 초기에는 리눅스 커널에 접속하기 위한 방법이 docker 쪽에 존재하지 않았다. Libvirt, LXC 등의 방법으로 추상화해서 접속했다. 그래서 이러한 소프트웨어의 기능이 바뀌거나 나중에 지원을 안하게 되면 문제가 되기 때문에 나온 것이 libcontainer 이고 또 나중에는 runC로 바뀌게 된다.
????
일반적인 도커는 명령/api을 전달하면 docker daemon 에 접속하고 docker daemon 은 containerd에 연결해준다. containerd는 이미지 관리, 컨테이너 라이프 사이클 관리를 하게 된다. containerd가 실행되면 자식 프로세스를 하나씩 재생산한다. 이때 생산된 자식 프로세스를 shim이라고 부른다.
이 자식 프로세스 shim이 runC를 이용해서 커널에 접속한다. 그리고 원하는 컨테이너를 생성하게 된다.
이러한 개념이다보니 k8s에서는 docker daemon을 구지 접속할 필요가 없어보였다. 그래서 빼버렸다.
---
포트 : 컨테이너를 다루는 기본단위
docker swarm vs k8s??
1. application 배포 단위 차이(contaier vs pod)
????
docker swarm으로구축하면 각 컨테이너가 생성되면서 위와같이 컨테이너의 갯수가 일치하지 않아 routing이 발생할 수 있다. 그래서 쓸떼없는 overhead가 발생할 수 있다. 결국 환경에 필요한 컨테이너가 완벽하게 뭉치어서 배포되어야 한다.
Pod는 한 개 이상의 컨테이너이다. Pod는 DB와 WP를 연결하여 배포하는 것 처럼 상호 대등한 서비스를 연결하여 외부에 서비스 하는 것도 있지만 하나의 컨테이너가 주로 서비스를 제공하고 남아있는 하나의 컨테이너의 주 컨테이너의 데이터를 백업하거나 로그를 제공하는 등의 보조적인 역활을 수행하는 경우도 있다. 이러한 보조 컨테이너를 "사이드 카"라고 부른다.
????
컨테이너는 포드에 ip를 공유한다.
또 이 pod 들을 연결하는 cluster에도 cluster ip도 따로 존재한다. cluster는 내부적으로 로드밸런서 기능을 수행하게 된다. cluster ip는 외부 연결 불가능하다.(kube proxy 이기 때문)
????
pod가 인터넷으로 연결하게 된다면 kube-proxy를 이용한다. 그리고 kube proxy가 외부로 직접나가는 준다.
Pod를 만드는 방법은 Pod 명령어 혹은 yaml을 이용하여 배포 가능하다.
Pod -> 명령어(kubectl run), Yaml을 이용하여 배포 가능
kubectl run으로는 replica와 deployment 모두 생성 불가능하다.
kubectl create로는 가능하다.
`kubectl apply -f test.yaml`
`kubectl create -f test.yaml`

실재로 kubectl create에 deployment와 같은 옵션이 존재하는 것을 확인할 수 있다. 하지만 반대로 pod는 존재하지 않는다. 그래서 명령어로 deployment를 생성하고자 한다면 kubectl create를 이용하면 된다.
pod는 `kubectl run`을 이용한다. 단, kubectl create는 파일로도 배포가 가능하다.
```
kubectl run nginx --image=nginx
kubectl delete pod nginx
kubectl run nginx --image=nginx --restart=Always
kubectl get pod
kubectl describe pod nginx
```
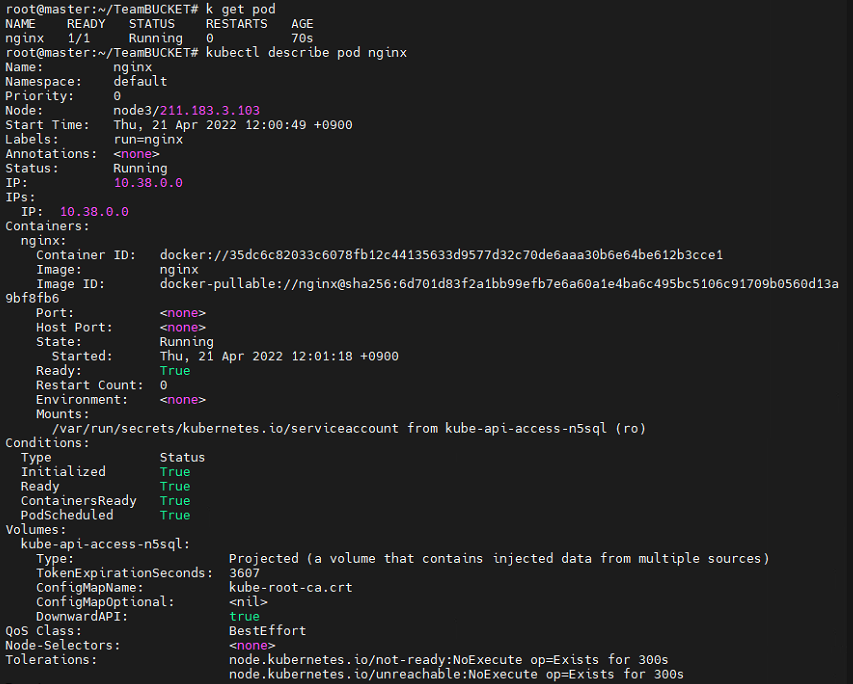
위와같이 pod의 정보를 확인할 수 있다.

생성된 node로 가보면 위와같이 수도 없이 많은 컨테이너가 돌고 있는것을 확인할 수 있다. 모두 필수적인 컨테이너들이다.
```
kubectl exec -it nginx -- /bin/bash
```

명령어를 이용해 명령을 전달할 수도 직접 조종할 수도 있다.(ctrl + p, ctrl + q로 탈출)
만든것을 삭제하고 다음 작업을 해보자
```
k delete pod nginx
```
ReplicaSet -> 포드를 실행할 때, 지정된 개수를 유지할 수 있도록 해주는 기능을 포함한다.
각 포드에 ()를 부여하고 RS은 지시자를 통해 해당 ()의 개수를 유지하려고 한다. ()=label
ReplicaSet + 롤링 업데이트 -> 동작중인 상태에서 서비스의 중단없이 컨테이너를 업데이트 하거나 롤백 기능을 제공한다. -> Deployment

먼저 api중에 deploy가 존재하는지 확인해보자
????
deploy는 네임스페이스에 포함되는 오브젝트 이므로 각 deploy를 namespace로 구분하여 운영할 수 있다. 나중에는 namespace 별로 rule, life cycle, resource, rolling update, security 적용등을 할 수 있게 된다.
namespace와 role의 차이점이 뭐가 되는걸까
---

먼저 여기까지만 작성해 놓고 세부적인 내용을 작성해보자

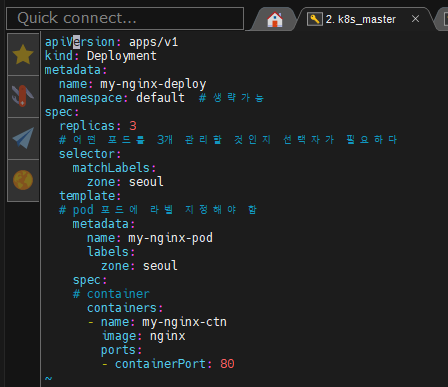
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx-deploy
namespace: default # 생략가능
spec:
replicas: 3
# 어떤 포드를 3개 관리할 것인지 선택자가 필요하다
selector:
matchLabels:
zone: seoul
template:
# pod 포드에 라벨 지정해야 함
metadata:
name: my-nginx-pod
labels:
zone: seoul
spec:
# container
containers:
- name: my-nginx-ctn
image: nginx
ports:
- containerPort: 80최종 완성된 형태는 위와같이 나오게 된다.
```
k apply -f deploy-nginx.yaml
```

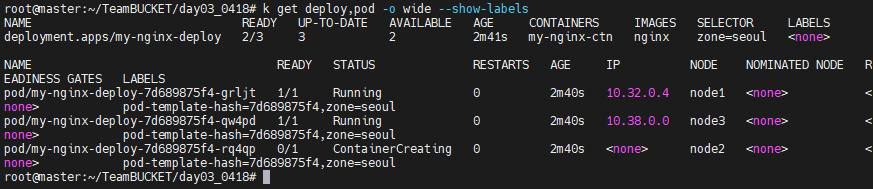
```
k get deploy,pod -o wide --show-labels
```
보면 위와같이 zone=seoul에서 배포된 deployment와 pod를 확인할 수 있다.
Deployment 이기 때문에 갯수가 유지되고 실재로 하나만 삭제해보아도 갯수는 계속 유지되는 것을 알 수 있다.

```
k delete pod <pod 명>
k get pod
```
pod의 갯수를 조절하려면 update를 해주면된다. update 방법으로
1. yaml 자체를 수정하고 apply하는 방법이 존재한다.
2. replicas 옵션을 이용하여 명령어로 배포하는 방법
```
kubectl scale deploy --replicas=5 my-nginx-deploy
```


```
k get pod
k get pod -o wide
```
이렇게 하고 갯수가 늘어났는지 확인해보면 원하는만큼 늘어난 것을 확인할 수 있다.
다시 세개로 돌릴수도 있다.
```
k scale deploy --replicas=3 my-nginx-deploy
```
---
명령어를 이용해서 pod 를 생성 및 조절도 가능하다.


```
k create deploy testnginx --image=nginx --replicas=1
```

```
k delete deploy testnginx
k delete deploy my-nginx-deploy
```

이번에는 자기가 이전에 만들고 docker hub에 올리었던 이미지로 컨테이너의 이미지 부분만 바꾸어주자

배포된 이미지를 확인 가능하고 curl로 따보니 실재로 우리가 긁어왔던 사이트의 이미지 코드가 보이는 것을 확인할 수 있다.
이미지만 명령어로 바꾸어줄 수도 있다.
```
kubectl set image deploy my-nginx-deploy my-nginx-ctn=tonyhan18/testweb:green
```


실재로 배포된 이미지가 바뀐것을 확인할 수 있다.

이 과정은 단순히 이미지가 바뀐것이 아닌 기존의 pod를 down으로 바꾸고 새로운 이미지가 있는 새로운 pod를 만들어낸 결과물이다.
revision으로 각 버전을 명칭하는데 이 상태에서 rollback 하면 down상태의 pod를 살려내고 새로만들었던것을 up해준다. 그렇다보니 이것을 보고 cold standby상태라고 부른다. 이 반대를 hot standby 로 두개다 움직이는 상태이다.
```
kubectl rollout history deploy my-nginx-deploy
```

하면 지금까지 우리가 했던 배포행위들을 볼 수 있다.
```
k rollout undo deploy my-nginx-deploy --to-revision=1
```

보면 down 되어 있던 pod가 점차 이전 상태로 돌아가고 있는 것을 확인할 수 있다.

실재로도 이전 상태로 돌아왔다.
replica-set을 확인해보면 어떻게 된 상태인지도 볼 수 있다.
```
k get replicaset
```

빠르게 배포는 되는데 외부에 서비스는 안된다.
생성된 포드를 외부에 노출하고자 하는 경우에는 총 3가지 방법이 존재할 수 있다.

- cluster IP
1) 클러스터 외부, 인터넷에서의 접속은 불가
2) 다른 클러스터에서의 접속 허용
클러스터 내의 외부에 있는 사용자가 kube proxy를 총해서 접속하면 clusterIP로 접속하게 되고, clusterIP는 Pod를 묶는 하나의 IP이다. 단 clusterIP는 쿠버네티스 내부에서의 접속만 허용하고 외부접속은 불가능하다.

- Node Port
1) 인터넷 접속 가능
2) node1, node2 등에 있는 각 노드의 포트를 지칭
3) 특별히 지정하지 않고 nodeport type의 서비스를 사용하면 포트번호 30000 ~ 32767 사이에서 랜덤으로 지정된다.
인터넷에서 접속을 하는 방법중 하나이다. 외부에서 proxy로 접속하면 각각의 노드에 있는 특정 포트로 접속하게 되는데 이 포트를 랜덤/지정해줄 수 있다. 이렇게 접속하면 NodePort는 ClusterIP로 또 넘기어주고 ClusterIP는 Pod 들을 연결하는 하나의 IP이다. ClusterIP의 특정 포트를 지정해주면 ClusterIP의 8080으로 들어온 친구는 Pod에게 넘기어준다. Pod가 nginx이면 80번 포트이다. 그래서 ClusterIP에 pod만큼의 port가 필요하다.
장점 : 로드밸런서 없이 접속 가능
단점 : IP:Port와 같이 직접 매핑해야하므로 한 노드에 트래픽이 집중. Port 범위가 30000~32767 로 한정됨 그래서 80번 포트로 접속을 하기 힘듬. ClusterIP 쪽에서 라운드 로빈을 해주지만 라우팅이 발생하므로 불필요한 트래픽이 내부에 발생하여 안 좋음.
로드밸런서를 사용하고자 한다면 node 앞에 물리적인 서버 또는 L4 스위치를 배치하고 공인 주소는 frontend, node의 IP, port를 backend로 등록하여 운영하는 방법이 가능하다.
CentOS7 버전 하나 실행(vNIC1 : bridge - 10.5.1.X, vNIC2 : VMnet8 - 211.199.3.99)를 설정하고 외부에서 10.5.1.X로 접속하면 노드의 IP, Port를 통해 포드까지 접속 가능해야 함
처음 CentOS(minimal install)를 설치할 때 bridge를 DHCP로 설정하면 자동으로 사용가능한 주소를 받아오는데 이 주소를 static으로 변환하여 사용하기

- LB(포드를 이용하여 위의 기능을 대치한다.)
1) 인터넷 접속 가능
2) 일반적으로 퍼블릭 클라우드에서 대부분 사용하는 방법
type을 LoadBalancer로 하면 퍼블릭 클라우드에 LB 서비스가 연결되어 자동으로 LB를 생성하고 외부 연결용 external ip를 제공해 준다.(metal LB)
---
실습 : 노드포트로 배포해보기
CentOS에는 HAProxy를 설치해주고 백엔드 IP는 NodePort로 연결해주자

apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-nginx
spec:
replicas: 3
selector:
matchLabels:
app: my-nginx-pods-label
template:
metadata:
name: my-nginx-pod
labels:
app: my-nginx-pods-label
spec:
containers:
- name: nginx
image: tonyhan18/testweb:green
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-nodeport
spec:
ports:
- name: nginx-port
targetPort: 80
port: 80
nodePort: 31008
selector:
app: my-nginx-pods-label
type: NodePort01.deploy-svc-nginx.yaml
centos haproxy는 이렇게 만들었다.


배포 단계에서 보면 모든 vm들은 31008의 NodePort를 가지고 있다. 그리고 서비스 포트 80번으로 모두 연결되어 있다. 그리고 이 안에는 pod들이 80번으로 연결되어 있다.
이들 맨 앞에 centos LB를 두었다. 사실상 내부에도 로드밸런서가 있다고 볼 수 있다.

```
kubectl get svc
k describe svc
```
그런데 이렇게 되면 로드밸런서가 사실상 두개라서 내부적으로 라우팅이 발생할 수 있다.

apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-nginx
spec:
replicas: 3
selector:
matchLabels:
app: my-nginx-pods-label
template:
metadata:
name: my-nginx-pod
labels:
app: my-nginx-pods-label
spec:
containers:
- name: nginx
image: tonyhan18/testweb:green
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-nodeport
spec:
ports:
- name: nginx-port
targetPort: 80
port: 80
#nodePort: 31008
selector:
app: my-nginx-pods-label
type: LoadBalancer그러니 이제 CentOS는 치워버리고 그냥 Object 형태로 배포해보자
```
k apply -f deploy-svc-nginx.yaml
k get svc
```

위와같이 ip가 뜬것을 확인할 수 있다. 이상태에서 211.183.3.100 manager로 접속해보자

External-IP로 나와있는 211.183.3.201로 접속해보니 load balancing 된것을 확인할 수 있다.

이게 3번째 방식이다.
이렇게하면 Cluster 내부에 NodePort가 없는 거이 아니다. 존재는 하는데 이걸 LoadBalancer와 연결해서 내부의 NodePort로 연결을 시켜준 것이다.
이전에는 로드밸런서 서비스를 했는데 어짜피 이제 안 쓸 방법이니 꼭 알필요까지는 없다.
네임스페이스(Namespace) : 리소스의 구분

용도에 따라 컨테이너와 그에 관련된 리소스를 구분짓는 그룹의 역활

kube-system 내부에 있는 것들은 절때로 지워서는 안된다.

네임스페이스는 라벨보다 넓은 의미로 사용됨
ResourceQuota 오브젝트 사용하여 포드의 사용량 제한가능
애드미션 컨트롤러를 이용해 포드에는 항상 사이드카 컨테이너를 붙이도록 할 수 있음
포드, 서비스 등의 리소스를 격리함으로써 편리하게 구분
리눅스 커널 자체를 쓴다고는 했는데 실재로는 runC를 사용

Namespace를 쓰기위한 yaml파일은 위와같이 작성해주는데 구지 이렇게 하지 않고 k create namespace가 더 빠르다.
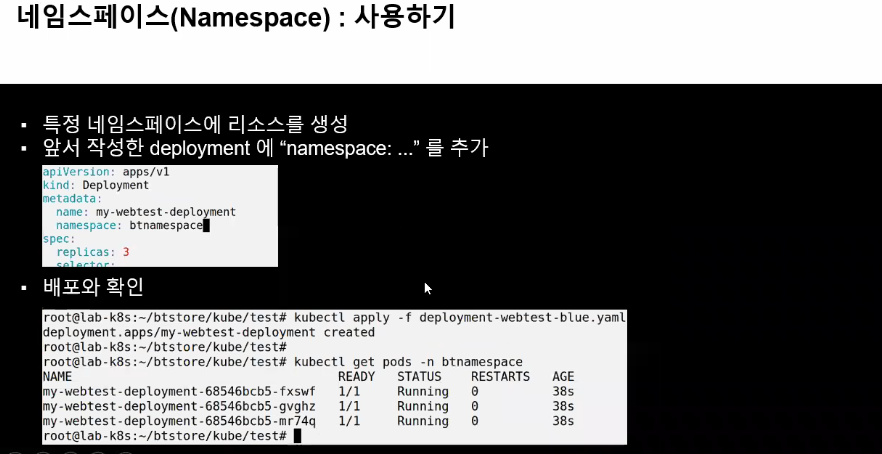
namespace가 만들었다면 특정 namespace에 속하도록 만들 수 있다.
```
k get ns
```

하면 위와같이 네임스페이스들이 보인다. 일반적으로 포드를 만들면 default에 속하게 되는데 api-resources들이 모두 namespace에 속하는 것은 아니다.
namespace를 이용해서 각각의 리소스들을 구분해서 제공해줄 수 있다.

보다보면 persistentvolumeclaims가 보이는데 이건 사용자가 원하는 볼륨을 요청하면 persistentvolumes에서 끄집어서 가지고 온다.
암튼 운영팀에서는 volume 을 미리 만들어 놓고 요청이 들어오면 해당 팀에 이어주어야 하니 persistentvolumes 자체는 namespace를 지정해주면 안된다.
그럼 부서들은 persistentvolumeclaims을 이용해서 가져온 볼륨에 namespace를 지정해서 자기만의 부서에서 사용할 수 있게 해주어야 한다.
관리하는 각 회사, 각 프로젝트, 각 테넌트 별로 별도의 네임스페이스를 운영하고 프로젝트 진행시 포드 등을 배포할때에는 ns를 추가하여 생성한다. 삭제할 때에는 각 오브젝트를 하나씩 삭제할 필요없이 ns만 삭제하면 된다.
(마치 gcp에서 프로젝트 진행시 project를 만들고 그 프로젝트 내에서 모든 작업이 이루어진다. project만 삭제하면 해당 프로젝트 내에 있는 모든 인스턴스, 네트워크, 볼륨등이 삭제되는 것과 비슷)
네임스페이스 만들기
1. 명령어로 만들기
```
kubectl create ns samsung
kubectl run sspod1 --image=nginx -n samsung
```

보면 위와같이 k get pod하면 samsung namespace것은 안뜬다.
```
k get pod -n samsung
```
해야만 분리된 공간에 존재하는 pod가 보이게 된다.
service도 namespace를 사용하기 때문에 각 회사별로 별도의 namespace를 제공해주면 된다.
다음 시작전에 모두 지우자
```
k delete pod,deploy,svc --all
```
이렇게하면 모두 삭제는 되는데 samsung 것은 안지워진다.
```
k delete pod,deploy,svc --n samsung --all
```

2. yaml로 만들기
---
실습

samsung.yaml과 lg.yaml을 만들었다. 원본 리소스는 01.deploy-svc-nginx.yaml 이다.

---
apiVersion: v1
kind: Namespace
metadata:
name: samsung
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-ss
namespace: samsung
spec:
replicas: 3
selector:
matchLabels:
app: my-ss-pods-label
template:
metadata:
name: my-ss-pod
labels:
app: my-ss-pods-label
spec:
containers:
- name: ss
image: tonyhan18/testweb:blue
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: ss-port
namespace: samsung
spec:
ports:
- name: ss-port
targetPort: 80
port: 80
#nodePort: 31008
selector:
app: my-ss-pods-label
type: LoadBalancersamsung.yaml
구지 포트 구분안해도 ip로 구분되기 때문에 80:80으로 설정은 유지해주자

---
apiVersion: v1
kind: Namespace
metadata:
name: lg
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-lg
namespace: lg
spec:
replicas: 3
selector:
matchLabels:
app: my-lg-pods-label
template:
metadata:
name: my-lg-pod
labels:
app: my-lg-pods-label
spec:
containers:
- name: lg
image: tonyhan18/testweb:green
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: lg-port
namespace: lg
spec:
ports:
- name: lg-port
targetPort: 80
port: 80
#nodePort: 31008
selector:
app: my-lg-pods-label
type: LoadBalancerlg.yaml

```
k get pod,svc -n lg
k get pod,svc -n samsung
```
하면 위와같이 배포된 서비스들을 모두 확인 가능하다.
---
여기에서 문제가 삼성, lg 쪽 관리자는 이것들을 어떻게 컨트롤할지에 대한 의문이 생긴다.
각 회사 네임스페이스 관리를 위한 계정 생성해야한다. 각 계정의 권한에 제한을 두어서 타 네임스페이스 접근자체를 막아야 한다.
서비스를 위한 계정 생성, 생성된 계정에게 필요한 특정 역활을 부여해야 한다. -> ServiceAccount, ClusterRole/ClusterRoleBinding 오브젝트를 사용하자.
(ClusterRoleBinding : ServiceAccount와 ClusterRole을 이어주는 역활을 수행)

ServiceAccount 오브젝트를 확인해보자 현재 default라는 ServiceAccount가 보인다.

metallb-system을 sa를 확인해보면 3가지가 보인다.
정확한 실습은 나중에해보자
---
컨피그맵, 시크릿
설정값을 포드에 전달하기

예를들어 namespace로 구분된 곳에 각각 다른 mysql을 배포하기 위해서 매번 새로운 이미지를 만드는 것은 거의 불가능하다. 그래서 k8s의 변수라고 불러도 되는 컨피그맵, 시크릿을 사용하게 된 것이다.
결국 컨피그맵은 설정값을 포드에 전달하는 역활이다. 그래서 패스워드와 같은 값을 포드로 전달할때 사용하게 된다.

yaml 파일과 설정값을 분리할 수 있는 것이 Configmap, Secret이다.
Configmap은 가급적 설정값
Secret은 비밀키
코드를 보면 configMapKeyRef라는 부분이 있다. name은 log-level-config라 했고 key는 LOG_LEVEL이라고 했다.
이 상태에서 한쪽은 LOG_LEVEL에 INFO를 넣고 다른쪽은 DEBUG라는 값을 넣었다.
```
kubectl create configmap test1-cmap --from-literal INSTANCE=CENTOS7
# key-value를 configmap에 저용한 모습이다.
kubectl create cm test2-cmap --from-literal NAME=GILDONG --from-literal ZONE=AP-NORTH-EAST2-a
```
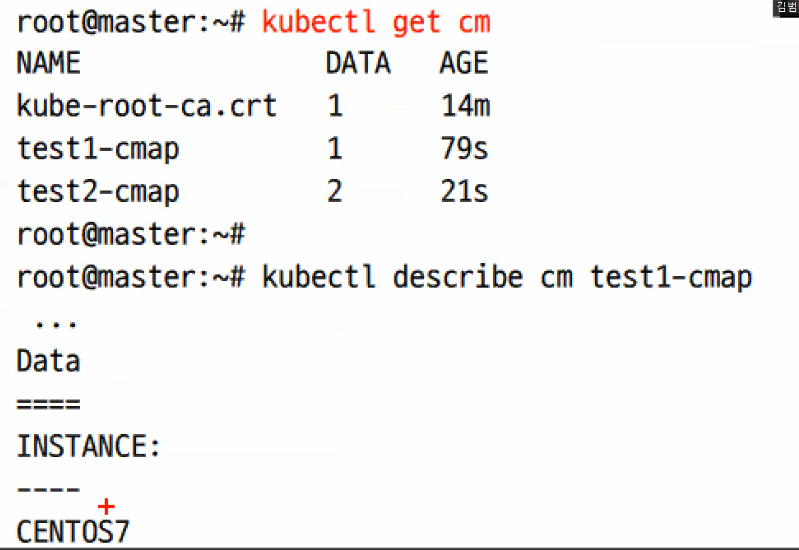
그래서 배포해서 키값을 보면 위와같이 나오게 될 것이다.
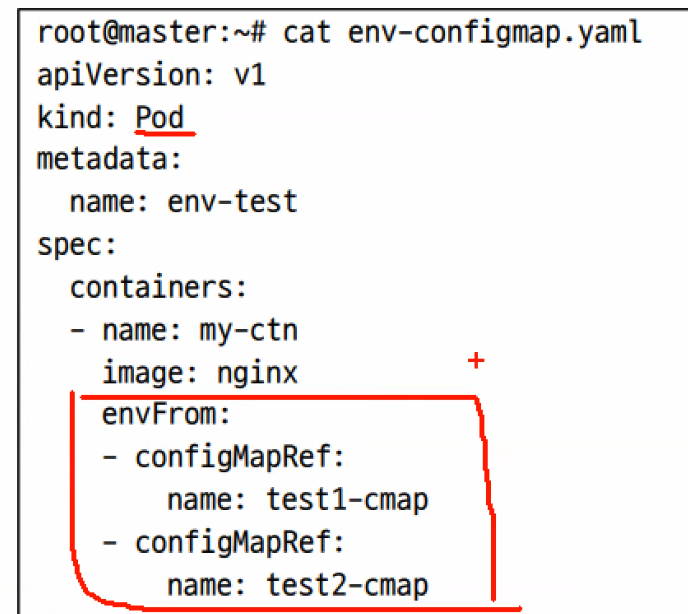
배포시에는 envFrom안에 configMapRef 부분을 넣어주면 된다.
라는것을 내일해보자
'Development(Web, Server, Cloud) > 22) LINUX - Cloud' 카테고리의 다른 글
| 클라우드 64일차 (MSA, 다이나믹 pvc, 동적 pv, 정리중) (0) | 2022.04.25 |
|---|---|
| 클라우드 63일차(정리중, ingress, 정리중) (0) | 2022.04.22 |
| 클라우드 61일(kubernetes 개념, pod, Deployment, Metal LB, autoscaler, web-ui) (0) | 2022.04.15 |
| 클라우드 60일차 (0) | 2022.04.14 |
| 클라우드 59일차 (0) | 2022.04.13 |



