????
---
# 메인페이지용 코드
apiVersion: v1
kind: Pod
metadata:
name: pod-main
labels:
page: main
spec:
containers:
- name: ctn-main
image: nginx
ports:
- containerPort: 80
---
# 메인페이지용 서비스
apiVersion: v1
kind: Service
metadata:
name: svc-main
spec:
selector:
page: main
ports:
- port: 80
---
# blog 용 코드
apiVersion: v1
kind: Pod
metadata:
name: pod-blog
labels:
page: blog
spec:
containers:
- name: ctn-blog
image: tonyhan18/testweb:blue
ports:
- containerPort: 80
---
# blog 용 서비스
apiVersion: v1
kind: Service
metadata:
name: svc-blog
spec:
selector:
page: blog
ports:
- port: 80
---
# shop 용 코드
apiVersion: v1
kind: Pod
metadata:
name: pod-shop
labels:
page: shop
spec:
containers:
- name: ctn-shop
image: tonyhan18/testweb:green
ports:
- containerPort: 80
---
# shop 용 서비스
apiVersion: v1
kind: Service
metadata:
name: svc-shop
spec:
selector:
page: shop
ports:
- port: 80그래서 위와같이 포드와 서비스를 정의해주고

ingress도 정의해주자
기존에는 ingressClassName이 metadata 쪽에 있었는데 위와같이 spec 쪽에도 작성해줄 수 있다.
host와 http 부분도 만약에 ip를 그냥 사용한다면 host 부분을 아예 지우고 http를 올려버리면 ip로 통신이 가능해진다.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-testshop
spec:
ingressClassName: nginx
rules:
- host: www.testshop.co.kr
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: svc-main
port:
number: 80
- path: /blog
pathType: Prefix
backend:
service:
name: svc-blog
port:
number: 80
- path: /shop
pathType: Prefix
backend:
service:
name: svc-shop
port:
number: 80암튼 위와같이 shopingress.yaml을 배포해주면 된다.

이제 배포해보자
```
k apply -f podsvc.yaml
```

이제 testshop.co.kr을 master node에서 실행시키어보니 정상 실행되는 것을 볼 수 있다.

그런데 다른 도메인으로 접속은 안된다.
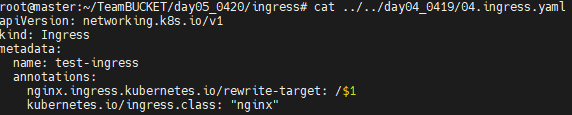
이게 이전에는 위와같이 rewrite-target 부분을 작성해 주었기에 도메인 파라미터를 보고 리다이렉트 해주었다. 그래서 이 부분이 추가되어야 할거 같다.

이렇게해서 하면 헤더 뒤쪽 부분까지 포함해서 접속하게 해준다.
다시 적용해주자
```
k apply -f shopingress.yaml
```


blog와 shop 부분이 정상적으로 열린다.
Quiz. 현재까지 작성된 내용은 각 페이지 별로 1개의 포드만 동작하고 있다. 우리는 서비스의 안정적인 운영을 위하여 고정된 개수의 포드를 지속적으로 동작 시키고자 한다.
main -> 1
/blog -> 2
/shop -> 3 개가 고정적으로 동작하도록 구성하기
이렇게 하기위해서는 deployment를 사용해주어야 한다.
---
# 메인페이지용 코드
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-main
spec:
replicas: 1
selector:
matchLabels:
page: main
template:
metadata:
name: pod-main
labels:
page: main
spec:
containers:
- name: ctn-main
image: nginx
ports:
- containerPort: 80
---
# 메인페이지용 서비스
apiVersion: v1
kind: Service
metadata:
name: svc-main
spec:
selector:
page: main
ports:
- port: 80
---
# blog 용 코드
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-blog
spec:
replicas: 2
selector:
matchLabels:
page: blog
template:
metadata:
name: pod-blog
labels:
page: blog
spec:
containers:
- name: ctn-blog
image: nginx
ports:
- containerPort: 80
---
# blog 용 서비스
apiVersion: v1
kind: Service
metadata:
name: svc-blog
spec:
selector:
page: blog
ports:
- port: 80
---
# shop 용 코드
apiVersion: apps/v1
kind: Deployment
metadata:
name: pod-shop
spec:
replicas: 3
selector:
matchLabels:
page: shop
template:
metadata:
name: pod-shop
labels:
page: shop
spec:
containers:
- name: ctn-shop
image: nginx
ports:
- containerPort: 80
---
# shop 용 서비스
apiVersion: v1
kind: Service
metadata:
name: svc-shop
spec:
selector:
page: shop
ports:
- port: 80위와같이 pod 부분을 모두 deployment로 바꾸어버리면 된다.
그런데 하다보니까 deploy-main에 대해서 갯수를 조절할 필요가 있다면 이 명령어를 사용해주자
```
k scale deploy --replicas=3 deploy-main
```
을 이용하면 좋다.
다 끝났으니 이제 지워주자
```
k delete -f .
```
[PV,PVC]
포드에게 볼륨 제공하기 (using nfs)
????
볼륨을 제공하는 방법은 두가지가 ㅈㄴ재한다.
1. 디렉토리와 디렉토리를 마운트 : file storage(nfs, cifs)
2. 볼륨(Disk) : block storage(EBS, cinder, glusterfs, ceph)
- 포드에 볼륨을 제공할 경우 iscsi, nfs 등의 방법을 사용하면
포드를 연결해야할 개발자는 해당 스토리지의 주소 등을 매핑할 수 있어야 한다. 하지만 이는 불편함이 많이 따른다.
- PV, PVC를 이용하면 개발자는 제공되는 볼륨이 NFS | iSCSI | FC | ... 등에 대해 알지 못하더라도 볼륨을 연결하는데 문제가 없다.
- 스토리지 관리자는 필요한 볼륨을 미리 생성해 두고 이를 pool에 담아 둔다.
- 정적인 방법
volume1 -> 5G -> 동시접속 가능
volume2 -> 10G -> 동시접속만 허용
- 동적인 방법 (스토리지 클래스)
정적인 풀에 없는 경우 사용자의 요청사항에 맞는 스토리지를 그때그때 만들어서 제공
포드는 자신이 직접 스토리지에 연결되는 것이 아니고 node를 통해 연결이 되므로 클라이언트 프로그램은 Pod가 아닌 Node에 설치되어 있어야 한다. 따라서 NFS를 이용한다면 node1 ~ node3 에는 아래의 설정이 미리 입력되어야 한다.
CentOS -> yum 또는 dnf 를 이용하여
yum -y install nfs-utils <-- 클라이언트가 포함되어 있음
ubuntu -> apt-get install -y nfs-common <-- 클라이언트

노드에서 이미 설치가 되어 있다는 것만 알아도 된다.
이상태에서 ip_forward 설정을 보아야 한다.
```
cat /proc/sys/net/ipv4/ip_forward
```

이게 1로 되어있다면 상관이 없다. forwarding이 가능하다는 의미이다.
????
가상화는
방화벽같은 경우에도 3가지 트래픽에 대해서 처리가 가능하다.(1. begin 2. terminate 3. Transit(forward))
방화벽에 인터페이스가 하나인경우 이 인터페이스로 들어와 종료되는 트래픽을 처리할 수 있다.(terminate)
인터페이스에서 나가는 것에 대해서도 처리가 가능하다(begin) : 특정 목적지로 가는것에 대해서 갈지 말지를 결정해줄 수 있다.
인터페이스가 두개가 있을때 가상 혹은 물리 브릿지가 있어서 연결되어 있을때 서버로 전달되는 트래픽에 대해서 방화벽을 거치어서 빠져나가거나 들어올경우. 즉 방화벽을 가로질러가는 것에 대해서 처리가 가능하게 해주는 경우(transit=forward)
이제 centos의 nfs 를 이용해서 각 노드에 연결해보자

이 상황에서 특정 디렉토리를 다른 노드들에게 공유해보자
k8s,naver 폴더를 공유해주면 된다.

두개의 폴더에 대해서 위와같이 설정해 놓자
no_root_squash는 외부 사용자가 NFS 서버에 접속하여 파일을 생성하였다면 해당 파일을 생성한 사용자를 누구로 기록하는가? - nfs nobody
no_root_squash로 하면 원격지의 root가 로컬에서도 루트가 된다.
---
[ 실습 ]
이제 pod를 배포하면서 nfs 와 연결되는지 확인해보자
```
vi 03.nfspod.yaml
```

apiVersion: v1
kind: Pod
metadata:
name: nfspod
spec:
containers:
- name: nfsctn
image: nginx
volumeMounts:
- name: nfsvol
mountPath: /backup
volumes:
- name: nfsvol
nfs:
path: /k8s
server: 211.183.3.99
nfspod에 ls 명령어를 옮기어보니 backup이라는 폴더가 생긴것을 확인할 수 있다.

조금더 자세하게보니 Mounts 되었다는 정보와 어디에서 Volumes가 연겨되었는지 확인할 수 있다.
```
k exec -it nfspod -- bash
```
로 해서 안쪽으로 들어가 확인해보면 우리가 만든 파일이 있는 것을 확인해볼 수 있다.

????
그럼 이제 각 pod별 backup 폴더에 mysql 폴더의 데이터들을 tar.gz로 묶어서 저장할 수도 있고
s3와 연결해서 넣어놓을 수도 있다.
PV과 PVC
????
문제는 여기에서 끝내기에는 실재 사용자는 아직도 불편함을 느낀다는 것이다.
일반적인 볼륨
매번 개발자가 나에게 찾아와서 부탁하는것을 처리해주어야 했다.
PV, PVC 사용시 장점
퍼시스턴트 볼륨 리소스를 미리 생성하기 때문에 yaml 파일에 포드에 볼륨이 필요하다를 정의하기만 하면 된다.
PV를 쓴다면 관리자는 미리 PV를 만들어 pool에 놓으면 개발자는 pool에 요청을 해서 PV를 가져와 Pod에 자동으로 붙여준다.
실습2. PV & PVC를 이용한 볼륨 바인딩
1. 관리자(엔지니어)는 PV를 Pool에 담아둔다.
크기, 속성(read only, read write, 다중 접속 허용할 것인가?)
포드를 삭제하면 볼륨은 삭제되도록 할 것이냐? 아니면 보관할 것이냐?
1) Retain -> 포드가 삭제되더라도 볼륨은 남아있다.
2) Delete -> 포드와 함께 볼륨도 삭제된다.
PVC는 namespace 에 속한다. 반면 PV는 속하지 않는다.
????
각각 다른 namespace에서 storage에 PV를 요청하면 각 namespace에 맞추어서 PV가 마운트된다.

먼저 PV를 생성하는 과정을 살피어보자.
spec에 정의할것
1) 용량 - 1Giga
2) accessMode - ReadWriteMany(읽기 쓰기 동시접속) / ReadWriteOnce
3) 지울때의 모드 - PersistentVolumeReclaimPolicy(포드 삭제시 PV의 결과) : retain/delete
4) nfs/iscsi - 어디의 공간을 사용하는지
2. 개발자 또는 Pod 이용자는 PVC를 구성한다.
3. k8s는 개발자의 요구사항에 맞는 볼륨을 PV Pool에서 찾아 매칭되는 볼륨이 있다면 둘을 바인딩한다.
---
실습을 위해서 nfs server에 폴더를 만들고 권한을 주자


```
systemctl restart nfs-server
```
이제 마스터 노드로 가서 PV를 만들자
```
vi 04.test1pv.yaml
```
apiVersion: v1
kind: PersistentVolume
metadata:
name: test1-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
nfs:
path: /test1
server: 211.183.3.99
readOnly: false
만들어진 것을 확인해볼 수 있다.
이제 PVC가 필요하다.

PVC를 보면
storageClassName이라는 것이 존재한다. 이건 동적매핑 부분이다. 사용자가 요청하면 이 스토리지 클래스에 의해서 지정된 nfs에 가서 만드는 것이다.
지금 우리가 하는건 정적인 방식 즉 미리 준비해서 나중에 매핑해주는 방식이기 때문에 운영자에게 개발자가 연락을 주어야 한다.
PVC를 사용하면 요청에 대해 즉시 반응해서 만들어 줄 수 있다.
암튼 지금 당장 필요한게 아니니 잠시 비워두자
accessModes는 ReadWriteMany이다.
그리고 그 아래에 resources에 요청크기가 적혀있다.
이 PVC를 포드에 등록하면 포드가 생성되면서 매칭되는 볼륨과 함께 생성된다.
---
Pod를 생성하는데 Pod 생성 container의 이름을 nfs-mount-container이라고 했다.
볼륨 부분에는 PVC를 연결해주기만 하면 자동으로 볼륨이 존재시 연결해주게 된다.

배포 및 생성후의 상태를 보면 위와같이 나오게 될 것이다.

실습시작전에 공유 폴더에 test.txt 라는 파일을 미리 만들어놓자
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-nfs-pvc
spec:
storageClassName: ""
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: Pod
metadata:
name: nfs-mount-container
spec:
containers:
- name: nfs-mount-container
image: nginx
volumeMounts:
- name: nfs-volume
mountPath: /mnt
volumes:
- name: nfs-volume
persistentVolumeClaim:
claimName: my-nfs-pvc마스터 노드쪽에 nfs-pod-pvc.yaml이라는 파일을 만들어 배포했다.

결과 위와같이 나오면 충분하다.
보면 pv가 pvc와 연결되었다는 것을 STATUS를 통해 확인이 가능하다.

자세하게 정보를 보면 PVC를 이용해 연결되었다는 부분을 확인가능하다.
그럼 실재로 pod에 명령을 전달해보자

```
k exec nfs-mount-container -- mount | grep /mnt
```
마운트 정보를 확인가능하다.

마운트 된 곳에 있었을 test.txt 파일에 직접 들어가서( k exec -it nfs-mount-container -- bash) 내용을 넣어보자

그럼 스토리지에 해당 데이터가 작성된 것을 확인할 수 있다.
이 상태에서 다이나믹 프로비저닝을 해보자
위의 실습은 엔지니어가 미리 볼륨을 준비해 두어야 하는 정적 프로비저닝이다.
개발자가 필요한 PVC를 생성하면 해당 PVC의 내용을 읽고 볼륨을 제공하는 스토리지에 필요한 볼륨이 자동으로 생성되도록 하기 위한 설정이 필요하다. 이를 위해 동적 프로비저닝을 사용하고 지정된 PVC에게 볼륨을 제공하기 위하여 storage class를 사용해야 한다.

이게 쉽지 않은 이유는 징검다리 역활을 하는 pod가 필요해서 그렇다.
이거를 만드는데 에러가 정말 많이 난다.
10.5.1.147 이 NFS 서버이고 /cloud 디렉토리를 외부에 PV로 제공할 계획이다.

위와같이 개발자와 스토리지 사이에 NFS Provisioner가 필요하다. 개발자가 요청하면 NFS Provisioner가 이걸 해석하고 NFS Provisioner가 그걸 스토리지로 가서 볼륨을 만들고 개발자에게 제공해준다.
이걸 위해서는 Role이 필요하다. 볼륨을 만들고 관리하고 내용을 읽고 해석할 수 있는 계정이 필요하다.


yaml 파일을 확인해보면 ServiceAccount를 만들었다. 그리고 어떠한 역활을 주겠다는 rules 부분이 보인다.
이 rules들을 serviceAccount와 binding 해주는 것이다.
이렇게 하면 개발자는 pod 쪽에 요청을 보내면 pod 쪽에서는 PV와 PVC를 자유자제로 사용할 수 있는 계정(ServiceAccount)을 가지고 있다. 그래서 두개를 role binding 해주어서 pod에게 제공해주는 것이다.
그래서 맨 마지막에는 ClusterRoleBinding 이라는 부분이 있는 것을 확인할 수 있다.


위에서 보이는 ip 부분들은 10.5.1.147 로 바꾸어놓고 제공해주자
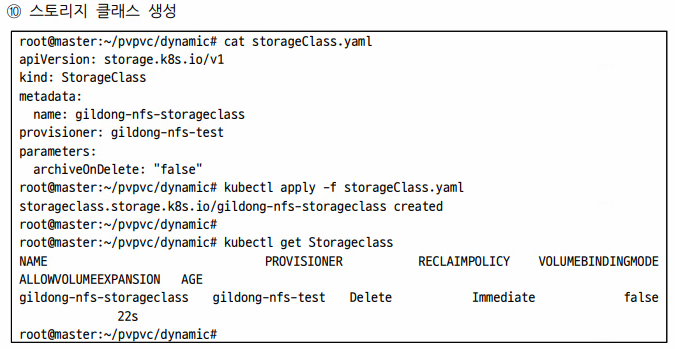
그리고 스토리지 클래스도 생성해주자.
여기에서 스토리지 클래스는 NFS 서버와 연결되어 있어서 스토리지로부터 저장공간을 끌고 올 수 있는 스토리지 클래스이다.

pvc라는 것이 있다. pvc는 요청이다. 개발자가 하는 부분이다. 요청 내용을 보면 storageClassName이 존재한다.
어떤 provisioner 에게 요청할 것인가. 이건 앞서 보았던 10.5.1.147 밑에 있는 /cloud를 끌어다가 사용할 수 있는 PV를 지정해보고 이걸 storageClassName 에 연결하겠다는 의미이다.
그리고 그 밑으로 요청 내용들이 보인다.
pvc를 생성하여 자동으로 스토리지 클래스를 통해 pv와 바인딩 여부 확인한다.

배포 결과를 확인해볼 수 있다.


pv를 사용할 수 있는 포드 배포하자
만든 pod의 /gildongvol이라는 곳에 volume을 갖다 붙이겠다는 것이다.
---
여기에서 스토리를 정리해보자
개발자는

1G 볼륨 필요해 -> 정적 -> 엔지니어 -> 준비된 PV를 개발자가 PVC로 끌어다 쓸 수 있다.

그런데 이런경우는 어떻게 해야할까? 스토리지는 있는데 엔지니어가 퇴근한 상황이다. 그러면 엔지니어가 밤에 나올 수 없다. 매번 나올수도 없고 말이다. 그래서 스토리지 중간에 이걸 관리하는 pod를 만들고 pvc가 들어오면 스토리지에서 pv를 만들 수 있는 기능이 있는 것이다. ServiceAccount(계정)에게 role을 부여하여서 PV, PVC, StorageClass도 다 쓸 수 있다.
요청이 들어오면 NFS 서버에 가서 필요한 볼륨을 만들어낼 수 있다는 것이다. 바로 이 부분에서 스토리지 엔지니어가 작업을 하게 되는 것이다. 그리고 개발자는 storageClass를 통해서 중간 매개자 Pod를 설정만 해주면 되는 것이다.

마지막으로 포드에서 연결된 볼륨 사용가능 여부를 체크해주면 된다.
---
실습 드가자
많이 어렵고 힘들다 잘 따라와야 한다.
```
vi /etc/kubernetes/manifests/kube-apiserver.yaml
```

내부로 들어가서 - kube-apiserver 아랫 부분에
`--feature-gates=RemoveSelfLink=false` 를 추가해주자
nfs 서버 재시작
2. NFS Provisioner 포드가 PV를 배포할 수 있는 Role 생성하고 사용할 수 있는 Service Account 생성
```
mkdir dynamic
cd dynamic
vi sa.yaml
```
kind: ServiceAccount
apiVersion: v1
metadata:
name: nfs-pod-provisioner-sa
---
kind: ClusterRole # Role of kubernetes
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-provisioner-clusterRole
rules:
- apiGroups: [""] # rules on persistentvolumes
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-provisioner-rolebinding
subjects:
- kind: ServiceAccount
name: nfs-pod-provisioner-sa
namespace: default
roleRef: # binding cluster role to service account
kind: ClusterRole
name: nfs-provisioner-clusterRole # name defined in clusterRole
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-pod-provisioner-otherRoles
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-pod-provisioner-otherRoles
subjects:
- kind: ServiceAccount
name: nfs-pod-provisioner-sa # same as top of the file
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: Role
name: nfs-pod-provisioner-otherRoles
apiGroup: rbac.authorization.k8s.io
3. NFS 서버를 동적 프로비저닝으로 사용할 수 있는 도구인 Provisioner Pod 배포
```
vi provisioner.yaml
```
kind: Deployment
apiVersion: apps/v1
metadata:
name: nfs-pod-provisioner
spec:
selector:
matchLabels:
app: nfs-pod-provisioner
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: nfs-pod-provisioner
spec:
serviceAccountName: nfs-pod-provisioner-sa # name of service account
containers:
- name: nfs-pod-provisioner
image: quay.io/external_storage/nfs-client-provisioner:latest
volumeMounts:
- name: nfs-provisioner
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME # do not change
value: gildong-nfs-test # SAME AS PROVISIONER NAME VALUE IN STORAGECLASS
- name: NFS_SERVER # do not change
value: 10.5.1.147 # Ip of the NFS SERVER
- name: NFS_PATH # do not change
value: /cloud # path to nfs directory setup
volumes:
- name: nfs-provisioner # same as volumemouts name
nfs:
server: 10.5.1.147
path: /cloud

4. 스토리지 클래스 생성
```
vi storageCalss.yaml
```
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: gildong-nfs-storageclass
provisioner: gildong-nfs-test
parameters:
archiveOnDelete: "false"

5. pvc 생성하여 자동으로 스토리지 클래스를 통해 pv 와 바인딩 여부 확인
```
vi pvc.yaml
```
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: tonyhan-pvc-nfs-dynamic
spec:
storageClassName: gildong-nfs-storageclass # SAME NAME AS THE STORAGECLASS
accessModes:
- ReadWriteMany # must be the same as PersistentVolume
resources:
requests:
storage: 1Gi
정상적으로 바인드된것을 확인해볼 수 있다.

이제 storage쪽으로 가서 내가 요청한 pv가 생성되었는지 확인해보니 정상 생성된 것을 확인해볼 수 있었다.
6. PV 를 사용할 수 있는 포드 배포하기
```
vi deployment.yaml
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: gildong-deployment
labels:
app: gildong-nginx
spec:
replicas: 3
selector:
matchLabels:
app: gildong-pod
template:
metadata:
labels:
app: gildong-pod
spec:
containers:
- name: gildong-nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- mountPath: /gildongvol
name: gildong-volume
volumes:
- name: gildong-volume
persistentVolumeClaim:
claimName: gildong-pvc-nfs-dynamic

정상생성되어서 연결된 모습을 확인해볼 수 있다.
7. 생성된 포드에서 연결된 볼륨 사용가능 여부 확인

이제 nfs 서버에 가서 우리가 만들었던 스토리지 내부에 파일을 만들고 나와보자
생성한 포드에 접근하여 디렉토리를 직접확인해보자

파일이 있는 것을 확인해볼 수 있었다.
위의 실습은 엔지니어가 미리 볼륨을 준비해 두어야 하는 정적 프로비저닝이다.
개발자가 필요한 PVC 를 생성하면 해당 PVC 의 내용을 읽고 볼륨을 제공하는 스토리지에 필요한 볼륨이 자동으로 생성되도록 하기 위한 설정이 필요하다. 이를 위해 동적 프로비지닝을 사용하고 지정된 PVC 에게 볼륨을 제공하기 위하여 storage class 를 사용해야 한다.
???? <- 안들었음
ServiceAccount와 RBAC(Role Based Access Control)
Role, ClusterRole, RoleBinding, ClusterRoleBinding
지금까지 우리는 kube-admin 계정으로 모든 명령을 실행했다. 이는 쿠버네티스 전체를 관리할 수 있는 최고 관리자이다.
하지만 우리회사에 서비스를 요청한 고객사나 중간관리자, 관리직원들은 쿠버네티스의 모든 명령을 실행할 수 없어야 한다.
고객사와 관리팀장, 관리직원별로 권한을 다르게 부여해야만 한다. 그래서 해야하는 것이 Role, ClusterRole, RoleBinding, ClusterRoleBinding와 같은 것들이다.

role과 같은 경우 namespace에 속하기 때문에 회사별로 부여해주면 된다.
rules 안에 할 수 있는 기능들을 부여해주었다.
apiGroups는 대상이 될 오브젝트의 API 그룹은 비워두었는데 이건 api 그룹에 대해서는 확인 안하겠다는 의미이다.
대신에 services만 건드릴 수 있다.
그런데 또 뒤에 명령어들이 보인다. get과 list이다. 이것만 사용할 수 있다는 의미이다.
kubectl get svc
verbs object
list
get -> 각각의 오브젝트를 확인
list -> api-resources를 확인가능하도록 만들어준다.
kubectl api-resources
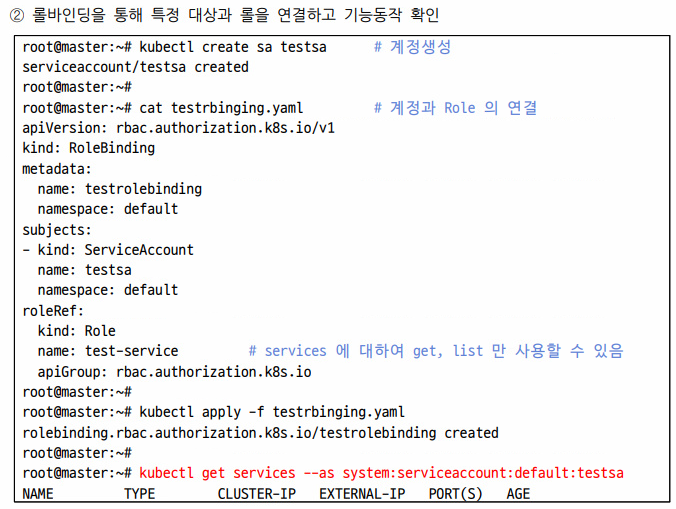

이렇게 만든 규칙을 testsa에게 binding 해주자.
RoleBinding을 보면
Role: testsa에 대하여 Role(test-service)라는 이름으로 role의 api rbac...에 넣어주었다.
그리고 실재로 사용할 수 있는 것을 확인해보니
k get services는 되는데
k get deploy는 막힌것을 확인할 수 있었다.

그 다음의 ClusterRole(네임스페이스에 종속되지 않는 오브젝트들이다)
대표적으로 node가 있다. node도 네임스페이스에 속하지 않은 놈들이고 pv, namespace도 네임스페이스에 속하지 않은 놈들이다.
그리고 verbs를 보면 앞에서와 쓰는 방법이 다른것을 확인해볼 수 있다. 두가지 방법이 존재한다.

롤 바인딩을 해보니 node에 대해서는 확인이 가능했다.

그런데 pv에 대해서는 허용되지 않은 모습을 볼 수 있었다.
---
RBAC를 실재로 한번 해보자
```
k create sa user1
vi user1role.yaml
k apply -f user1role.yaml
```

kind: Role
metadata:
name: user1role
rules:
- apiGroups: [""]
resources: ["services"]
verbs: ["get", "list"]```
vi user1rolebinding.yaml
k apply -f user1rolebinding.yaml
```
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: user1rolebinding
namespace: default
subjects:
- kind: ServiceAccount
name: user1
roleRef:
kind: Role
name: user1role
apiGroup: rbac.authorization.k8s.io```
k get svc --as system:serviceaccount:default:user1 # 사용가능
k get pod --as system:serviceaccount:default:user1 # 사용불가
```


사전에 namespace까지 지정해주면 더욱 좋아질 수 있을 것이다.
'Development(Web, Server, Cloud) > 22) LINUX - Cloud' 카테고리의 다른 글
| 클라우드 66일차(k8s-labeling, ansible, jenkins) (0) | 2022.04.27 |
|---|---|
| 클라우드 65일차(정리중, autoscale, jenkins) (0) | 2022.04.26 |
| 클라우드 63일차(정리중, ingress, 정리중) (0) | 2022.04.22 |
| 클라우드 62일 (0) | 2022.04.22 |
| 클라우드 61일(kubernetes 개념, pod, Deployment, Metal LB, autoscaler, web-ui) (0) | 2022.04.15 |



