usecase1
우리회사가 포털, 규모가 큰 쇼핑몰, 대기업 이라면 Pod 의 개수가 많을 것이다. 이 경우에는 ingress 적용하여 아래와 같이 컨턴츠 별로 별도의 포드를 운영하는 방법을 고민해 볼 필요가 있다.
http://www.test.com
http://www.test.com/shirt
http://www.test.com/client
MSA -> 일반적으로 컨테이너를 활용하여 개발에 들어가고 과거 폭포수 모델에 비해 개발 속도가 빠르다(동시 개발을 할 수 있다),
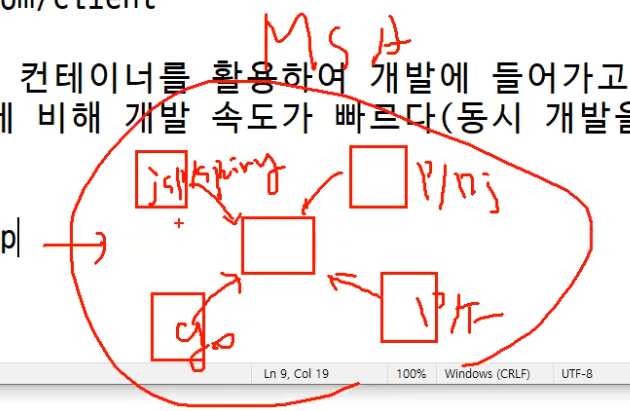
예전과 다르게 각자의 개발은 서로에게 영향이 미치지 않게 할 수 있다. MSA 환경에서는 서로에게 영향을 미치지도 않고 한 서비스가 영향을 미치면 그 부분만 고치면 되는 것이다. 그래서 구지 같은 언어로만 개발할 필요가 없어졌다.
ingress msa 를 이용하여 각각의 서비스 페이지를 연결하는 방식으로 서비스를 제공한다.
usecase 2.
우리회사는 스마트폰과 연계하여 각 사용자별로 별도의 애플리케이션을 제공하고 해당 애플리케이션 내에서 게임이 이루어지도록 구성한다.
min max
www.test.pri (main) -> Deploy(5 Pod) 5 20
www.test.pri/blog -> Deploy(2 Pod) 2 10
www.test.pri/shop -> Deploy(10 Pod) 10 50
각각의 deploy 갯수를 다르게 할 수 있다.
외부로 접속하는 사람들이 각각의 페이지에 맞추어 들어갈때 pod가 사용자 트래픽을 감당못할 수준이 되는 순간이 올 것이다. 그럴때 pod의 갯수를 늘리자는 것이다.
포드의 개수를 자동으로 scale out 시킬 수 있는 기술(autoscale)을 적용하여 포드의 유연한 수평적 확장을 구성할 수 있다.
이때 기준이 되는 값은 cpu-ram 사용량을 가지고 할 수 있다. 만약 사용량이 80%를 넘지 않았다면 그대로 포드를 사용하고 그게 아니라면 추가 포드를 만들어준다.
위와 같은 구성이라면 각 Deploy 별로 resource 의 사용량을 정하고 max, min Pod 의 개수를 지정할 수 있다.
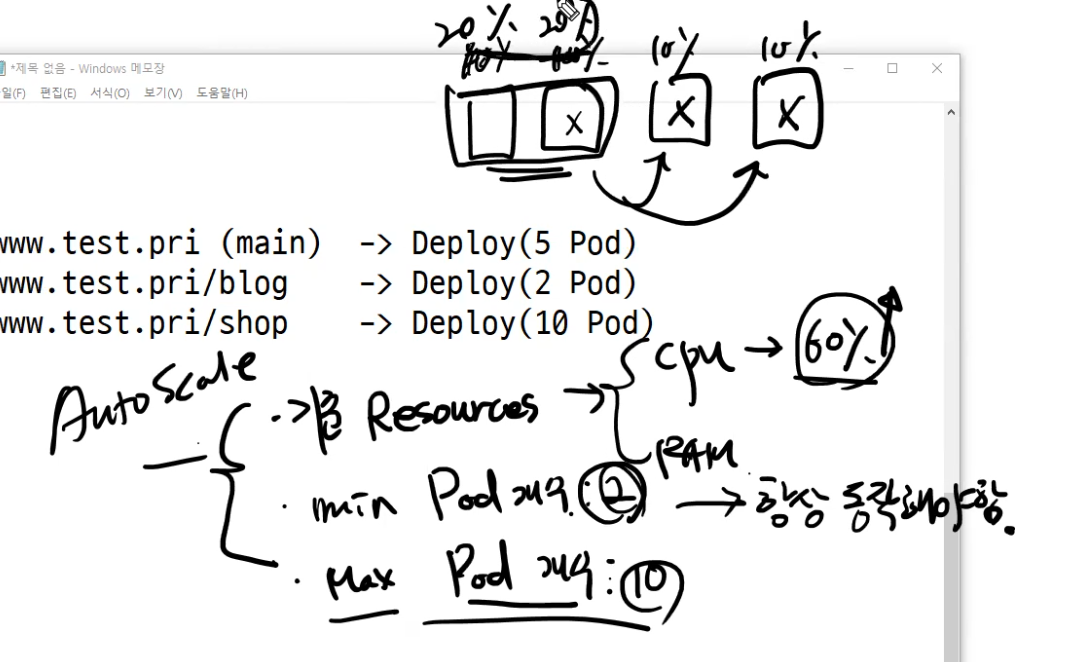
AutoScale을 할때는
1. 기준 Resources - cpu/ram
2. min pod 갯수 - 항상동작
3. max pod 갯수 - 최대갯수
---
먼저 이전에 했었던 shopingress.yaml과 deploysvc.yaml을 복사해오자

이제 구조는 이렇게 된다.
ingress를 적용하면 자동으로 맨 앞쪽에 ingress용 LB(Load Balancer)가 배치된다.
그 다음은 ingress-controller가 배치된다.
우리는 이 ingress-controller를 선택할때 nginx를 선택했다. ingress-controller는 ingress 정책에 따라서 누구에게 보낼지를 결정한다.
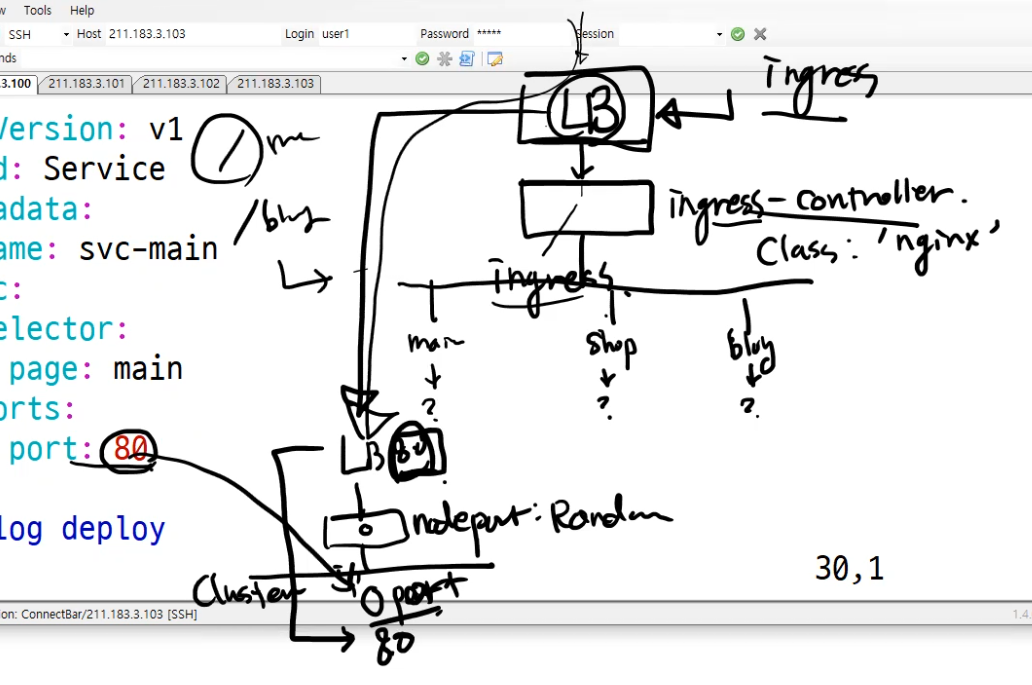
그런데 이걸 크게 보면 LB는 단순히 NodePort로 들어가서 Cluster 안에 있는 서비스로 연결해준 것이다.
우리가 지금까지 배포한것들은 모두 도커허브에서 이미지를 다운로드하여 포드내 컨테이너로 배포한것이다.
-> 각 노드에서 이미지를 다운로드 하는데 도커 허브에 인증한적이 없다. 그런데 어떻게 다운로드 받을 수 있었을까?
-> 도커 허브에 접속하기 위해서는 계정을 이용한 로그인이 필요하다! 도커 로그인은 master에서만 했다. 노드는??
docker service create .... nginx --with-registry-auth 한적이 있다. 이렇게하면 master에서 로그인한 정보가 노드들에게도 전달된다.
그렇다면 사설 저장소 registry.test.com:5000을 우리 팀이 사용하고 있다면 어떻게 이미지를 다운로드하여 컨테이너를 생성할 수 있을까?
사설 저장소: private-registry 를 이용하여 사설 저장소를 사용한다면? 사용자 username, 사용자 password, 이메일, 서버의 주소가 필요하다.
도커허브내에 public 저장소가 아니라 사설 저장소(무료 1개)를 생성했다면 이 사설 저장소로의 접속은 반드시 username, password, (option) email 정보가 필요하다.
* pull 하려는 이미지의 이름이 gildong/test:1.0 (도커 허브)
* 일반 사설 저장소 registry.test.com:5000/test:1.0 (사설 저장소)
1) secret 를 만든다. 만들때 username, password, server, email(옵션) 정보를 포함하여 만든다.
2) 만들어진 secret 을 deploy 내의 container 정보에 포함시켜 디플로이먼트를 배포한다.
3) 배포시 Deploy(컨테이너)에 포함된 정보를 확인하여 지정된 저장소에 이미지를 다운로드하여 포드를 배포할 수 있다.
사설 저장소 접속 예)
kubectl create secret generic registrykey -> 은 어제 SA 만들떄 쓴거고
kubectl create secret docker-registry registrykey \
--docker-username=user1 --docker-password=test123 \
--docker-server=registry.test.com:5000
사설 저장소 배포시
Deployment 작성
apiVersion: apps/v1
kind: Deployment
...
spec:
containers:
- name: testpod
image: registry.test.com:5000/test:1.0
imagePullSecrets:
- name: registrykey
일반적으로 사설 저장소에 있는 이미지를 다운로드 하기 위해서는 사용자 정보(username, password)와 더불어 인증서를 발급받아야 한다.
https://...
우리가 만들었던 사설 저장소는 사용자 정보를 요구하여 접속하는 형태는 아니였고 인증서가 필요는 했었다. 하지만 인증서 발급없이 http로 접속했다. 이유는? 인증서를 통합 접속이 아니었기 때문이다. -> insecure-mode 였으므로
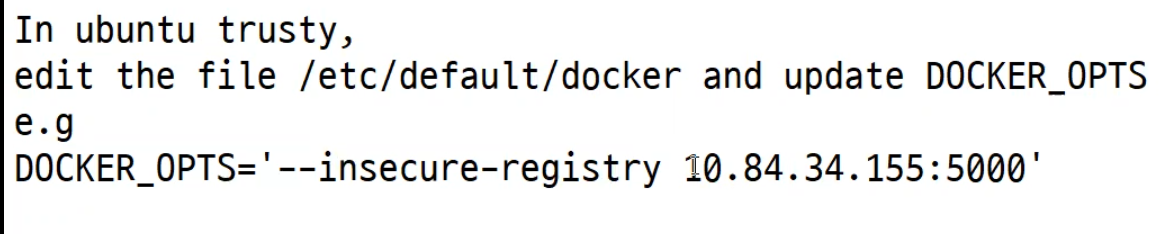
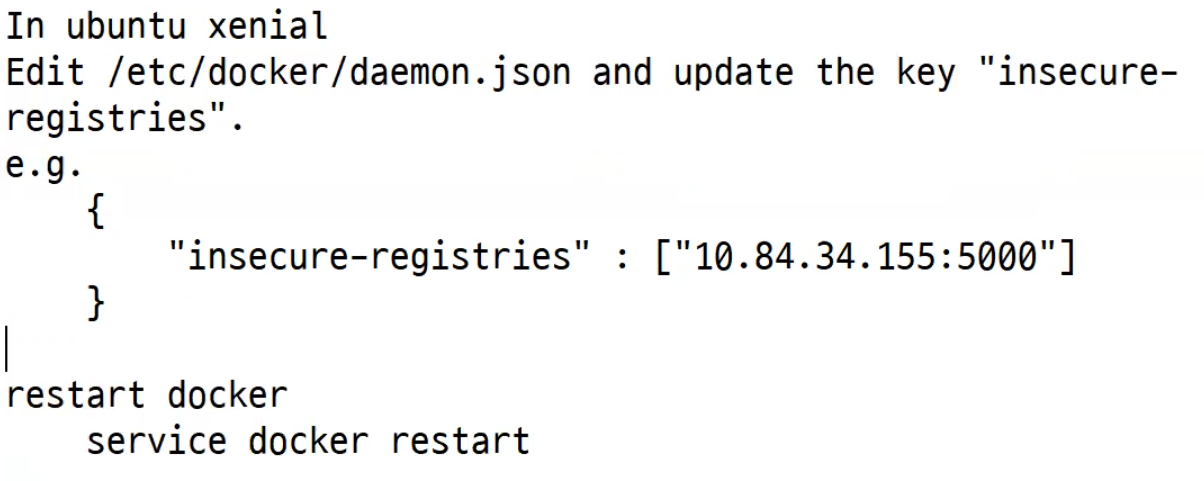
대충 이런 물건을 써왔기 때문에 가능했었던 것이다.
그런데 만약이 이걸 안해놓았다면?
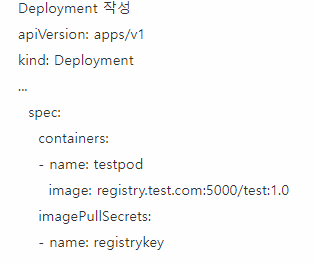
위의 방식으로 PullSecrets 하는 과정이 필요하다.
도커에 로그인하여 이미지를 다운받고 싶다면?
1. secret을 만들어서 포드에 추가하는 방법
2.
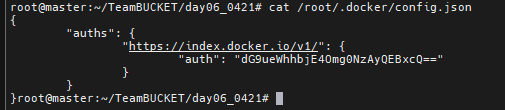
직접 작성하는 방법. master에서 도커 로그인을 한번 하고 docker service create 할때 --with-registry-auth를 적용하여 master의 인증정보를 노드에게 모두 전달하게 되면 각 노드의 /root/.docker 아래에 config.json 파일이 생성된다.
3. secret을 만들때 username, password를 직접 입력하여 만드는 것이 아니라, master에서 로그인한 config.json 파일을 불러와서 만드는 방법을 이용할 수 있다.
---
# 메인페이지용 코드
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-main
spec:
replicas: 1
selector:
matchLabels:
page: main
template:
metadata:
name: pod-main
labels:
page: main
spec:
containers:
- name: ctn-main
image: nginx
ports:
- containerPort: 80
---
# 메인페이지용 서비스
apiVersion: v1
kind: Service
metadata:
name: svc-main
spec:
selector:
page: main
ports:
- port: 80
---
# blog 용 코드
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-blog
spec:
replicas: 1
selector:
matchLabels:
page: blog
template:
metadata:
name: pod-blog
labels:
page: blog
spec:
containers:
- name: ctn-blog
image: tonyhan18/testweb:blue
ports:
- containerPort: 80
---
# blog 용 서비스
apiVersion: v1
kind: Service
metadata:
name: svc-blog
spec:
selector:
page: blog
ports:
- port: 80
---
# shop 용 코드
apiVersion: apps/v1
kind: Deployment
metadata:
name: pod-shop
spec:
replicas: 1
selector:
matchLabels:
page: shop
template:
metadata:
name: pod-shop
labels:
page: shop
spec:
containers:
- name: ctn-shop
image: tonyhan18/testweb:green
ports:
- containerPort: 80
---
# shop 용 서비스
apiVersion: v1
kind: Service
metadata:
name: svc-shop
spec:
selector:
page: shop
ports:
- port: 80먼저 deployment 파일을 위와 같이 작성해준다.
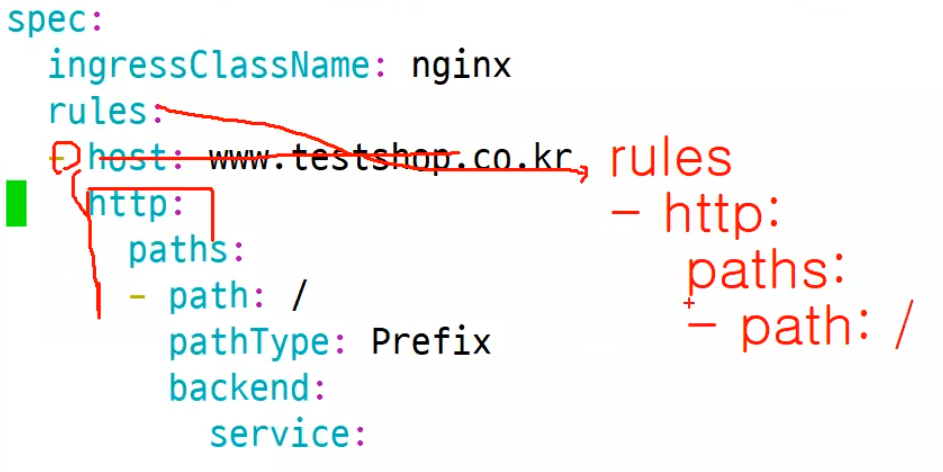
ingress를 위와같이 작성해주되 만약에 ip 밖에 없다면 발간 부분처럼 작성해주면 된다.
하지만 우리는 이미 도메인을 가지고 있기 때문에 기존 파일을 가지고 배포를 해보자
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-testshop
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
ingressClassName: nginx
rules:
- host: www.testshop.co.kr
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: svc-main
port:
number: 80
- path: /blog
pathType: Prefix
backend:
service:
name: svc-blog
port:
number: 80
- path: /shop
pathType: Prefix
backend:
service:
name: svc-shop
port:
number: 80준비가 되었다면 배포를 해보자
[실습1] ingress/deploy 배포하기

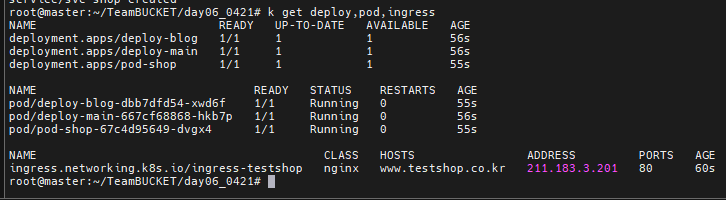
배포후 상태를 보니 정상 배포된것을 볼 수 있다.
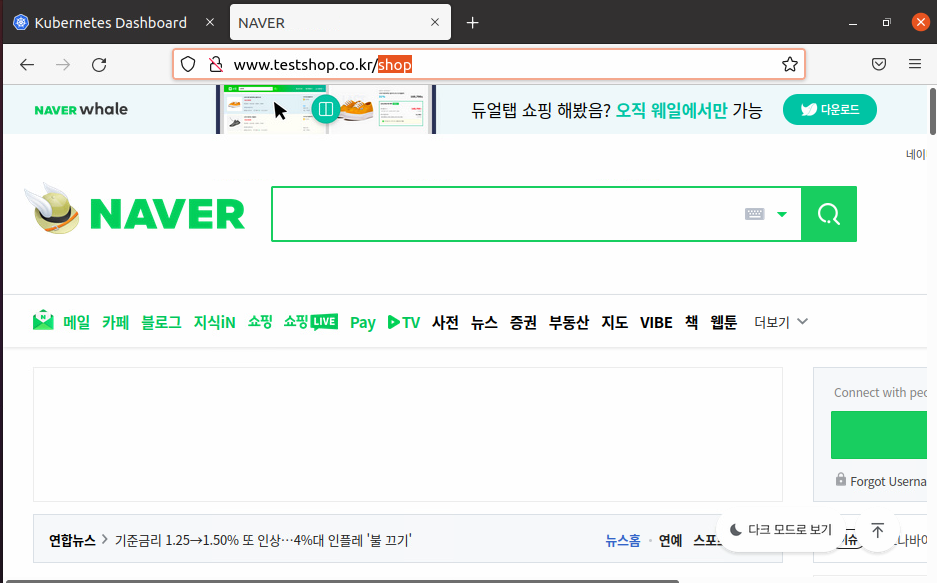
하지만 지금 배포된것은 진짜가 아니기 때문에 /etc/hosts에 ip 와 도메인이 매핑되어 있어야 한다.
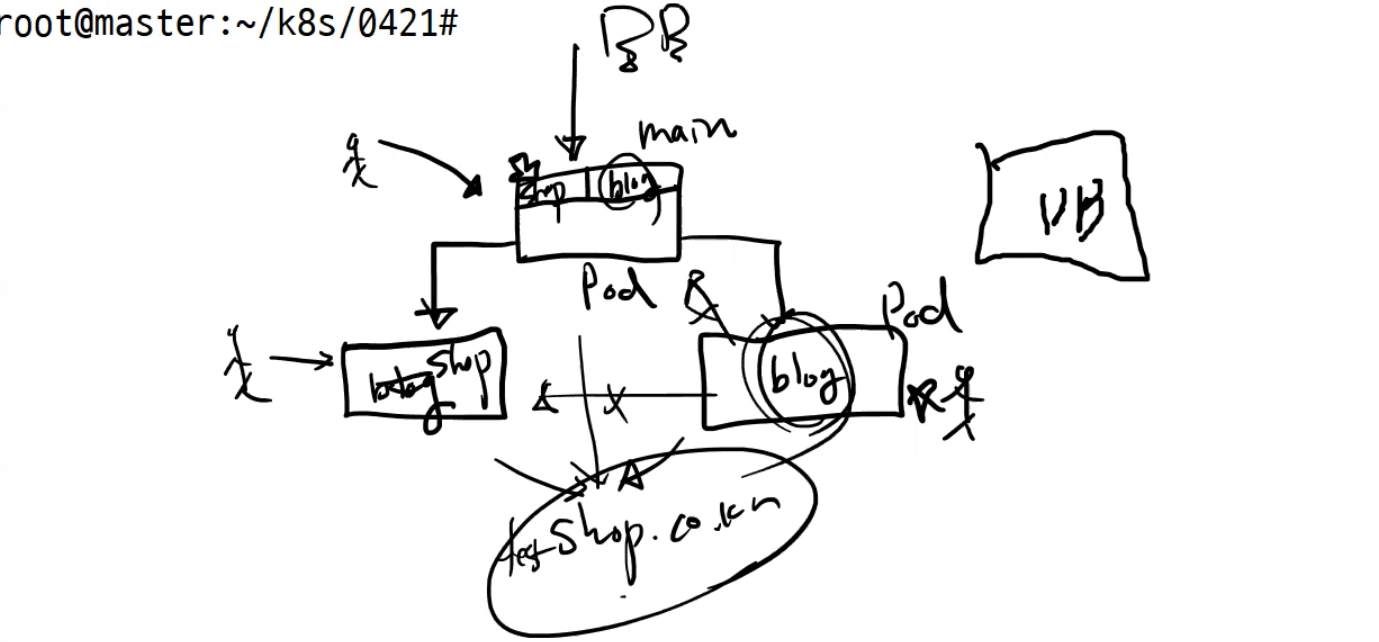
현재상황은 사용자가 접속하면 루트 pod를 기준으로 shop, blog가 각자의 pod에 접속해서 개발중인 것이다. 그래서 상호 신경쓸 필요가 없다.
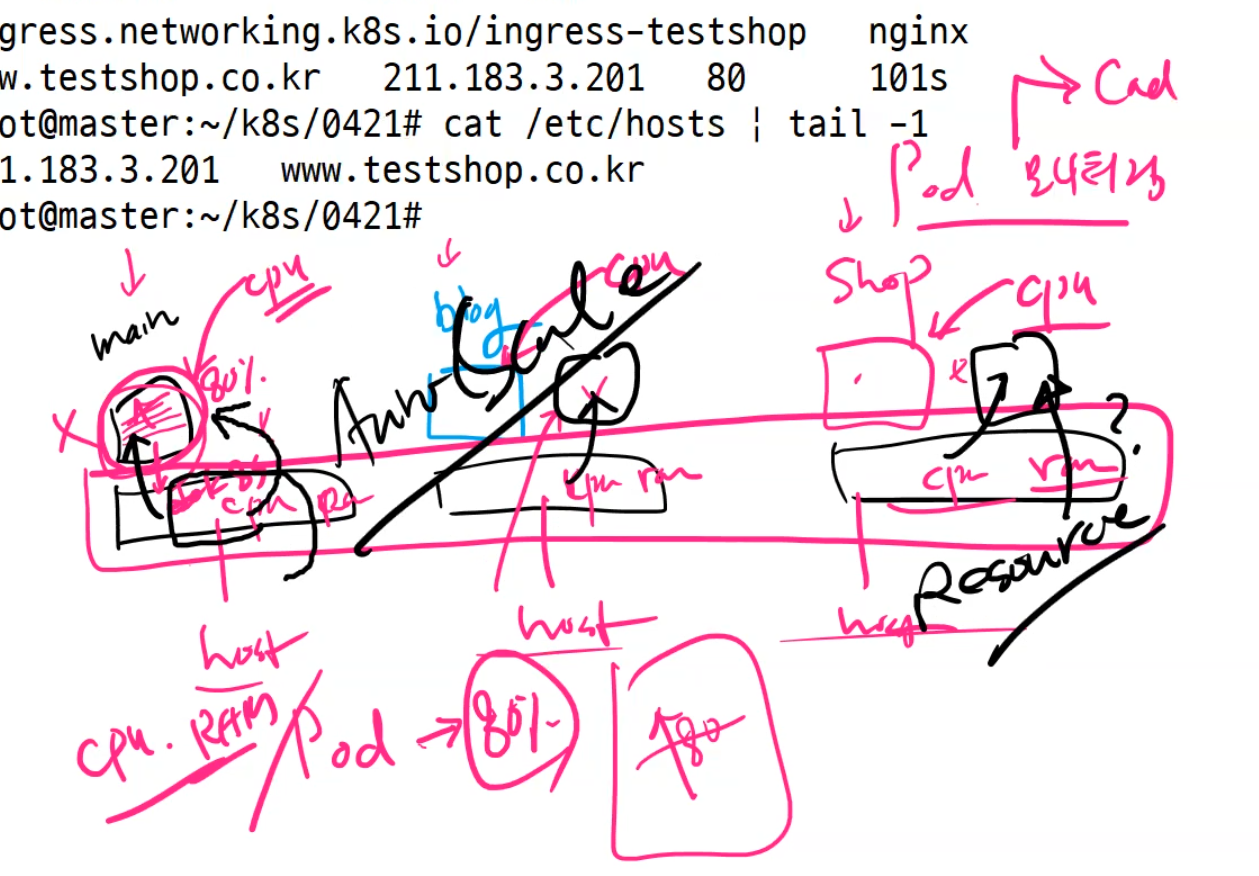
나중에 모니터링을 한다면 Node의 cpu, ram 사용량을 볼것이다. 이때 보는 것이 pod 뿐만 아니라 node까지도 봐야한다. 그럼 이걸 가지고 cpu, ram의 사용량을 미리 정의해놓을 수도 있다. 그래서 이 사용량을 넘기면 pod를 더 생성하게 만들수도 있다. 이것을 보고 AutoScale이라고 부른다. 여기에서 중요한것은 우리가 얼마만큼 이걸 지정할 것인가 이다.

동작중인 상태에서 서버를 하나 추가하면 서버의 자원을 pool에 추가하기 위해서 클러스터에 가입만 하면 되기 때문에 수평확장이 가능하다.

각 포드별로 자원사용량을 제한하기 위해서 deployment에 위의 명령을 넣어주면 된다.
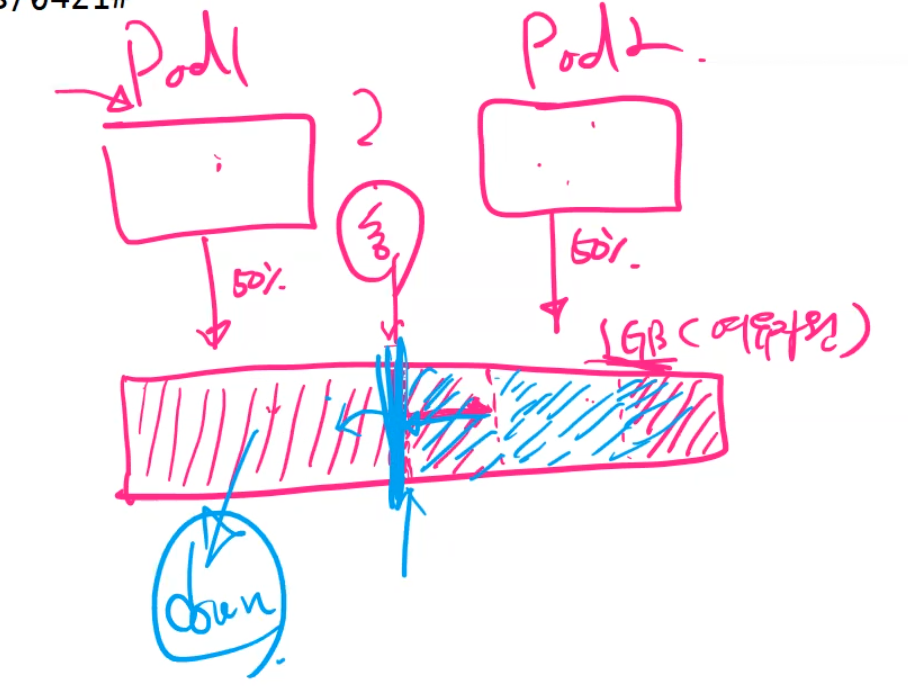
그리고 autoscale을 이용하면 pod 사용 제한량을 동적으로 조절해주면 된다. 그런데 어쩌다보니 다른 pod2 도 사용량이 늘게 되면 결국 pod1은 어쩔 수 없이 꺼지게 된다.
그래서 평소에 이것의 사용량을 체크해 놓는것이 중요하다.
이걸 위해 최대 얼마까지 사용가능한지 체크해 놓는 기능이 필요하다. 이걸 보고 `벌루링`이라고 부른다.

포드안에 들어가는 컨테이너 별로 제한을 둘 수 있다.
1000m === cpus 1과 동일하다.
256Mi === ram 256mb

리소스의 제한은 두가지로 구분된다.
1. Requests - 1. limit: 다른 pod에 여유자원 있을때 내 Pod에서 확장할 수 있는 범위/ 2. request: 최소보장
2. Overcommit - 최대 받을 수 있는 자원 사용률

전체 자원보다 더 많은 양을 할당하는 오버커밋
하지만 최소양인 250MB를 넘지는 못한다.

그래서 실재코드를 보면 최대인 resources와 최소인 requests가 존재한다.
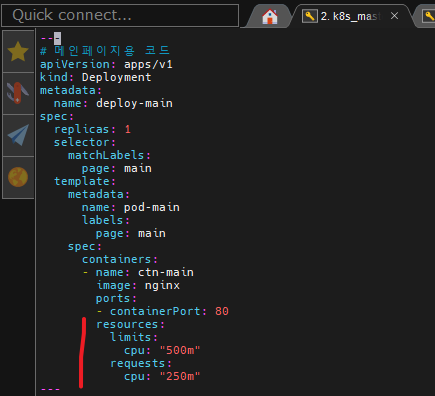
그래서 보는 바와 같이 deploy-main은 위와같이 자원할당을 해주었다.
---
# 메인페이지용 코드
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-main
spec:
replicas: 1
selector:
matchLabels:
page: main
template:
metadata:
name: pod-main
labels:
page: main
spec:
containers:
- name: ctn-main
image: nginx
ports:
- containerPort: 80
resources:
limits:
cpu: "750m"
requests:
cpu: "250m"
---
# 메인페이지용 서비스
apiVersion: v1
kind: Service
metadata:
name: svc-main
spec:
selector:
page: main
ports:
- port: 80
---
# blog 용 코드
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-blog
spec:
replicas: 1
selector:
matchLabels:
page: blog
template:
metadata:
name: pod-blog
labels:
page: blog
spec:
containers:
- name: ctn-blog
image: tonyhan18/testweb:blue
ports:
- containerPort: 80
resources:
limits:
cpu: "250m"
requests:
cpu: "150m"
---
# blog 용 서비스
apiVersion: v1
kind: Service
metadata:
name: svc-blog
spec:
selector:
page: blog
ports:
- port: 80
---
# shop 용 코드
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-shop
spec:
replicas: 1
selector:
matchLabels:
page: shop
template:
metadata:
name: pod-shop
labels:
page: shop
spec:
containers:
- name: ctn-shop
image: tonyhan18/testweb:green
ports:
- containerPort: 80
resources:
limits:
cpu: "500m"
requests:
cpu: "250m"
---
# shop 용 서비스
apiVersion: v1
kind: Service
metadata:
name: svc-shop
spec:
selector:
page: shop
ports:
- port: 80
이 상태로 배포해보자. 정상 배포되었다.
멱등성이라는 말이 존재한다. 멱등성은 연산을 여러 번 적용하더라도 결과가 달라지지 않는 성질을 이야기한다.
cloud native 환경에서의 멱등성은 특정 결과값을 보장받아야 한다.
예를 들어 기존의 httpd가 설치되어 있는 상태에서 다시한번 yum -y install httpd를 하면 재 설치를 시도하게 될 것이다. 이는 불필요한 작업이다. 클라우드 네이티브에서 막하는 멱등성이 적용된다면 설치되어 있는 상태를 보장 받아야 하는데, 이미 설치가 되어 있는 상태이므로 재설치를 하지 않게 된다. == "설치가 되어 있는 상태가 되어야 한다"
이 이야기를 왜 했는가 배포한걸 보면 unchanged라는 게 있다. 즉 멱등성이 보장된 것이라고 볼 수 있다.
IaC(Infrastructure as a Code)
기존 레거시 인프라 환경의 관리는 각각의 서버, 네트워크 장치등을 직접 일일이 설정하고 변경사항을 구성해야하는 복잡하고 단순작업의 연속이었으나 IaC 도구를 활용하면서 스크립트 등을 도입하여 자동화된 관리 및 인프라 구성 및 변경등이 가능하게 되었다. -> Ansible, Terraform, Puppet
예를들어 Ansible은 특정 패키지를 시작할 때 start라는 단어를 사용하지 않는다. started를 사용한다. 즉, "시작된 상태를 보장하라"라는 뜻을 이용하여 다수의 서버등에서 데몬이 동작중인 상태에서 다시한번 start를 하는 불필요한 작업을 줄이고 상태 확인을 먼저 거쳐 리소스의 사용률을 높일 수 있게 되었다. stop도 stop으로 작성하지 않고 stopped로 작성한다.
`top` 을 해보면 자신의 cpu, ram 사용량을 볼 수 있다.
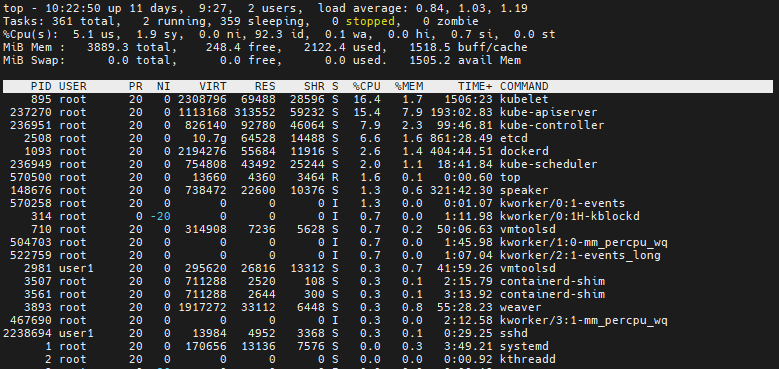
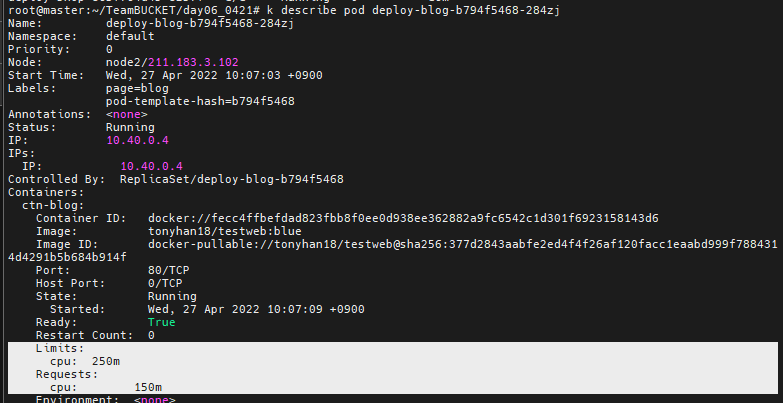
포드 하나를 까보니 cpu의 사용량이 적혀있는 것을 볼 수 있다.
추가적으로 정적 PV, PVC를 이용하여 각 포드에 /backup 디렉토리를 PV와 연결해 두자. 나중에 포드에 발생하는 특정 정보를 PV에 백업할 수 있도록 하기 위함.
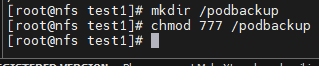
먼저 자신의 nfs 서버에 위와같이 podbackup 폴더를 만들어주자
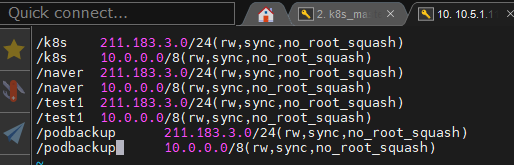
그리고 /etc/exports에 폴더를 추가해놓자
이건 각 포드에 백업용으로 사용하기 위한 폴더이다.
이제 마스터에서 필요한 작업을 해주자.
(node1 ~ node3은 미리 nfs-common을 설치해 두어야 한다)
```
vi pv.yaml
```
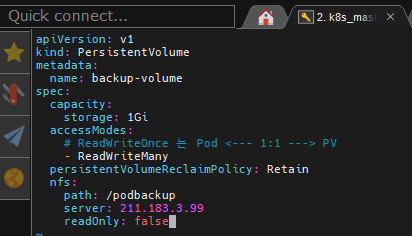
apiVersion: v1
kind: PersistentVolume
metadata:
name: backup-volume
spec:
capacity:
storage: 1Gi
accessModes:
# ReadWriteOnce 는 Pod <--- 1:1 ---> PV
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
nfs:
path: /podbackup
server: 211.183.3.99
readOnly: false이 방식으로 PV를 하나 만들어놓자
PVC도 필요하다. 만들어주자
```
vi 04.pvc.yaml
```
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pod-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi컨테이너 구성시 pvc를 정의하고 해당 PVC를 pod에 연결하여 포드 생성시 해당 PVC에 대응하는 PV를 어느 디렉토리에 마운트 할 것인가를 결정해야 한다.

상태가 Bound 상태인것을 확인할 수 있다. 이걸 가지고 pod에 연결만 해주면 된다.
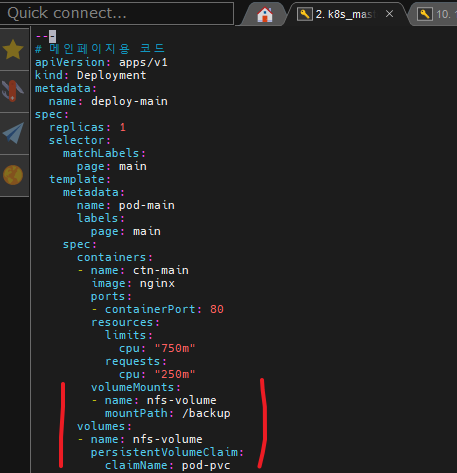
그리고 위와같이 모든 deploy에 volume을 연결해주자

이 상태에서 nfs 노드의 podbackup 폴더 안에 test.txt 를 만들어놓자

그러면 deploy 된 pod의 backup 폴더 안에 test.txt 파일이 있는 것을 확인해볼 수 있다.
---
Auto Scaling
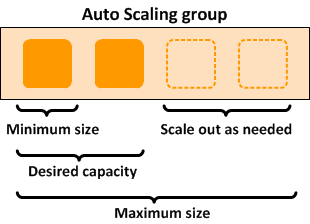
지정된 CPU 상태를 넘어서게 되면 추가적으로 Pod를 늘려가도록 설정 최소(처음에 배포했던 숫자를 지정하면 된다 = 1), 최대
Pod에 지정한 CPU 상태를 넘어서게 되면 추가적(자동으로)으로 늘려가나는 방법. 평균값을 계산해서 유지한다. 일단 생성된거는 최소 3분은 유지시킨다.
scale은 크게 두가지가 존재한다.
1. scale up -> 서버 한대를 두고 지정된 양보다 트래픽이 몰리면 스펙을 높이겠다.
2. scale out -> 수평적으로 동일 포드/인스턴스를 늘려가는 방식(일반적인 autoscale의 방식)
나중에 나오는 ecs를 이용한 auto scale도 이러한 방식으로 움직이게 된다.
AMI서비스를 이용해 이미지를 가져오고 인스턴스의 갯수를 조절하게 된다.
AMI(glance) = registry
- AMI(glance) : 인스턴스를 만들기 위한 이미지 저장소. 여기에 computing+storage 자원을 붙이는 것이다(cpu, ram)
- registry : 컨테이너를 만들기 위한 이미지 저장소
Block Storage도 local과 remote로 나뉘게 되는데 container에 local storage를 연결하는건 좋은 방법이 아니다.
어떤 방법을 사용하던 external 볼륨을 사용해야 한다. 이러한 볼륨을 persistent volume이라고 부른다. 영구디스크/영구스토리지라고 부른다.
이러한 것을 aws에서는 ecs로 관리할 수 있게 된다.
우리가 원하는 이미지를 만들기 위해서도 base Image를 가져다가 httpd, index 등등을 통해 NewImage를 만들어 사설 AMI에 올리면 된다.
그러면 최소 사이즈와 scale out 된 사이즈가 결정되게 된다.
```
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
```
먼저 github에서 auto scaler를 구성하기 위한 파일을 다운 받아보자
```
vi components.yaml
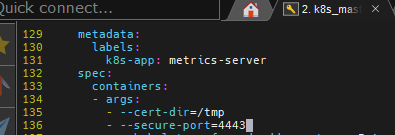
metric 사용하는데, 공인 인증서를 사용하겠다라는 뜻, 하지만 별도로 공인 인증서를 우리는 발급받지 않은 상태에서 사용하고자 한다. 이를 위해서는 공인인증서 없이 포드를 실행할 수 있도록 해 주어야 하는데. 이때 필요한 것이, insecure이다. 참고로 공인인증서는 최고 발급(관리) 기관을 통해 사용자를 인증하고 서명을 하여 발급받을 수 있다.
이거 말고도 우리는 사설 CA를 둘 수 있다.
`- --kubelet-insecure-tls`
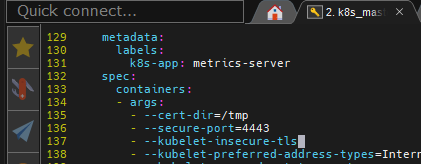
그래서 위와같이 --secure-port 아래에 추가해주면 된다.
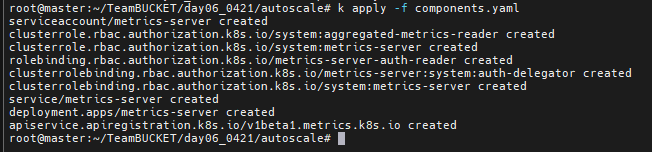
적용해주자
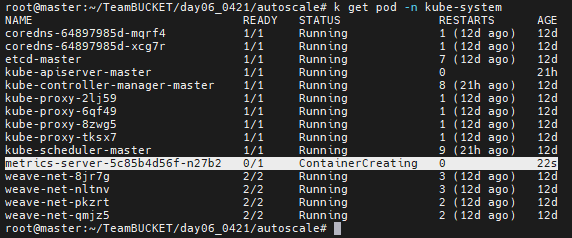
```
k get pod -n kube-system
```
metrics-server가 추가된것을 확인할 수 있으면 된다.
기존에 배포되어 있는 3개의 Deploy가 있다. 이 Deploy를 autoscale 할 예정이다.
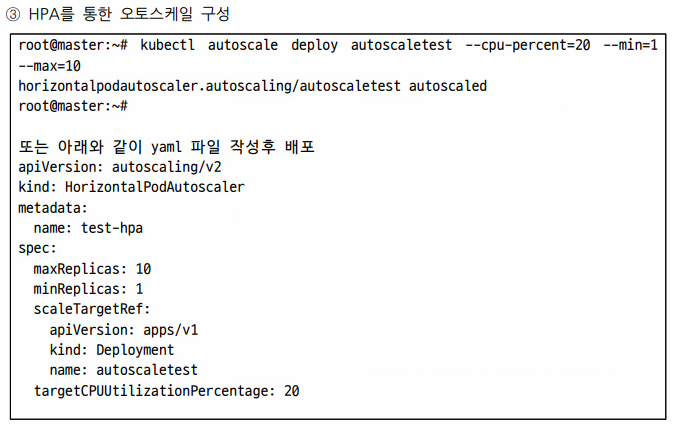

```
kubectl autoscale deploy deploy-blog --cpu-percent=20 --min=1 --max=10
```
이 상황에서 nfs 에서 웹서버 접속을 해보아 일부러 부하를 주자
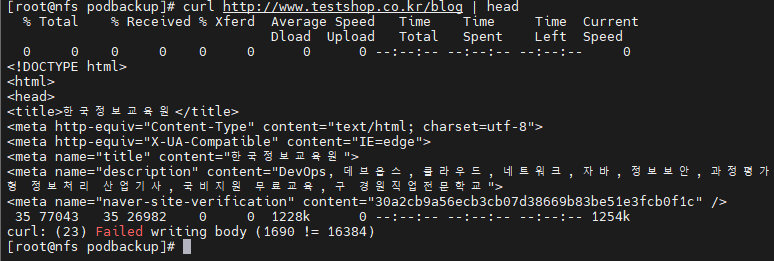
접속까지 성공했으니 이제 트래픽을 던져보자
```
yum install -y httpd-tools
ab -c 1000 -n 200 -t 60 http://www.testshop.co.kr/blog
```
1000명이 pageview 200번 하겠다. 60초 동안


k get hpa로 현재 cpu 사용량을 체크했고 굉장히 많이 늘어남에 따라 deploy-blog의 pod 수도 늘린것을 확인할 수 있다. 중간에 멈추었는데 이 이상하면 컴퓨터가 멈출거 같다.
blog는 최대 10개까지
shop은 최대 10개까지
main은 최대 5개까지 늘어나도록 테스트 해보기

```
k top no --use-protocol-buffers
```
라는 명령어로 node별 cpu, memory 상태를 확인할 수 있다.
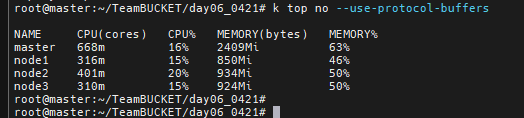
---
마지막 실습과제 :
Dockerfile을 이용하여 CentOS를 가져다가 httpd를 설치하고 웹서비스를 제공하되, main, blog, shop 별로 별도의 index.html 파일을 만들어 ADD 하고 이를 서비스 할 수 있어야 한다.
단, 해당 이미지는 tag를 변경하여 docker hub에 등록하고 앞서 배포했던 /, /blog, /shop에는 자신이 작성한 index.html 파일의 내용이 보여야 한다.
내용은 아주 간단히 만들기
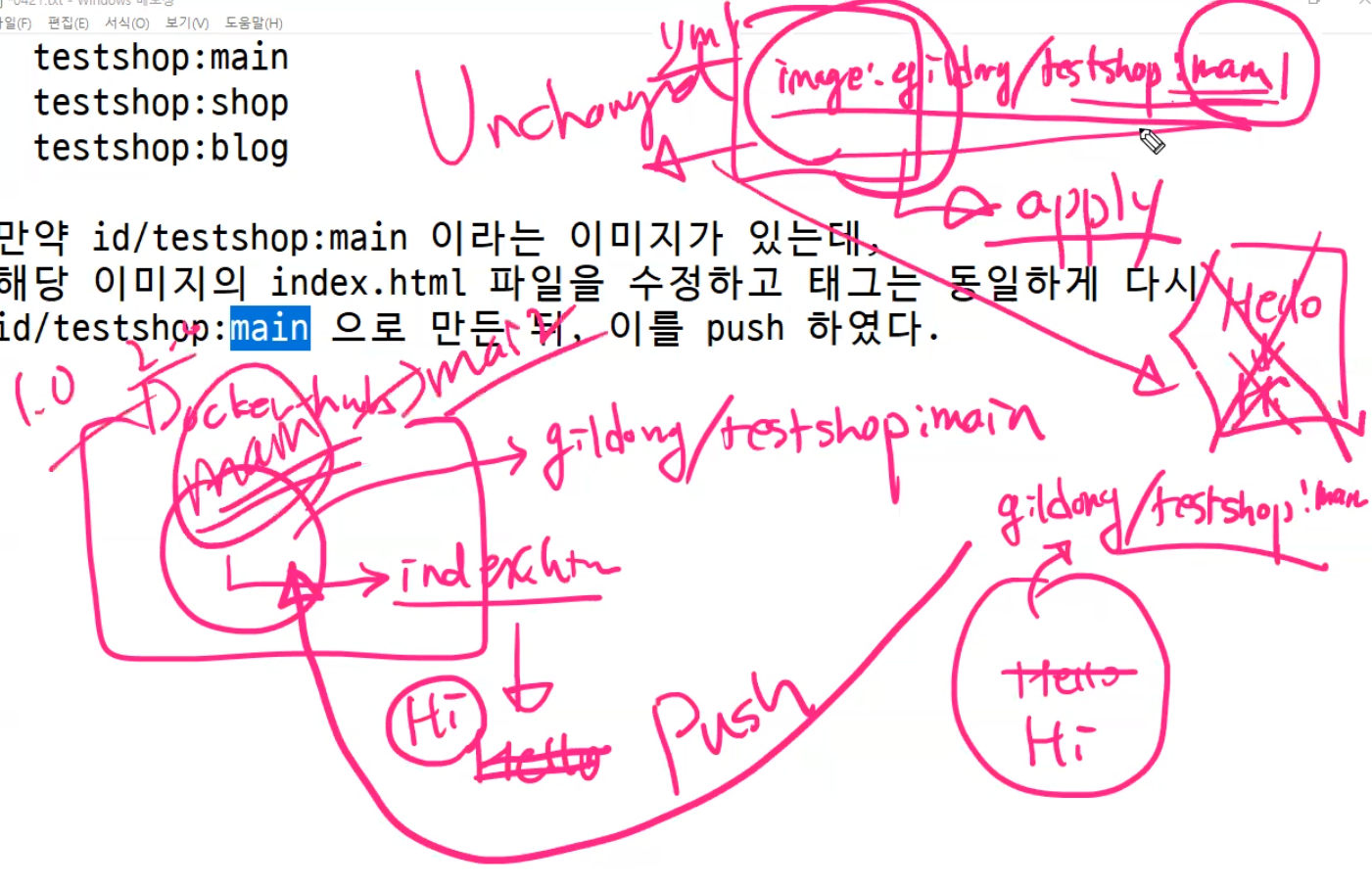
이때 중요한게 Dockerfile 내부가 바뀌면 새로운 이미지가 만들어지는데 혹은 태그를 바꾸면 새로운 이미지가 만들어지는데 index.html 내부 조금 바꾼다고 새로운 이미지가 되지는 않는다.
---
Jenkins를 사용해보자
기존에는 k8s 관리자가 모두 관리하고... 이미지도 관리하고... 개발자가 직접적으로 배포할 방법이 없었다. 그래서 docker-hub 이미지를 업데이트해서 배포를 하되 2개의 파일을 새롭게 만들어야 한다.
1. Dockerfile
2. index.html
이 두가지를 가지고 새롭게 이미지를 만들 준비를 하자
jenkins, gitlab, githosting 중 하나를 사용해야 한다.
jenkins를 이용해서 스크립트를 짜고 동작시키는 것이다. 이 스크립트 내용안에는 git clone, pull 중 하나를 하라고 한다.
그리고 new Image를 master node에서 만든다. 이미지를 바로 worker에 전달못하니 일단 docker hub에 올려버린다. 그리고 worker들은 docker hub에서 받아다가 rolling update 해버리면 된다.
그럼 개발자는 직접적으로 서비스에 들어가지 말고 git에 올리고 jenkins를 사용하기만 하면 된다.
이걸 또 자동화 시키기 위해 github의 변화를 감지하는 무언가를 붙이면 된다.
jenkins를 설치하는 방법은 서버에 직접설치하는 방법과 컨테이너 방법이 있다.
컨테이너는 상대적으로 보안상 안좋기도 하고 안전성도 떨어지는 편이라 그냥 설치를 하자.

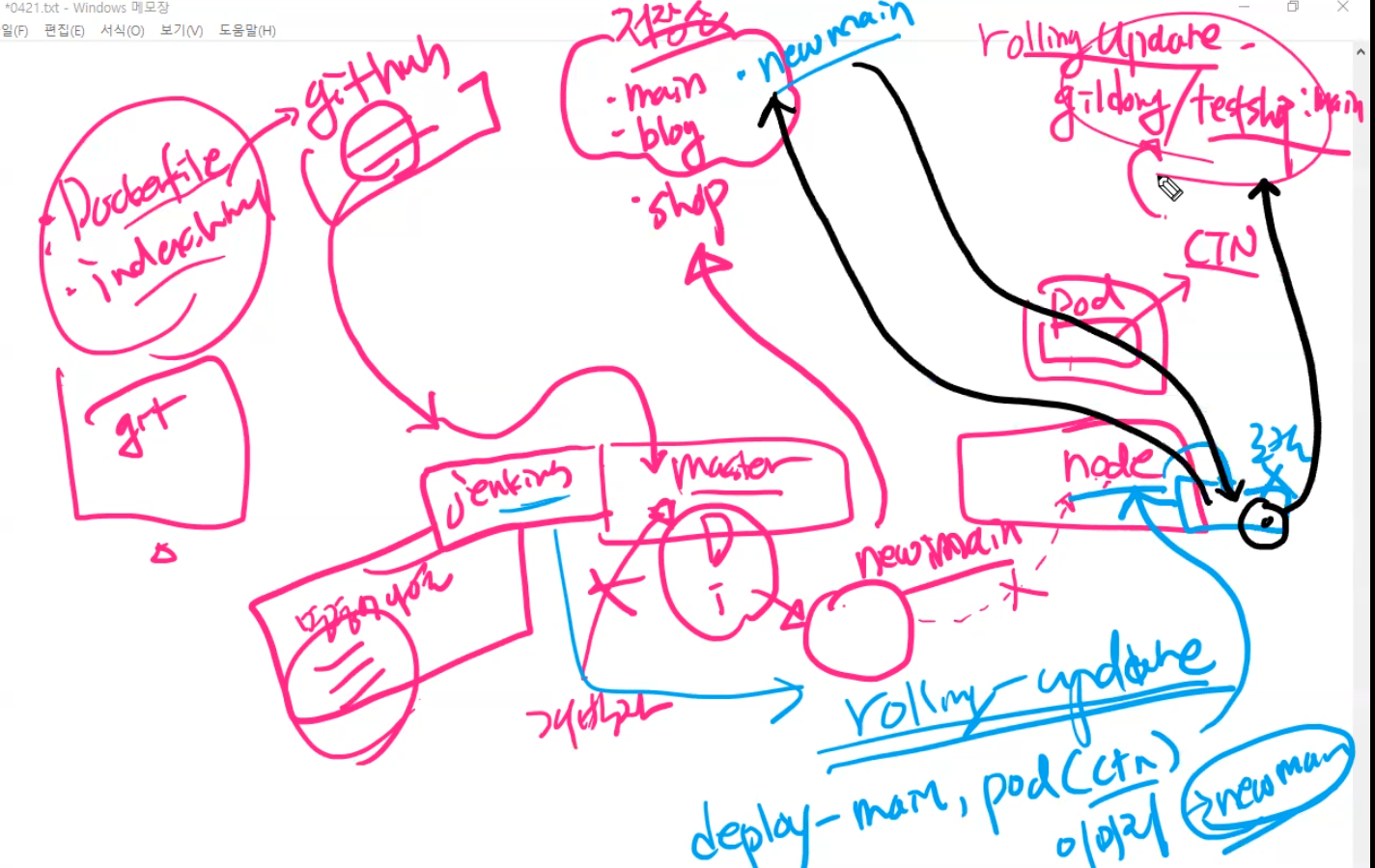
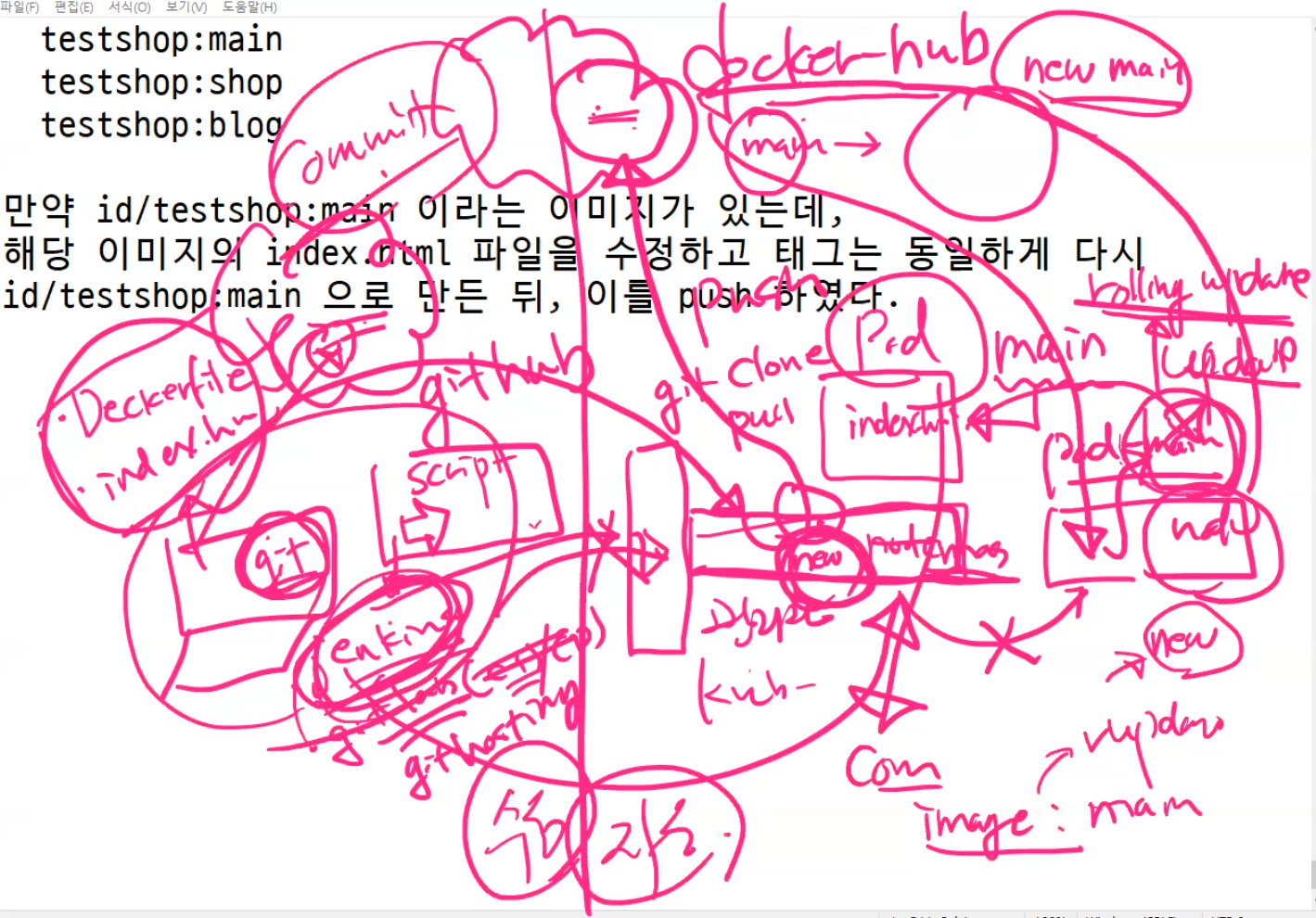
자 우리의 상황을 다시 봐보자
우리는 yaml 파일을 이용해서 master와 node가 존재하고 node 안에는 pod - ctn이 들어가 있다. ctn gildong/testshop:main 이미지를 사용하고 있는데 이걸 rolling update 하면 된다.
개발자에게 master에 들어가서 명령어를 칠 수 있는 권한을 주지는 않는다.
jenkins 계정을 부여해서 주는 것이다.
개발자 PC에는 git이 설치되어 있고 Dockerfile, index.html 파일을 github에 올려주는 것이다.
우리의 docker hub에는 main, blog, shop이라는 이미지가 존재한다.
jenkins 내부에서 명령어를 나열해서 github의 index.html과 Dockerfile을 끌고와서 새로운 이미지를 만든다.
이 이미지는 node가 안가지고 있으니 우리의 docker hub 저장소에 newmain이라고 올려준다.
그러면 jenkins에서 rolling update를 해서 기존의 deploy-main 안에 들어가 있는 pod(ctn)에 이미지를 newmain으로 바꾸어 주는데, 기존 deploy-main 안에 들어가 있는 pod(ctn)의 이미지를 newmain으로 바꾸어라라고 하는 것이다. 그것을 실행하라고 하면 node에게 명령어가 전달된다.
node는 newmain이 있는지 로컬과 docker hub를 찾아보아서 그 이미지를 pull 해서 롤링업데이트 하는 것이다.
jenkins 설치 - master에서
```
java --version
apt-get install openjdk-8-jdk openjdk-8-jre # java가 없다면 설치
wget -q -O - https://pkg.jenkins.io/debian-stable/jenkins.io.key | sudo apt-key add - # ok가 뜨면 된다.
sh -c 'echo deb http://pkg.jenkins.io/debian-stable binary/ > /etc/apt/sources.list.d/jenkins.list'
apt-get update && apt-get install jenkins
systemctl start jenkins ; systemctl enable jenkins
ufw allow 8080
```
여기까지 되었다면 별거 없다. master node의 ip:8080 으로 접속하면 jenkins 화면이 그대로 보인다.
패스워드는 여기에 있으니 가서 복붙하면 된다.
```
cat /var/lib/jenkins/secrets/initialAdminPassword
```

두개가 나오게 되는데 Install suggested plugins를 클릭해준다.
이제 드럽게 오래기다려야 한다.
이 사이에 github를 처리해버리자
새로운 저장소를 만들고 시작해보자
저장소 폴더는 대충 바탕화면에 만들어놓자
대충 index.html과 Dockerfile을 만들어놓자
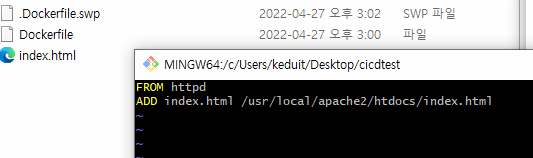
Dockerfile은 이렇게 만들어주자
이제 원격저장소에 넣어주자
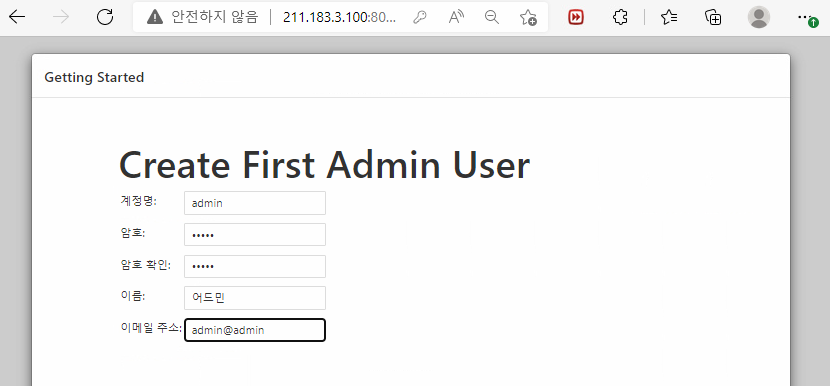
jenkins 설치가 완료되었다면 모든 정보를 admin으로 채우고 그 다음 페이지로 넘어가자
'Development(Web, Server, Cloud) > 22) LINUX - Cloud' 카테고리의 다른 글
| 클라우드 67일차(PV,PVC,jenkins,gcp-정리중) (0) | 2022.04.28 |
|---|---|
| 클라우드 66일차(k8s-labeling, ansible, jenkins) (0) | 2022.04.27 |
| 클라우드 64일차 (MSA, 다이나믹 pvc, 동적 pv, 정리중) (0) | 2022.04.25 |
| 클라우드 63일차(정리중, ingress, 정리중) (0) | 2022.04.22 |
| 클라우드 62일 (0) | 2022.04.22 |



