
노란색이 마스터이다. 파란색이 worker node이다.
master node는 api-server/controller/scheduler/key-value store(etcd) 가 존재한다.
worker node는 kubelete/runtime(docker[ containerd] cri-o, podman)/network proxy가 존재한다.
그림을 보면 kubelet이 마스터로부터 명령을 받는다.
kubelet이 명령을 받으면 Container Runtime으로 명령을 전달하고 Docker 가 Pod를 만들라는 명령을 전달해준다.
만들어진 Pod가 외부 사용자와 접속이 가능하도록 외부와의 연결이 가능하도록 만들어주어야 한다. 이건 Network-Proxy(kube proxy)가 담당하게 된다.

그래서 위의 kube-proxy는 외부와 접속하기 위한 용도이다.

weave-net는 내부에서 소통하기 위한 overlay 네트워크이다.

외부사용자가 pod로 접속하기 위해서는 kube proxy가 담당하고 pod로 연결되도록 해준다. 대신 옵션으로 DNS등이 들어가 있다.
우리가 제작시에 각 포드별로 이름을 달아주면 DNS가 알아서 그 컨테이너(포드)로 연결을 시도해준다.

만약에 DNS가 동작안하면 이름으로 접속못하기 때문에 후에 서비스에 접속이 불가능해진다고 보면 된다.

외부 사용자는 CLI나 UI(Web-UI)를 이용해서 API를 호출한다. API는 명령어로 Pod를 생성한다고 하면 Pod를 만들 수 있는 컨테이너가 내부에 존재한다. 쿠버네티스의 경우는 Pod, Service, 보안, 정책, 환경변수 등의 기능들이 별도의 컨테이너 형태로 만들고 각각의 컨테이너를 API로 연결한다.
우리도 Pod를 만든다고 하면 API를 통해서 API server에 접근한다.
API로 Pod를 요청하면 Pod를 담당하는 컨테이너(API Server)로 연결해준다.
단 이걸 위해서는 key-value store, scheduler, controller가 필요하다

이 4가지는 master의 핵심이기 때문에 master이라는 단어가 뒤에 붙어있다.
etcd는 key-value store이다.
apiserver
controller
scheduler가 보인다. 이것들이 마스터를 이루는 핵심이다.

master을 구성하는 요소
1. api-server ;
control-plane의 프론트엔드, 외부 사용자와 상호통신
api-server가 백 쪽에 있는 각각의 pod에 연결해준다. kubelet에 api를 전달하고 runtime에게 일을 전달해준다.
kubelet은 사실상 작업반장이다.
2. key-value store(etcd); 클러스터 상태 정보 저장소
클러스터 데이터베이스를 백업하기 위해 사용하는 데이터베이스. 마스터는 노드, 포드, 컨테이너들의 상태 정보를 파악하기 위해 etcd에게 쿼리 한다.
우리가 현재 노드들의 상태가 어떤지 물어보면 etcd에 저장이 되어 있다.
kubectl get node를 하면 마스터는 자신의 etcd를 통하여 상태를 파악할 수 있고 이 정보는 사전에 kubelet을 통해 보고 받는다. 보고 받은 정보가 etcd에 저장되는 것이다.
3. controller : 실제로 클러스터를 실행, 하나의 컨트롤러는 스케줄러를 참조하여 정확한 수의 포드를 실행. 포드에 문제가 발생한다면 다른 컨트롤러가 이를 감지하고 대응. 서비스를 포드에 연결하므로 요청이 적절한 엔드포인트로 이동. 계정 및 api 액세스 토큰 생성
"1개 추가 배치"
4. scheduler : 클러스터 상태가 양호한가? 새 컨테이너가 필요하다면 어디에 배치할까? CPU 또는 메모리와 같은 포드의 리소스 요구 사항과 함께 클러스터 상태 고려
"클러스터 상태 확인해 보니까 1개는 여유 있는 node3에 배치"
replicas 5 -> 항상 컨테이너(포드)를 5개 동작시켜라 -> 1개를 강제로 다운 -> 다운상태 감지한 뒤 1개를 새로 생성시켜 5개를 유지시킨다. -> controller

key-value store는 반드시 API Server와 연계가 되어야 한다.
사용자가 Pod를 배치한다고 API Server에 전달하면 API Server는 Pod를 배치하기 위해 Pod를 담당하는 Pod에게 작업을 제시한다. 그럼 Key-value Store에서 어디에 배치할지를 결정해야 한다.
모든 노드가 작업이 가능한 상황이라면 Scheduler가 어디에 배치할지 결정하게 된다. 그럼 API Server는 Kubelete으로 연결해서 작업을 전달하고 Kubelet은 Runtime에게 전달하고 Runtime은 Pod를 하나만들고 만들어진 Pod는 외부 사용자에게 서비스를 제공하기 위해서 Kube-proxy에게 연결된다.
kube-proxy를 통해 외부 사용자가 접속해서 들어오게 되면 서비스를 제공받게 된다. 혹시나 문제가 발생하면 해당 정보는 kubelet을 통해 API Server에게 전달되고 API Server는 그 정보를 key-value store에 저장하게 된다.
개발자가 다시 들어와 노드 상태 정상인지 물어보면 API Server는 상태를 확인하기 위한 etcd 컨테이너(pod)에게 query를 던진다. 그리고 정보를 반환하여 정상/비정상을 판가름 해준다.

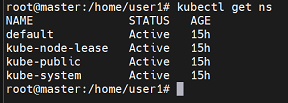
master을 확인해보면 pod는 없지만 kube-system에 대해서는 존재하는 것을 확인할 수 있다.
kubectl get namespace == kubectl get ns
---
kubectl run nginx --image=nginx --restart=Always예시로 위와같이 작성하고 돌려보자
kubectl get pod 하면 아래와 같이 nginx의 pod가 돌고 있는 것을 알 수 있다.

```
kubectl describe pod nginx
```
하면 pod의 상세 정보와 상태를 확인할 수 있다.

이미지를 가지고 와서 컨테이너를 만든 것을 확인할 수 있다.
그런데 pod가 아닌 container라고 부르는 이유는 kubernetes에서는 서비스를 제공하기 위한 최소 단위가 "Pod"이며 Pod는 1개 이상의 "Container"로 구성된다.

curl로 데이터를 긁어보면 nginx의 데이터를 확인해볼 수 있다.
쿠버네티스에서의 모든 작업의 시작은 api-server를 통해 적절한 작업을 담다하는 포드로의 연결에서 부터 시작된다.
사용자나 개발자는 컨트롤러를 통해 발급받은 토큰을 이용하여 작업을 지시하고 지시받은 명령은 api-server가 적절한 pod로 연결하여 작업이 진행된다.
예를들어 사용자가 포드 생성을 요청했다면 이 작업은 api-server로 일단 전달된다. 생성될 포드는 노드의 상태를 확인해야 한다. api-server는 etcd에게 노드들의 상태를 쿼리하고 결과를 통해 정상 상태의 노드를 확인하여 이를 스케쥴러에게 알려주면 스케줄러는 이를 토대로 리소스의 사용량들을 확인하고 포드가 배치될 노드를 선택한다. 노드 선책이 완료되면 이를 api-server에게 전달한다. api-server는 선책된 노드의 kubelet에게 작업을 지시한다. kubelet은 작업을 지시 받은 뒤, 자신의 런타임에게 포드 생성을 명령한다.
작업 결과는 kubelet이 api-server에게 보고하고 해당 정보를 etcd에 저장한다. -> pod1은 node1에 배치되었고 해당 포드는 정상적으로 동작하고 있다.
사용자는 kubectl get pod를 통해 자신이 생성한 포드의 상태를 확인요청한다! 이를 전달받은 api-server는 etcd에게 쿼리하여 정보를 전달받고 이를 화면에 출력 시켜준다.
```
kubectl get pod -o wide
kubectl get pod -n default
```

기본적으로 default namespace에 pod가 만들어진다.
이때 보이는 IP는 pod의 IP이다.
쿠버네티스 내부의 사용자들은 접속이 가능하지만 외부 사용자들은 접속할 수가 없다.
그래서 외부에서 접속하기 위해서는 별도의 pod가 필요하다
쿠버네티스에서의 애플리케이션 배포는 최소 단위가 "Pod"이다. 포드는 한 개 이상의 컨테이너로 구성되어 있다.
Pod안의 컨테이너에 들어가기 위해서는 포트번호를 이용하게 된다.

만약 Pod안에 컨테이너가 2개인 경우라면 port로 구분되어서 접근하게 된다.
각각을 나누기 위해 cgroup을 이용하여 cpu, ram resource를 구분하여 사용하게 된다.
docker, docker swarm은 최소단위가 컨테이너였다. 그래서 자원 불균형이 생길수 있었지만
하지만 Pod단위가 되면서 컨테이너들이 묶여다니기 떄문에 자원 불균형이 생길일이 없어진다.

yaml파일을 이용해서 배포를 하게 된다.
apiVersion : 포드를 담당하는 api version
Kind : 무엇을 위해 만든건가
metadata : 원본 데이터를 지칭하는(대표하는) 데이터들이다.
spec : 배포 정보
위와같이 해서 배포를 할 수 있다.

```
kubectl get pod nginx -o yaml
```
이라고 하면 아까전에는 단순한 명령어로 출력한거 같지만 실재로는 위와같이 복잡한 스펙의 무언가로 출력되게 된다.
위의 데이터를 잠깐보면
metadata의 name은 필수
namespace를 지정해줄 수 있는데 최초는 default로 되어 있다.
spec에는 하위요소들이 들어가게 된다.
지금 우리 입장에서 Pod안에 CTN 이 있고 점진적으로 Pod를 포함하는 것들이 추가된다.
image: nginx
volumeMount도 필수적이다.
container 앞에는 pod가 있다.
```
kubectl exec -it nginx bash # 사라질 명령어
kubectl exec -it nginx -- bash # 이제 사용될 명령어
```

ctrl + p, ctrl + q 로 빠져나오자
이제 삭제해주자
```
kubectl delete pod nginx
```
```
kubectl api-resources
```

하고 들어가면 우리가 사용가능한 다양한 api들을 확인해볼 수 있다.
k8s의 모든 서비스는 api-resources에 등록된 오브젝트를 통해 구성이 가능하다.
사용자는 api버전을 입력하면 해당 api를 통해 오브젝트를 사용할 수 있으며 yaml 파익 작성시에는 api 버전과 Kind를 작성해야 하는데 api-resources에서 확인된 정보를 정확히 기입해야 사용이 가능하다.
NAMESPACE에는 true, false가 있고 이는 해당 오브젝트를 동작 시킬 때 특정 네임스페이스에 속하도록 할 수 있는지 여부를 결정해주는 것이다.
예를 들어 Pod 는 NAMESPACE 가 true 이므로 사용자가 임의로 만든 namespace 에 원하는 포드를 배치시킬 수 있다. "네임스페이스를 사용할 수 있는 오브젝트" , false 는 전체 가 공통적으로 공유하여 사용할 수 있는 오브젝트 이다.
namespace 오브젝트 자체는 따로 namespace에 속해 있지는 않는다.
PVC 같은 경우는 볼륨을 달라고 요청하는 것인데 이런것은 특정 네임스페이스 한군데에서 요청할 수 있기 때문에 namespace가 따로 지정되어 있다.

위와같이 작성해주자
```
kubectl apply -f nginx-pod.yaml
```

kubectl get pod

node3에 배포된것을 확인할 수 있다.

실재 데이터가 불러와진것을 확인할 수 있다.

저번에 만들었던 이미지로도 컨테이너를 만들어보자
이걸 위해 먼저 pod를 없애주어야 한다
```
kubectl apply -f nginx-pod.yaml # 이걸 다시 입력하면 오류는 발생하지 않고 rollup update된다.
kubectl delete -f nginx-pod.yaml # 이걸로 파일기반 삭제가 가능해진다.
```

그런데 방금 방식은 Pod 자체만으로는 포드 1개만 생성하므로 단점이 있다. 클러스터/클라우드 환경에서는 다수의 포드가 안정적으로 동작하는 것이 중요하므로 replica 설정이 필요한데, 이것은 k8s에서는 ReplicaSet이 담당한다.

맨 안쪽에는 container 들이 있고 얘를 감싸는 건 Pod가 된다.
근데 Pod는 1개인데 나는 이걸 Replicaset으로 다수를 만들어서 레플리카 수를 유지하고 싶다고 하자. 예를 들어 Replicaset이 3이면 3개를 만들어서 안정적으로 유지시킨다.
하나가 죽으면 controller가 api-server로 요청을 보낸다. api-server는 어디에 만들지를 알기 위해 scheduler에 요청한다. scheduler는 스케쥴 리소스를 보고 어디에 위치시킬지를 api-server에게 응답한다.
api-server는 node3의 kubelet에게 요청을 보내서 컨테이너를 추가로 만든다.
api-server는 기존에 다운된 정보와 그 이후에 새롭게 돌고 있는 정보를 etcd에 저장한다.
이때부터 사용자는 api-server에 pod 상태를 물어보면 api-server는 etcd에게 상태를 물어보고 결과를 사용자에게 전달한다.
---
레플리카셋 사용하기

사용하기 전에 alias로 kubectl을 등록해놓자
source ~/.bashrc

replicas: pod를 3개 실행
selector: pod는 누구인가 하면 app: my-nginx-pods-label이다.
template 부분은 pod를 이야기 한다.
여기에서 labels - app 부분이 보인다.

데이터를 읽어보자
api는 ReplicaSet을 이용하고
이름은 replicaset-nginx이다.
replica 3개만큼하는데 label이 my-nginx-pods-label이라고 붙은 놈들을 복제하겠다고 한다.
template 내부에 어떤걸 배포하는지 나오고 my-nginx-pod template안에 생성된 pod들에는 my-nginx-pods-label이라는 라벨을 붙이기로 결정했다.
my-nginx-pod안의 컨테이너는 nginx이미지로 돌아가고 80번 포트로 통신한다.
```
kubectl apply -f replicaset-nginx.yaml
```

하니까 3개의 노드에 각각 포드가 배포된 것을 확인할 수 있다.
```
kubectl get pod,rs -o wide
```


```
k describe pod <pod 이름>
```
상세정보를 확인할 수 있다.

이것의 사이즈를 조절해보자

별거 없다 replicas를 2로 조절해주면 된다.
```
k apply -f replicaset-nginx.yaml
```
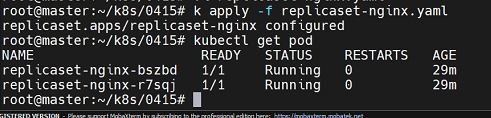
바뀐것을 확인할 수 있다.

ReplicaSet의 상위개념으로 Deployment가 존재한다. Deployment는 롤링업데이트의 기능을 가지고 있다. 그래서 우리는 만들때 Deployment 중심으로 관리해주면된다.
이걸 관리하기 위해서는 별도의 object(service)가 필요하다.
참고로 이때의 object는 3가지의 종류가 존재한다.
```
k get svc
```

포드를 외부에 배포하기 위한 Service 오브젝트에는 다음과 같은 3가지 타입이 있다.
1. ClusterIP : 클러스터 환경 내에서만 접근할 수 있는 주소(외부에서는 접근할 수 없음)

노드에 Pod 3개를 배포했을때 얘네들을 연결하기 위한 목적으로 CLUSTER IP가 사용된다. 외부로 연결은 안되고 내부에서만 연결된다.
Cluster 전용 IP이다. Pod IP가 아니다.
2. Node Port : 외부 연결 가능 -> 처음 접속시 하나에만 연결을 해준다. -> 일반적으로 로컬 환경에서 제공하는 기능
3. lb(로드밸런서) : 외부 연결 가능 -> 처음 접속시 안쪽에 있는 포드들에 로드밸런싱해준다. -> 일반적으로 public cloud 환경에서 제공하는 기능
로컬환경에서 로드 밸런서의 기능을 사용하고 싶다면?
1. 각 노드 앞에 실제 서버를 배치하고 HAProxy를 구성하고 여기에 접속하는 것에 대해서 로드밸런싱해주는 것이다.
이후 HAProxy의 haproxy.cfg 파일 내에 backend 쪽에 각 노드의 IP와 노드 포트를 기록해둔다.

frontend -> 1.1.1.1:80
backend -> 211.183.3.101:31000, 211.183.3.102:31000, 211.183.3.103:31000
외부에 접속하면 1.1.1.1로 접속하면 백엔드의 각 서버에 접속하게 해준다.
2. k8s에서 오브젝트 형태로 사용할 수 있는 LB를 직접 구동시킨다.(제공된 pdf 파일의 부록으로 작성됨)
---

```
kubectl get pod -l app
```
이전 상태를 다시 확인해보면 라벨 app이 붙은 것을 확인할 수 있다.

```
kubectl delete -f replicaset-nginx.yaml
kubectl get pod -l app
```
하면 위와같이 pod가 하나 사라졌고

```
k get rs
```
replicaset으로는 아예 보이지 않는다.

replica set은 어쨌든 우리가 하기로 했던 replicas의 수만큼 유지가 된다.
만약 하나가 갑자기 사라진다면?
```
k apply -f replicaset-nginx.yaml
k delete pod <pod명>
```
살아난다
```
k delete rs replicaset-nginx
```
하면 레플리카 자체를 없앨 수 있다.
Deployment

deployment는 레플리카셋의 상위 오브젝트이다.
replicaset과 다르게 변경 사항을 저장하는 리비전을 남겨 롤백을 가능하게 해주고, 무중단 서비스를 위해 포드의 롤링 업데이트도 할 수 있다는 장점이 있다.

배포하는 시점을 record로 저장하겠다는 의미의 배포를 할 수 있다.
그러다가 이미지를 수정하면서 지점을 저장할 수도 있다.
그리고 이전 버전을 보거나 이전 버전의 위치로 이동도 할 수 있다.

kind 부분만 Deployment 로 바꾸어주면 끝난다.

이렇게 된 것을 배포하려고 하면 워닝이 난다.

자세하게 보기 위해 위와같이 작성해주자
```
kubectl get deploy
kubectl rollout history deploy deploy-nginx
```

배포한것을 보면 deploy가 2개 보인다.
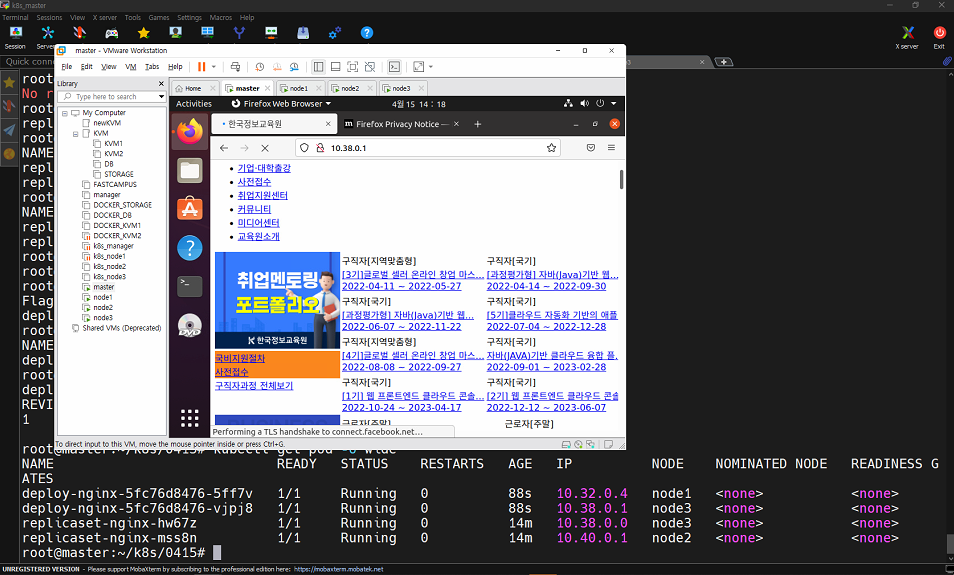
배포된 파일을 볼 수 있다.

이상황에서 이미지를 바꾸어보자
```
kubectl apply -f deploy-nginx.yaml --record
```
로 한번더 적용해주는 방법도 존재한다.
이 방법으로 하면 IP가 바뀐다. 하지만 나중에 이것도 트랙킹할 수 있으니 너무 걱정할 필요는 없다.
혹은 명령어로
```
kubectl set image deploy deploy-nginx nginx tonyhan18/testweb:blue
```
해주면 이미지가 바뀌게 된다.

kubectl get rs

kubectl get deployment

kubectl get pod

```
kubectl rollout history deploy deploy-nginx
```

하면 우리가 현재 2번에 있다는 것을 볼 수 있다.
```
kubectl rollout undo deploy deploy-nginx --to-revision=1
```

하고 나면 기존의 것을 죽이고 새로 만들고 있는 것을 확인할 수 있다.

실재로 이전버전으로 돌아간것을 확인할 수 있다.
실재로 이런것을 보고
blue green deployment라고 부른다.
```
kubectl delete deploy,pod,rs --all
kubectl delete -f deploy-nginx.yaml
```

전부다 삭제해주자

도커는 처음부터 포트를 적어서 외부로 노출이 가능했었다. 그런데 쿠버네티스에서는 포드는 별도 외부로 연결하는 것은 별도의 오브젝트에서 이걸 담당하게 된다.
우리는 형재 Deployment만 만들었는데 사용자가 여기에 들어올 방법이 없다. 그래서 서비스를 Deployment 앞에 부착해서 사용자가 외부에서 접속 가능하도록 해야한다.
서비스 오브젝트는 포드를 연결하고 외부에 노출하는 역활을 한다. 클러스터 외부 + 인터넷 접근이 되도록하기
방법
1. 고유한 도메인 이름을 부여
2. 로드 밸런서 기능을 수행
3. 클라우드 플랫폼의 로드 밸런서, 클러스터 노드의 포트 등을 통해 포트를 외부로 노출(주로 사용)
클라우드에서 배포시 배포방법을 로드밸런서로 하면 자동으로 붙게된다. 그리고 자동으로 노드들과 연결되고 포드와 연결되도록 포트포워딩까지 해준다.
인터넷 사용자들은 로드밸런서의 ip를 통해서 들어오게 된다.
그런데 우리는 그게 아니니
1. NodePort
2. Metal LB

서비스 타입
- ClusterIP : 쿠버네티스 내부에서만 포드들에 접근가능. 3개의 포드를 묶어서 관리하고 싶다면 이걸 clusterIP라고 부르게 된다. 물론 이거 외부로 연결이 안된다. 내부에서만 동작해야하는 것들(ex. DB)에 붙여주면 된다.
그래서 내부에서 동작해야하는 것들은 clusterIP를 사용하게 된다.

예를 들어서 현재 배포된 이 서비스도 EXTERNAL-IP가 없어서 배포가 안된다.

그러니 우리는 앞에 load-balancer을 public cloud에서 두어서 사용자가 접근할 수 있게 만들어주어야 한다.
이렇게 만들기 위해서는 MetalLB라는 것을 이용해야한다.
만약 이게 안되면 HAProxy를 그냥 만들어서 연결해버리면 된다.
두가지를 모두 해보자
- NodePort : 노드에 있는 포드로 연결만을 접속하게 하기 때문에 트래픽 분산도 안되고 IP 3개를 운영해야한다는 단점이 존재한다.


apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-nginx
spec:
replicas: 3
selector:
matchLabels:
app: my-nginx-pods-label
template:
metadata:
name: my-nginx-pod
labels:
app: my-nginx-pods-label
spec:
containers:
- name: nginx
image: tonyhan18/testweb:green
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-nodeport
spec:
ports:
- name: nginx-port
targetPort: 80
port: 8080
selector:
app: my-nginx-pods-label
type: NodePortNodePort 형태로 배포해보자

```
kubectl apply -f deploy-svc-nginx.yaml
```

```
kubectl get pods,rs,svc
```
해보면 정보들이 나오게 된다.
이중에 NodePort의 IP로 외부접속을 시도해보자

실재로 노드의 <아이피:접속포트> 로 접속해보니 우리가 배포한것이 보인다.

그런데 NodePort의 개념대로라면 이게 하나로 바뀐다면 다른 노드로의 접속은 허용되어서는 안되지만 replicas를 1로 바꾸고 해보니 이게 매우 잘된다.
이게 되는 이유가 clusterIP로 묶여 있기때문에 자동으로 라우팅이 발생한다. 이러면 효율이 크게 떨어지게 된다. 그래서 이걸 Load Balancing 해줄 필요가 있다.

```
kubectl describe svc nginx-nodeport
```
로 또 다시 정보를 볼 수 있는데... External Traffic Policy : Cluster가 보인다.
External Traffic Policy
- cluster : 내부로 유입된 트래픽이 목적지 포드를 찾지못하면 라우팅을 통해 다른 노드에 있는 동일 deploy(or replica set)의 포드로 전송시켜준다. 즉, 내부적으로 로드밸런싱이 가능해 진다. 단, 이 경우 안정적인 서비스 제공은 가능하지만 불필요한 라우팅으로 인해 노드의 리소스를 사용하게 된다.
- local : 지정된 노드로 유입된 트래픽은 해당 노드에 위치한 포드로만 전송하며 없을 경우 로드밸런싱하지 않는다.
---
실습 순서
1. vi deploy-svc-nginx.yaml 파일을 열고 replica를 1로 조정후 배포한다.
2. k get svc를 하여 생성된 서비스의 노드포트를 확인한다.
3. http://211.183.3.101: 노드포트(보통 31)로 접속해 본다. 세 노드로 모두 접속하다. 실제로는 1개의 포드만 있지만 모든 접속에서 안정적으로 페이지를 모두 보여준다.
4. vi deply-svc-nginx.yaml을 열고
externalTrafficPolicy: Local 로 수정한 뒤 apply
5. [3]을 해보면 한 노드에서만 웹 접속이 가능하고 다른 노드에서는 접속불가

apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-nginx
spec:
replicas: 1
selector:
matchLabels:
app: my-nginx-pods-label
template:
metadata:
name: my-nginx-pod
labels:
app: my-nginx-pods-label
spec:
containers:
- name: nginx
image: tonyhan18/testweb:green
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-nodeport
spec:
externalTrafficPolicy: Local
ports:
- name: nginx-port
targetPort: 80
port: 8080
nodePort: 31008
selector:
app: my-nginx-pods-label
type: NodePort
Service 부분에서 externalTrafficPolicy: Local로 추가되면 아래와같이 한쪽 노드로만 접속이 가능해진다.

```
kubectl scale --replicas 3 deploy deploy-nginx
```
단순히 명령어로 레플리카의 크기를 키울수도 있다.

이제 로드밸런서를 실재로 배치해서 이것들을 분산처리해보자
HAProxy보다는 metalLB를 써보자

web-ui(정리 안함)
먼저 web-ui를 설치해보자. 물론 자주 쓰는건 아니지만 그래도 실험용으로 사용해보자
kubectl apply -f \
https://raw.githubusercontent.com/kubernetes/dashboard/v2.4.0/aio/deploy/recommended.yaml하면 뭐가 막 나올텐데 그게 끝나고
```
kubectl proxy &
```
http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/#/login이 주소로 자신의 가상머신 웹브라우저에서 접속해보자

그러면 위와같은게 뜬다.
vi dashboard-adminuser.yaml을 작성/배포한다.

apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
이 상황에서 사용자에게 권한 부여를 해주자
```
touch roll.yaml
```
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
마지막으로 토큰을 확인해보자
kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | grep admin-user | awk '{print $1}')위 명령을 이용하면 토큰값이 나오는데 그걸 web-ui에 복붙하여 접근해주자


하면 위와같이 dashboard를 볼 수 있게 된다.
metalLB 구성
1. 네임스페이스 생성하기
mkdir lb
vi namespace.yaml
apiVersion: v1
kind: Namespace
metadata:
name: metallb-system
labels:
app: metallbkubectl apply -f namespace.yaml
2. metallb 배포하기
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.12.1/manifests/metallb.yaml
3. metallb에서 사용할 주소 대역정보를 configmap을 통해 전달해준다.
vi metallb-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
namespace: metallb-system
name: config
data:
config: |
address-pools:
- name: default
protocol: layer2
addresses:
- 211.183.3.201-211.183.3.239

```
kubectl apply -f metallb-config.yaml
```
4. deploy 와 타입 LB 의 서비스를 연결하여 포드 배포하기

아래쪽에 NodePort라고 되어있던것을 LoadBalancer로 바꾸어주고 쓸모없는 것들도 지워주었다.
이걸 가지고 배포해보자
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-nginx
spec:
replicas: 1
selector:
matchLabels:
app: my-nginx-pods-label
template:
metadata:
name: my-nginx-pod
labels:
app: my-nginx-pods-label
spec:
containers:
- name: nginx
image: brian24/testweb:green
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-nodeport
spec:
ports:
- name: nginx-port
targetPort: 80
port: 80
selector:
app: my-nginx-pods-label
type: LoadBalancer```
kubectl apply -f deploy-svc-nginx.yaml
kubectl get svc
```

결과 우리가 배포했던것의 TYPE이 LoadBalancer로 바뀌어 있으면 성공이다.

직접 접속해보자
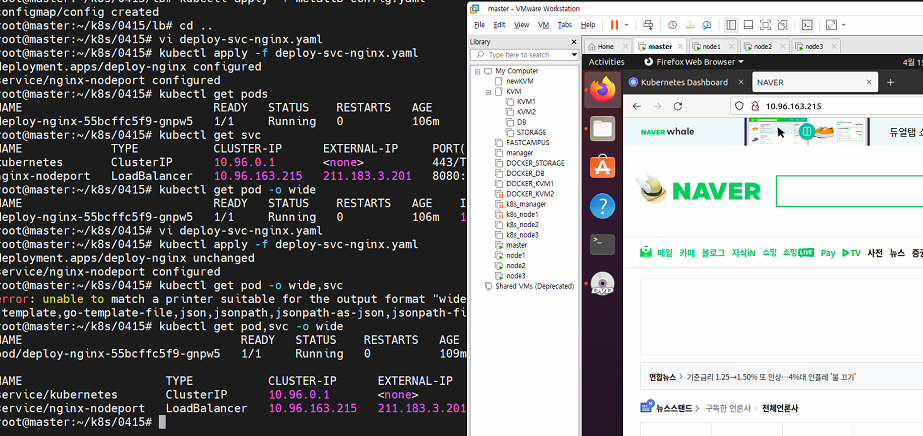
했더니 LoadBalancer의 ip로 접속해도 NAVER가 나오는 것을 확인할 수 있다.
우린 이걸 가지고 이제 DNS 등록만 해주면 성공하는 것이다.
```
kubectl delete -f deploy-svc-nginx.yaml
```
일단 서비스를 없애자

그래서 이 상태가 되면 된다.
'Development(Web, Server, Cloud) > 22) LINUX - Cloud' 카테고리의 다른 글
| 클라우드 63일차(정리중, ingress, 정리중) (0) | 2022.04.22 |
|---|---|
| 클라우드 62일 (0) | 2022.04.22 |
| 클라우드 60일차 (0) | 2022.04.14 |
| 클라우드 59일차 (0) | 2022.04.13 |
| 클라우드 Runtime (k8s) (0) | 2022.04.06 |



