가상화
1. Hypervisor -> bare metal, host base
성능감소가 있음에도 사용하는 이유는 Live Migration(애플리케이션 중단이 없고, 지역간 이동(무중단)이 가능해서이다) = 높은 가용성
하지만 사용자입장에서는 성능저하가 문제가 될 수도 있다. 그래서 이를 해결하기 위한 해결책중 하나로 도커가 존재한다.
2. 시스템 레벨에서의 가상화
도커는 namespace로 공간을 구분하고 cgroup으로 자원을 분배해준다.
OS의 커널을 사용하기 때문에 성능저하가 거의없다.
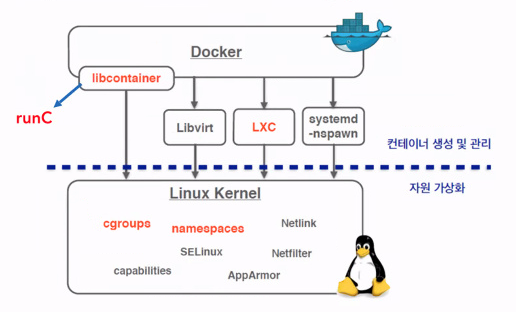
Docker가 리눅스 커널에 접속하기 위해 여러가지 도구들이 존재한다. Libvirt, LXC 등의 방법으로 cgroup과 namespace로 접속했다. 그런데 이 방법의 문제점은 Docker의 도구가 아니라서 도구가 바뀌면 Docker도 코드를 수정했어야 했다. 그래서 직접적으로 리눅스 커널에 접속하기 위한 libcontainer라는 도구를 자체개발했다. 그리고 나중에는 runC로 성능개선이 되었다.
이제는 runC로 cgroups와 namespaces에 접속해서 컨테이너를 만들게 되었다.
????
---
Docker Swarm
docker swarm은 도커 자체의 프로젝트이다. 그렇기 때문에 도커 스웜에서만 쓰는 기능을 써야하고 써드파티에서 제공해주는 것을 사용할 수 없다.
docker-compose
일반적인 도커 : docker container run -d -p 8001:80 --name nginx
= 도커 컨테이너 생성(-> 이미지 필수) + 실행
????
docker network ls 하면 default 네트워크 3가지가 만들어진다.
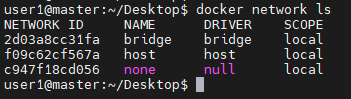
- bridge : 호스트에서 가상의 스위치(브리지)를 생성하고 이 스위치에 컨테이너가 연결되도록 하여 사용하는 방법으로 docker 를 설치하면 기본적으로 생성되는 docker0가 여기에 해당된다. 해당 bridge는 NAT의 기능을 포함하므로 컨테이너는 외부와 통신할때 docker0의 스위치를 통하여 호스트의 실제 NIC 주소로 NAT 된 뒤, 외부와 통신한다.

- host : 컨테이너의 네트워크 포트를 호스트(진짜PC)의 NIC와 동일하게 사용 -> 사실 잘 안쓴다
- null : 네트워크 사용하지 않음
- overlay : 전체 클러스터 환경에 동일한 네트워크 대역을 제공하고 해당 네트워크에 연결된 컨테이너들은 물리적, 논리적 위치에 상관없이 사설 주소를 통하여 통신할 수 있게 된다. overlay를 구성하게 되면 자동으로 외부와 연결을 위한 독립적인 브리지가 별도로 생성되고 해당 브리지는 "로드 밸런싱"의 기능을 갖는다.
이것을 하기 위해 cluster 환경을 만들어서 자원공유를 해주어야 한다. 또 이렇게 네트워크가 만들어지면 overlay와 연결을 위한 bridge가 만들어진다. 이 브릿지에는 LB function 기능을 포함하게 된다.

하지만 overlay 네트워크가 연결되었다고 무조건 좋은게 아닌 것이 접속에 대해서 라우팅이 계속 발생하니 규모가 커짐에 따라서 자원 소모가 크게 발생한다. 그래서 LB로 세션을 넘기지 말고 접속한 호스트에 대해서만 연결이 계속 되도록 해줄 필요가 있다. 그리고 이 서버들 앞에 Load Balancer을 설치해주는 방법으로 해결할 수 있다.

overlay의 사용법은 이렇게 이용할 수 있다. 한개의 서버에 여러개의 컨테이너를 연결해서 사용한다면 왼쪽 그림과 같이 컨테이너 별로 포트를 만들어주어야만 했다. 이러면 문제가 된다.
????
컨테이너는 Data를 영구적으로 보관할 수 없다. 이를 해결하기 위해
1. nfs(파일 스토리지) -> 서버의 폴더를 만들고 그걸 컨테이너에 mount 하는 방법
2. volume(iSCSI - Block Storage) -> 서버에 디스크를 만들고 컨테이너에게 제공하는 방식 -> aws(EBS), openstack(cinder), gcp(persistent Disk)
이떄 볼륨 방식은 가급적 외부에 스토리지를 두어서 언제든 컨테이너가 이동할 수 있게 해줄 필요가 있다.
---
도커 스웜(stack)은 클러스터 화경을 통해 일관적인 인프라 환경 및 컨테이너를 제공할 수 있어야 한다. 이를 위해 yaml
????
curl -L "https://github.com/docker/compose/releases/download/1.24.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
docker-compose --version
클러스터 구성을 위해서는 클러스터에 join 하기 위한 token이 필요하다.
해당 토큰은 manager에서 발행하고 worker이 이 토큰을 이용하여 join을 시도하면 manager는 토큰의 유효성을 검사한 뒤, join을 수락한다.
토큰 발행시에는 기본적으로 manager, worker 용 토큰이 발행된다.
```
docker swarm init --advertise-addr 211.183.3.100
```
하면 토큰이 나온다.
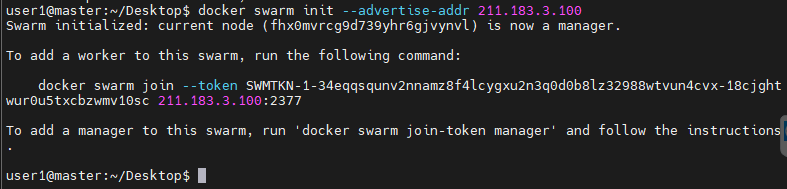
대충 저기에 보이는 토큰 문을 긁어서 node가 될 것들에 복붙해주면 된다.

```
docker node inspect master --pretty
```
로 vm의 성능을 확인해보자
예제1)
nginx를 배포한다.
- 컨테이너의 배포는 worker 에만 배포된다.
- 각 컨테이너는 호스트의 80번 포트와 매핑되어 서비스 된다.
- 이미지는 manager에서 docker login을 하고 인증정보를 worker 들에게 전달하여 각 노드에서 해당 정보를 통해 이미지를 다운 받고 컨테이너를 배포할 수 이어야 한다.
- replica(컨테이너 개수)는 2개만 배포한다.
```
docker service create --replicas 2 --constraint 'node.role != manager' --name mynginx -p 80:80 --with-registry-auth nginx
```
docker service ps mynginx -> 보다 자세하게 어디에 배포되었는지 볼 수 있음
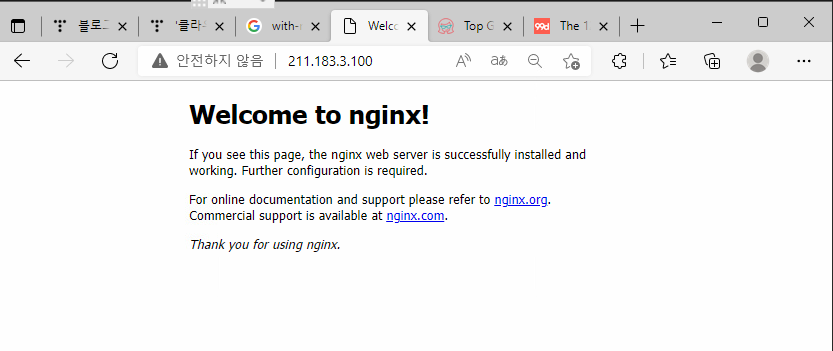
하면 정상 접근된다.

보면 컨테이너를 강제로 삭제해도 다시 생성된다.
```
docker service scale mynginx=3
```
---
서비스 배포를 위한 최소단위
swarm : container
k8s : pod
????
pod는 한개 이상의 컨테이너로 이루어져 있다.
나중에 docker hub의 webhook도 써보자
CI/CD 에서는 특정 이벤트가 발생한 것을 확인하고 변경 사항을 특정 환경에 즉시 반영하도록 할 수 있다.
예를 들어 github에서의 webhook은 저장소에 코드가 push되고 새로운 commit번호가 확인되면 해당 코드를 웹서버에 즉시 반영할 수 있다.
dockerhub에서는 저장소에 새로운 이미지가 등록되면 해당 이미지를 docker swarm, kubernetes 등의 환경에 즉시 반영하여 새로운 이미지를 update 시킬 수 있다.(롤링 업데이트의 자동화)
????
이미지보관소에 이미지를 넣어놓은 상황에서 트리거가 존재한다. 새로운 이미지가 들어오면 자동으로 서버에 배포가 된다.
비슷하게 github/gitlab도 저장소에도 비슷하게 새로운 컴밋에 대해 즉각 반영하게 만들 수도 있다.
예를들어
새로운 버전이 올라가면 트리거가 ansible에게 새로운 코드들을 전달하라고 말할 수 있다.
앤서블은 이 코드들을 git pull해서 데이터 전달받으라고 할 수 있다.
암튼 아까전에 만든 이미지를 가지고 배포해보자
```
docker service creater --replicas 3 --name testweb -p 80:80 --with-registry-auth tonyhan18/testweb:blue
# 롤링업데이트 수행
docker service update --image tonyhan18/testweb:green testweb
```
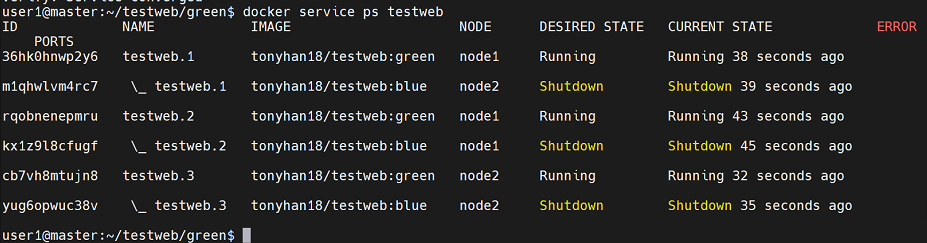
실재 상태를 보아하니 기존에 있던 blue는 죽고 green은 살아있다.
docker stack을 이용한 wordpress 배포하기
compose의 yaml을 이용하여 swarm에서 배포(클러스터 내에 배포)하는 방식
- 장점 : 재사용가능
version: '3.6'
services:
db:
image: mysql:5.7
volumes:
- db_data:/var/lib/mysql
environment:
MYSQL_ROOT_PASSWORD: wordpress
MYSQL_DATABASE: wordpress
MYSQL_USER: wordpress
MYSQL_PASSWORD: wordpress
deploy:
placement:
constraints:
- node.role == worker
replicas: 3
restart: always
wordpress:
image: wordpress:latest
ports:
- "8001:80"
depends_on:
- db
deploy:
placement:
constraints:
- node.role == worker
replicas: 3
restart: always
volumes:
db_data:
????
wordpress에서도 db를 쓰기 위한 설정이 필요하다.
```
docker stack deploy -c wp.yaml wordpress
```
????
물론 이 방법은 좋지 않다. 각자의 db가 각자의 서버에 위치해 있기 때문에 한 서버가 죽었을때 데이터를 되살리기가 쉽지않고 공유되지도 않는다.
이를 해결하기 위해 외부에 스토리지를 두어야 한다.
로컬 볼륨을 각 컨테이너가 사용한다면 데이터의 일관성을 유지할 수 없다. 각 컨테이너는 각 호스트에 있는 볼륨을 사용하므로 나중에 동일한 볼륨으로 접근한다라는 보장을 할 수 없게 된다. 따라서 외부에 디스크를 두고 연결하는 방법을 사용해야 한다. 이를 영구볼륨(persistent volume)이라 한다.
볼륨 접근은 컨테이너가 직접 접근하는 방식이 아니라 호스트에서 접근하는 방식의 proxy방식을 한다. 예를 들어 각 컨테이너에서 nfs로 연결된 볼륨을 사용하고자 한다면 node에 nfs 클라이언트를 설치해 두면 컨테이너가 볼륨을 요청할 때 호스트에서 볼륨을 끌어다 연결시켜 주게 된다.
docker swarm에서 모두 쫓아내고 k8s를 시자해보자
```
docker swarm leave
docker node rm <>
docker swarm leave --force
```
---
k8s
shellinabox
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
cat <<EOF > /etc/apt/sources.list.d/kubernetes.list
deb http://apt.kubernetes.io/ kubernetes-xenial main
EOF
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl
systemctl daemon-reload
systemctl restart kubelet루트 계정으로 모든 노드에서 수행하기
```
vi /etc/docker/daemon.json
```
{ "exec-opts": ["native.cgroupdriver=systemd"] }
넣어놓기
kubeadm init --apiserver-advertise-address 211.183.3.100위의 명령어를 master에서만 시행하기
나에게 접속해서 필요한 오브젝트들을 가져다 쓸 수 있도록 하겠다.
가져다 쓰는 서버를 apiserver라고 부른다.
그 서버를 나의 ip인 211.183.3.100으로 설정해 놓겠다. 라는 의미이다.
하면 가입을 할 수 있는 토큰이 나온다. 이걸 가지고 가서 노드들에게 뿌려주자.
그러면
kubeadm -> 설치(master)
kubectl -> 관리(master)
kubelet -> 실행(node)
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
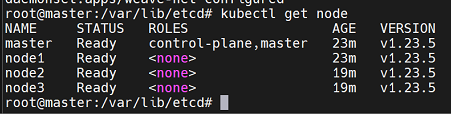
kubectl get node
해서 잘 안뜨면
kubeadm reset 해서 master부터 node 모두를 초기화해준다.
그리고
kubeadm init --apiserver-advertise-address 211.183.3.100이걸 다시 수행해서 토큰을 긁어오자
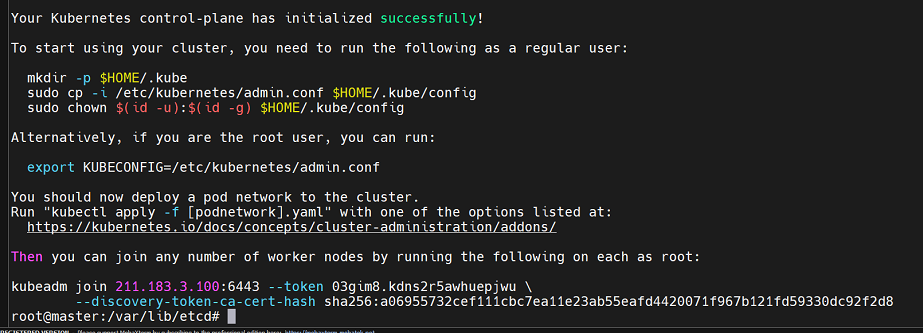
[k8s] Get http://localhost:10248/healthz: dial tcp 127.0.0.1:10248: connect: connection refused. 발생 시.
redplug입니다. 테스트 환경은 Ubuntu 18.04.2 LTS 버젼 입니다. 쿠버네티스 설치 진행 시 kubeadm init, join 시 'http://localhost:10248/healthz: dial tcp 127.0.0.1:10248: connect: connection refused.' 문..
redplug.tistory.com
에러가 정말 많이 날텐데 몇번 반복해주어야 만족할만한 결과가 나온다.
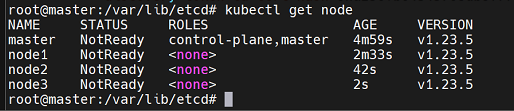
이상태에서 overlay 네트워크가 필요하니
master에서 아래의 것을 수행해주자
kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml
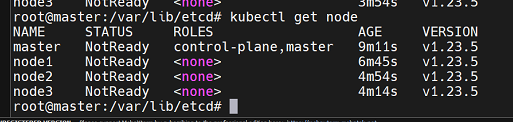
하면 위에서 node들이 Ready로 바뀌어야 하는데 잘 안된다...
모든 master, node들을 kubeadm reset 해주자
그리고 다시
kubeadm init --apiserver-advertise-address 211.183.3.100
하고나니 아래 에러가 뜬다.

Kubernetes #3. 쿠버네티스 Unable to connect to the server: x509
이 에러인데 해결책은
Kubernetes #3. 쿠버네티스 Unable to connect to the server: x509 에러 (tistory.com)
Kubernetes #3. 쿠버네티스 Unable to connect to the server: x509 에러
개요 쿠버네티스 Unable to connect to the server x509 에러 kubernetes x509 에러 쿠버네티스 클러스터 설치를 성공적으로 진행하던중 갑자기 노드들의 상태 확인이 불가한 딥빡의 상황이 펼쳐졌다.🤨 해결
zunoxi.tistory.com
```
export KUBECONFIG=/etc/kubernetes/admin.conf
```
결론은 이걸해라
kubectl get pod -n kube-system
---
하 슈벌 안되었다.
다른 ad-on을 사용했다.
```
kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')"
```
'Development(Web, Server, Cloud) > 22) LINUX - Cloud' 카테고리의 다른 글
| 클라우드 62일 (0) | 2022.04.22 |
|---|---|
| 클라우드 61일(kubernetes 개념, pod, Deployment, Metal LB, autoscaler, web-ui) (0) | 2022.04.15 |
| 클라우드 59일차 (0) | 2022.04.13 |
| 클라우드 Runtime (k8s) (0) | 2022.04.06 |
| 클라우드 프로젝트 1-3 : RE (0) | 2022.03.30 |



