
임베딩이란? | DataLatte's IT Blog (heung-bae-lee.github.io)
임베딩이란?
컴퓨터가 바라보는 문자 아래와 같이 문자는 컴퓨터가 해석할 때 그냥 기호일 뿐이다. 이렇게 encoding된 상태로 보게 되면 아래와 같은 문제점이 발생할 수 있다. 이 글자가 어떤 글자인지를 표시
heung-bae-lee.github.io

- 아래와 같이 문자는 컴퓨터가 해석할 때 그냥 기호일 뿐이다. 이렇게 encoding된 상태로 보게 되면 아래와 같은 문제점이 발생할 수 있다.
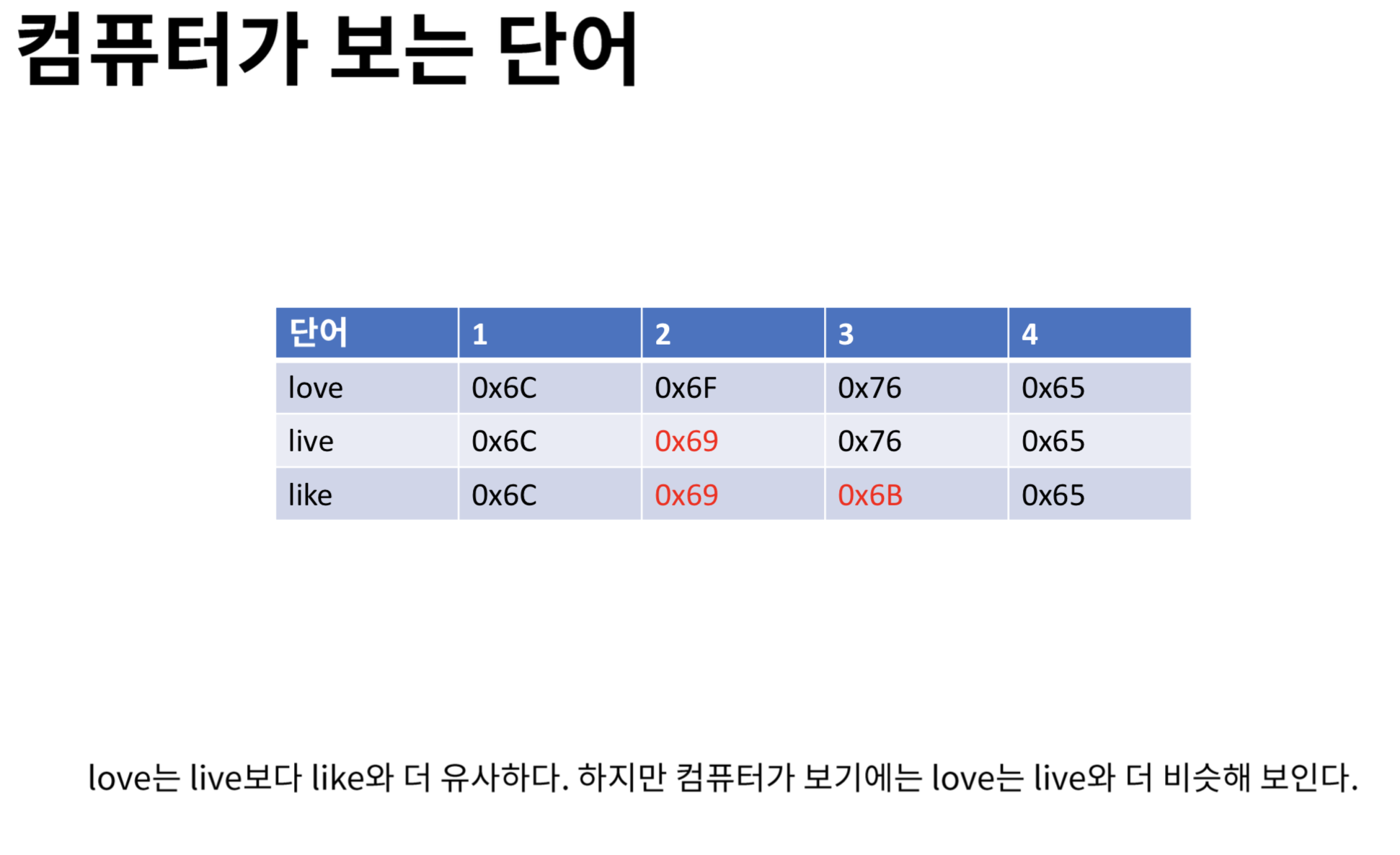


- 이 글자가 어떤 글자인지를 표시할 수 있고 그에 따른 특성을 갖게 하려면 우선 계산할 수 있게 숫자로 만들어 주어야 할 것이다. 그러한 방법 중 가장 단순한 방법이 One-hot encoding을 통한 것이다. 허나, 이러한 Sparse matrix를 통한 계산은 너무 비효율 적이다. 그렇다면 어떻게 dense하게 표현할 수 있을지를 고민하는 것이 바로 Embedding이라는 개념의 본질일 것이다.
임베딩(Embedding)이란?
- 자연어 처리(Natural Language Processing)분야에서 임베딩(Embedding)은 사람이 쓰는 자연어를 기계가 이해할 수 있는 숫자형태인 vector로 바꾼 결과 혹은 그 일련의 과정 전체를 의미
- 가장 간단한 형태의 임베딩은 단어의 빈도를 그대로 벡터로 사용하는 것이다. 단어-문서 행렬(Term-Document Matrix)는 row는 단어 column은 문서에 대응한다.

- 위의 표에서 운수좋은 날이라는 문서의 임베딩은 [2, 1, 1]이다. 막걸리라는 단어의 임베딩은 [0, 1, 0, 0]이다. 또한 사랑 손님과 어머니, 삼포 가는 길이 사용하는 단어 목록이 상대적으로 많이 겹치고 있는 것을 알 수 있다. 위의 Matrix를 바탕으로 우리는 사랑 손님과 어머니는 삼포 가는 길과 기차라는 소재를 공유한다는 점에서 비슷한 작품일 것이라는 추정을 해볼 수 있다. 또 막걸리라는 단어와 선술집이라는 단어가 운수 좋은 날이라는 작품에만 등장하는 것을 알 수 있다. 막걸리-선술집 간 의미 차이가 막걸리 기차 보다 작을 것이라고 추정해 볼 수 있다.
임베딩의 역할
- 1) 단어/문장 간 관련도 계산
- 단어-문서 행렬은 가장 단순한 형태의 임베딩이다. 현업에서는 이보다 복잡한 형태의 임베딩을 사용한다. 대표적인 임베딩 기법은 Word2Vec을 뽑을 수 있을 것이다. 이렇듯 컴퓨터가 계산하기 쉽도록 단어를 전체 단어들간의 관계에 맞춰 해당 단어의 특성을 갖는 벡터로 바꾸면 단어들 사이의 유사도를 계산하는 일이 가능해진다. 자연어일 때 불가능했던 유사도를 계산할 수코사인 유사도 계산이 임베딩 덕분에 가능하다는 것이다. 또한 임베딩을 수행하면 벡터 공간을 기하학적으로 나타낸 시각화 역시 가능하다.
- 2) 의미적/문법적 정보 함축
- 임베딩은 벡터인 만큼 사칙 연산이 가능하다. 단어 벡터 간 덧셈/뺄셈을 통해 단어들 사이의 의미적, 문법적 관계를 도출해낼 수 있다. 예를들면, 아들 - 딸 + 소녀 = 소년이 성립하면 성공적인 임베딩이라고 볼 수 있다. 아들 - 딸 사이의 관계와 소년 - 소녀 사이의 의미 차이가 임베딩에 함축돼 있으면 품질이 좋은 임베딩이라 말할 수 있다는 이야기이다. 이렇게 단어 임베딩을 평가하는 방법을 단어 유추 평가(word analogy test)라고 부른다.
- 3) 전이학습(Transfer learning)
- 품질 좋은 임베딩은 모형의 성능과 모형의 수렴속도가 빨라지는데 이런 품질 좋은 임베딩을 다른 딥러닝 모델의 입력값으로 사용하는 것을 transfer learning이라 한다. 예를 들면, 대규모 Corpus를 활용해 임베딩을 미리 만들어 놓는다. 임베딩에는 의미적, 문법적 정보 등이 녹아 있다. 이 임베딩을 입력값으로 쓰는 전이 학습 모델은 문서 분류라는 업무를 빠르게 잘 할 수 있게 되는 것이다.

[논문과 코드] Attention is all you need *line-by-line :: Blue collar Developer (tistory.com)
[논문과 코드] Attention is all you need *line-by-line
2017년 발표된 sequence to sequence modeling의 신세기를 연 "Attention is all you need"에 대한 article입니다. 3년이 지난 현재까지도 많은 Deep learning 관련 sequence to sequence 논문들이 Transformer mo..
developers-shack.tistory.com

트랜스포머는 위와 같은 구조로 이루어져 있습니다. 트랜스포머 모델을 처음으로 본 분들은 어떤 점이 신박한 부분인지 잘 감이 안 올 수 있는데, 앞서 설명에서의 Transformer model의 장점과 연결시켜 설명드리면,
1. Sequence-to-sequence 모델링은 말 그대로, 정보가 순서대로 나열된 수열(vector sequence)을 입력으로 받아 다른 종류의 수열을 출력으로 내보내게 되는데, 이를 정보가 순서대로 나열된 수열을 다루는 데에 사용되는 Recurrent Neural Network (RNN)을 사용하지 않고 최고 수준의 높은 성능이 나왔다.
2. RNN을 사용하지 않았기 때문에 RNN 훈련에서의 단점인 순차적 학습으로 인한 학습 속도 저하가 없어 빠른 학습이 가능하다.

Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
최근 10년 동안의 자연어 처리 연구 중에 가장 영향력이 컸던 3가지를 꼽는 서베이에서 여러 연구자들이 꼽았던 연구가 바로 2014년에 발표됐던 sequence-to-sequence (Seq2seq) + Attention 모델입니다 (Sutskev
nlpinkorean.github.io
Attention 은 신경망 기계 번역과 그 응용 분야들의 성능을 향상시키는데 도움이 된 컨셉
연구를 통해 context 벡터가 이런 seq2seq 모델의 가장 큰 걸림돌인 것으로 밝혀졌습니다. 이렇게 하나의 고정된 벡터로 전체의 맥락을 나타내는 방법은 특히 긴 문장들을 처리하기 어렵게 만들었습니다. 이에 대한 해결 방법으로 제시된 것이 바로 “Attention” 입니다. attention 메커니즘은 seq2seq 모델이 디코딩 과정에서 현재 스텝에서 가장 관련된 입력 파트에 집중할 수 있도록 해줌으로써 기계 번역의 품질을 매우 향상 시켰습니다.

첫 번째로 encoder 가 decoder에게 넘겨주는 데이터의 양이 attention 모델에서 훨씬 더 많다는 점입니다. 기존 seq2seq 모델에서는 그저 마지막 아이템의 hidden state 벡터를 넘겼던 반면 attention 모델에서는 모든 스텝의 hidden states를 decoder에게 넘겨줍니다.

두 번째로는 attention 모델의 decoder가 출력을 생성할 때에는 하나의 추가 과정이 필요합니다. decoder는 현재 스텝에서 관련 있는 입력을 찾아내기 위해 다음 과정을 실행합니다:
2. 각 스텝의 hidden state마다 점수를 매깁니다 (일단 지금은 어떻게 점수를 매기는지에 대해서는 얘기하지 않겠습니다)
3. 매겨진 점수들에 softmax를 취하고 이것을 각 타임 스텝의 hidden states에 곱해서 더합니다. 이를 통해 높은 점수를 가진 hidden states는 더 큰 부분을 차지하게 되고 낮은 점수를 가진 hidden states는 작은 부분을 가져가게 됩니다.

이러한 점수를 매기는 과정은 decoder가 단어를 생성하는 매 스텝마다 반복됩니다.
이제 이때까지 나온 모든 과정들을 합친 다음 영상을 보고 어떻게 attention 이 작동하는지 정리해보겠습니다:
- attention 모델에서의 decoder RNN 은 <END>과 추가로 initial decoder hidden state을 입력받습니다.
- decoder RNN 은 두 개의 입력을 가지고 새로운 hidden state벡터를 출력합니다. (h4). RNN의 출력 자체는 사용되지 않고 버려집니다.
- Attention 과정: encoder의 hidden state 모음과 decoder 의 hidden state h4 벡터를 이용하여 그 스텝에 해당하는 context 벡터 (C4) 를 계산합니다.
- h4 와 C4 를 하나의 벡터로 concatenate (연결, 이어쓰기) 합니다.
- 이 벡터를 feedforward 신경망 (seq2seq 모델 내에서 함께 학습되는 layer 입니다) 에 통과 시킵니다.
- feedforward 신경망에서 나오는 출력은 현재 타임 스텝의 출력 단어를 나타냅니다.
- 이 과정을 다음 타임 스텝에서도 반복합니다.

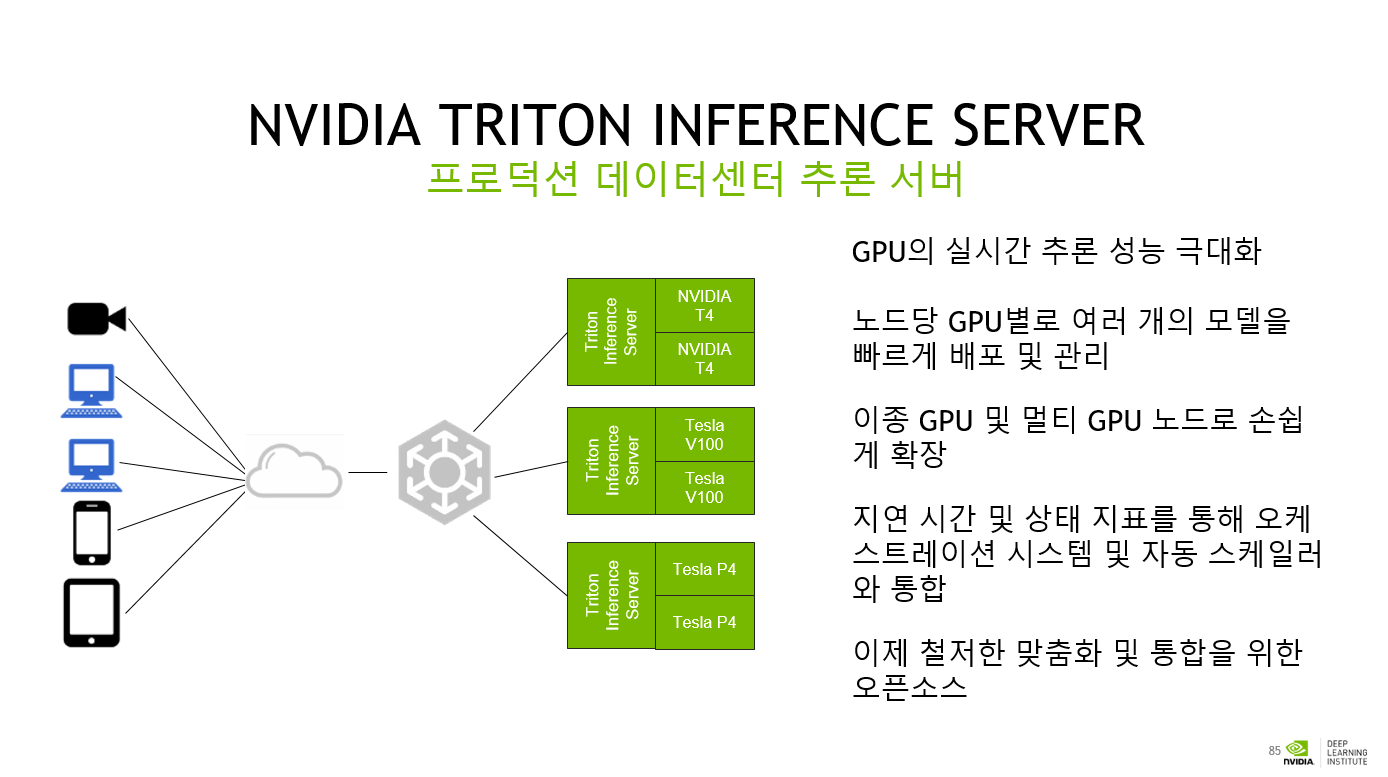
GPU의 실시간 추론 성능 극대화
노드당 GPU별로 여러 개의 모델을 빠르게 배포 및 관리
이종 GPU 및 멀티 GPU 노드로 손쉽게 확장
지연 시간 및 상태 지표를 통해 오케스트레이션 시스템 및 자동 스케일러와 통합
이제 철저한 맞춤화 및 통합을 위한 오픈소스


'Others > 22) 캡스톤 디자인2' 카테고리의 다른 글
| Transformer 기반 자연어 처리 애플리케이션 구축 - 1부: Machine Learning in NLP (0) | 2022.06.06 |
|---|---|
| Machine Learning in NLP (0) | 2022.06.06 |
| 캡디2 - 12 실행, 모니터링 (0) | 2022.05.27 |
| 캡스톤디자인2 - 10 (0) | 2022.05.13 |
| 캡스톤디자인2 - 7 (0) | 2022.04.14 |



