170. AWS Snow Family 개요

이번에는 AWS Snow 제품군을 살펴보겠습니다.
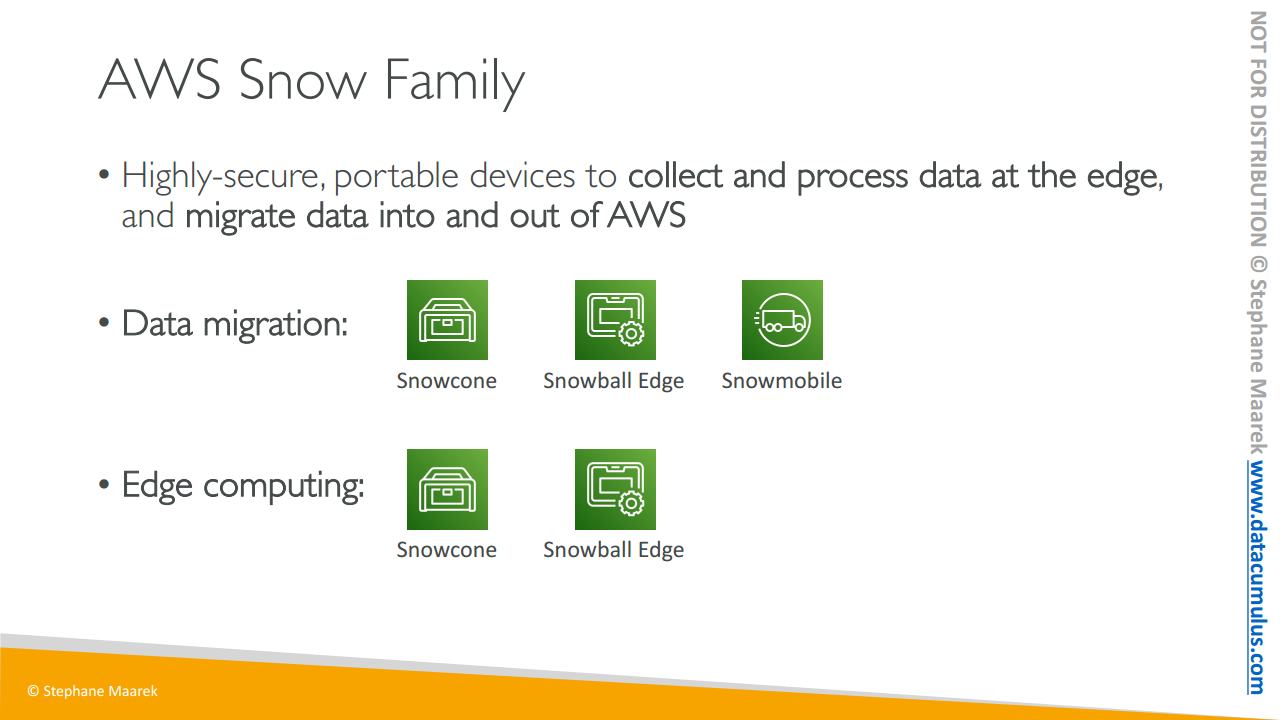
이 제품군은 보안성이 뛰어난 휴대용 장치의 모음으로써 AWS 내에서 두 가지 경우에 사용되고 있습니다. 엣지에서 데이터를 수집하고 처리하기 위해 사용되거나 AWS 안팎으로 데이터를 마이그레이션 할 때입니다.
두 가지 사용 사례에서 데이터 마이그레이션은 세 개의 Snow 제품군 장치가 사용됩니다. Snowcone, Snowball 엣지 그리고 Snowmobile입니다.
또 다른 사용 사례인 엣지 컴퓨팅에는 Snowcone 및 Snowball Edge가 쓰이죠.
먼저 데이터 마이그레이션 내용을 살펴본 이후에 엣지 컴퓨팅을 다루겠습니다.

그러면 우리가 데이터 마이그레이션을 할 때 왜 AWS Snow 제품군을 사용할까요?
보다시피 네트워크를 통해서 많은 데이터를 전송하려면 아주 오랜 시간이 걸립니다. 예를 들어 100TB를 전송하는 경우 초당 1GB의 네트워크 회선을 이용한다면 전송을 완료하는데 12일이 걸릴 겁니다. 즉 전송할 데이터가 PB 이상이라면 상상 이상의 시간이 걸리겠지요.
때때로 그렇게 AWS에 빠르게 접속해야 할 때가 있는데그런 경우에 생기는 문제점은 전송 가능한 데이터의 양이 적다는 것과 제한된 연결 및 제한된 대역폭 문제와 네트워크를 통한 데이터 전송으로 비용이 발생한다는 것입니다. 네트워크를 사용하는 게 무료는 아니니까요. 또 대역폭 공유 문제도 있습니다. 만약 AWS에서 영상을 다운로드하는데 그 데이터 크기가 10TB라면 사무실 전체가 차단될 수 있습니다. 사무실 내의 대역폭을 최대화하기 때문입니다. 그리고 연결이 안정되지 않아서 재시도를 해야 할 수도 있습니다.
바로 이런 이유들 때문에 Snow 제품군이 사용됩니다. Snow 제품군은 오프라인에서 데이터 마이그레이션을 실행하는 장치입니다. AWS가 우편으로 물리적 장치를 보내주면 거기에 데이터를 끌어오고 다시 AWS로 전송하는 겁니다. 일반적으로 데이터 전송 시 네트워크를 사용할 경우 일주일이 넘는 시간이 걸린다면 Snowball 장치를 사용해야 합니다.

예시를 보면서 실제로 어떻게 작동하는지 볼게요. Amazon S3으로 직접 파일을 업로드하려면 클라이언트가 Amazon S3로 데이터를 전송할 겁니다.
그런데 Snow 제품군의 Snowball 장치가 있는 경우 클라이언트가 Snowball 장치를 요청하고 우편으로 받습니다. AWS가 장치를 배송해 주면 로컬에서 데이터를 직접 장치로 가져오지요. 그 장치를 AWS 시설의 AWS로 다시 배송하면 AWS 측에서 장치를 가져다 자체적인 인프라에 연결합니다. 이때 데이터를 불러오거나 내보내는 작업을 하는데 Amazon S3 버킷에서 무엇을 하느냐에 따라 결정되지요. 즉 AWS로 데이터를 전송하는 방법이 맞는데 네트워크가 아닌 물리적인 경로를 이용하는 겁니다.

그러면 어떤 장치가 있을까요?
우선 Snowball Edge입니다. Snowball Edge는 보다시피 커다란 상자인데 TB 혹은 PB 크기의 데이터를 AWS 안팎으로 전송할 수 있습니다.
아까처럼 네트워크를 대신해서 데이터를 옮길 수 있지요.
데이터 전송 건마다 비용이 청구됩니다.
Snowball Edge 인터페이스는 블록 스토리지를 제공하거나 Amazon S3 호환 객체 스토리지를 제공합니다.
Snowball Edge에는 두 가지 옵션이 있습니다. Snowball Edge Storage Optimized는
- 블록 볼륨으로 사용할 수 있도록 80TB의 하드웨어 디스크 용량을 제공하거나 S3 호환 객체 스토리지를 줍니다.
Snowball Edge Compute Optimized는
- 42TB의 HDD 용량을 제공하지요. 따라서 더 큰 스토리지가 필요할 때 사용할 옵션은 Snowball Edge Storage Optimized입니다.
Snowball Edge를 데이터 전송에 쓰는 경우는 데이터 센터 폐쇄를 위한 대량의 데이터 클라우드 마이그레이션이나 AWS에 데이터를 백업함으로써 재해 복구를 하는 경우입니다.
여기까지 첫 번째 옵션이었고

다음은 AWS Snowcone입니다.
Snowcone이라는 이름처럼 작고 귀여운 장치랍니다. 보다시피 크기가 더 작습니다. 이더넷 포트도 있는데 Snowball Edge보다 Snowcone이 훨씬 작습니다.
어디서나 컴퓨팅 가능한 작은 휴대용 장치이자 견고하고 안전하며 가혹한 환경을 견딜 수 있어 사막에서든 물속이든 사용할 수 있습니다.
정말 가볍고 안전한 장치입니다
엣지 컴퓨팅, 스토리지 및 데이터 전송에 사용되는데 물론 용량이 작을 경우입니다.
Snowcone의 스토리지에는 8TB를 저장할 수 있으며 Snowball Edge Storage Optimized와 비교하면 10배는 적은 용량입니다.
Snowball 사용이 불가능할 때 Snowcone을 쓸 수 있습니다. 예를 들면 공간의 제약을 받는 환경입니다. 필요하면 Snowcone을 드론 위에 설치할 수도 있어요.
또한 배터리와 케이블은 직접 준비해야 합니다.
그리고 AWS 오프라인으로 다시 전송될 수 있으며 아니면 네트워크에 연결해서 AWS DataSync를 사용해 데이터를 재전송할 수 있습니다. 네트워크 연결이 전혀 없는 환경에 Snowcone이 있다고 생각합시다. 데이터를 끊임없이 수집하겠지요. 그리고 집으로 돌아가 데이터 센터에 가서 Snowcone을 데이터 센터에 연결하면 데이터가 자동으로 AWS에 전송됩니다. 혹은 오프라인으로 AWS에 재전송 할 수도 있죠. Snowcone에는 그런 두 가지 옵션이 있습니다.

Snowmobile은 실제로 트럭입니다. 그래서 발표를 할 때 진짜 트럭을 무대로 가져와서 트럭이 데이터를 전송한다는 것을 보여주기도 했습니다.
Snowmobile가 전송하는 데이터는 EB(엑사바이트)에 달합니다. 1EB는 1,000PB이며 1백만 TB와 같습니다.
각 Snowmobile의 용량은 100PB입니다. 따라서 데이터 1EB를 처리하려면 Snowmobile을 열 대 주문해야 합니다.
보안성이 뛰어나고 온도 조절이 가능하며 GPS 추적 및 연중무휴 비디오 감시로 굉장히 안전한 데이터 전송 방법입니다.
그러니 10PB 이상의 데이터를 전송하려면 Snowball보다 좋은 방법이라고 할 수 있습니다.

데이터 마이그레이션의 세 가지 방법을 정리하겠습니다.
Snowcone, Snowball Edge 그리고 Snowmobile이 있고 각각의 스토리지 용량이 서로 다릅니다. 8TB, 80TB, 100 PB입니다. AWS에서 권장하는 마이그레이션 크기는 Snowcone이 24TB까지 Snowball Edge는 PB까지 그리고 AWS로 오프라인 재전송도 가능합니다. Snowmobile의 경우 최대 EB 데이터까지 전송 가능합니다.
Snowcone에는 DataSync가 미리 설치되어 있어서 DataSync는 네트워크 연결을 통해 AWS에도 데이터를 전송할 수 있습니다.
Snowball Edge에서는 스토리지 클러스터링으로 Snowball Edge 15개를 함께 구축하면 스토리지 크기를 늘릴 수도 있지요.

Snow 제품군 장치를 사용하는 방법을 알아봅시다
1. 우선 배송을 위해 콘솔에서 장치를 요청합니다. 이 부분은 실습에서 볼게요
2. Snowball 클라이언트나 나중에 배울 AWS OpsHub를 서버에 설치하고 난 다음에는 Snowball을 서버에 연결하고
3. 클라이언트를 사용해서 파일을 복사합니다.
4. 준비가 끝나서 장치를 다시 보내면 올바른 AWS 시설로 바로 옮겨집니다. E 잉크 마커 덕분이지요.
5. 그리고 S3 버킷에 해당 데이터를 불러들이고 나면
6. 가장 높은 보안 조치에 따라 Snowball은 전부 지워지게 됩니다
이것이 데이터 마이그레이션인데 Snowball 장치의 유일한 사용 사례입니다.

Snow 제품군의 두 번째 사용 사례는 엣지 컴퓨팅입니다.
엣지 컴퓨팅은 데이터가 엣지 로케이션에서 생성될 때 실시간으로 처리하는 방식을 뜻합니다.
- 엣지 로케이션이 무엇일까요 인터넷이 없는 곳이나 클라우드에서 멀리 있는 곳은 무엇이든 여기 해당될 수 있습니다. 예를 들면 도로에 있는 트럭이나 바다 위의 배 혹은 지하의 광업소 등의 모두가 엣지 로케이션이 될 수 있어요.
이곳에서 데이터를 만들기는 하지만
- 인터넷은 연결되지 않을 수도 있기 때문입니다 즉 연결이 제한되어 있거나
- 인터넷 액세스가 없거나 컴퓨팅을 할 수 없는 곳이지요. 이런 장소에서 컴퓨팅이나 데이터 처리를 해야 할 경우 바로 엣지 컴퓨팅이 필요합니다.
따라서 Snowball Edge나 Snowcone을 주문해서 엣지 로케이션에 장착시키면 엣지 컴퓨팅을 시작할 수 있게 됩니다.
엣지 컴퓨팅의 예시를 들면
- 데이터 전처리
- 또는 클라우드로 보내지 않고 엣지에서 머신 러닝하는 경우와
- 사전 미디어 스트림 트랜스코딩 등이 있으며,
최종적으로는 데이터를 AWS로 재전송해야 하는 경우 Snowcone이나 Snowball Edge 장치를 보내면 됩니다. 다시 말해 데이터가 생성되는 곳의 아주 가까이에서 그 데이터를 처리하고, AWS로 보내는 겁니다.

엣지 컴퓨팅에 필요한 것 중에서
- 먼저 Snowcone은 CPU 2개와 4GB 메모리, 유무선 액세스 즉 Wi-Fi를 가지고 있습니다.
- 그리고 USB-C 혹은 선택적 배터리로 작동됩니다
그리고 Snowball Edge의 Compute optimized에는 두 가지 종류가 있는데
- Compute Optimized는 52개의 vCPU를 가지며 200GB의 RAM과
- 더불어 선택적 GPU가 있습니다. 영상 처리나 머신 러닝을 할 경우예요.
- 그리고 사용 가능한 스토리지는 42TB입니다.
Snowball Edge의 Storage Optimized는
- 더 적은 40개 vCPU와 80GB RAM을 가집니다.
- 여기서는 객체 스토리지 클러스터링을 할 수 있습니다.
모든 장치들은 내부 EC2 인스턴스나 람다 함수를 실행할 수 있습니다. AWS IoT Greengrass라는 서비스를 통해서 가능해요. 그런데 엣지 컴퓨팅을 할 때 여러분의 트럭, 보트 등의 시설에서 아주 오랫동안 장치를 사용해야 할 경우도 있을 겁니다.
그럴 때 장기 배포 옵션을 선택할 수 있습니다. 장치를 1년에서 3년 빌리면 가격 할인을 받을 수 있지요.

Snow 제품군에 관련하여 마지막으로 OpsHub가 있습니다.
예전에는 이런 장치를 사용할 때 CLI, 즉 명령줄 인터페이스 도구를 써서 처리했으며 방식도 매우 어려웠습니다.
AWS에서 이것을 깨닫고 OpsHub를 만들어 냈어요. 컴퓨터나 노트북에 설치하는 소프트웨어라서 클라우드를 쓰지는 않고 컴퓨터에 다운로드하여 사용해야만 합니다.
그리고 연결이 되면 그래픽 인터페이스를 통해 Snow 장치에 연결해서 구성 및 사용할 수 있으니 아주 손쉬운 방법입니다.
- 이것으로 단일 장치와 클러스터 장치를 잠금 해제하고 구성할 수 있으며
- 파일 전송이 가능해지고 Snow 장치에서 실행되는 EC2 인스턴스를 시작 및 관리할 수 있게 됩니다.
- 또한 장치 메트릭 모니터링과
- AWS 호환 서비스 실행이 가능합니다. EC2 인스턴스, DataSync 혹은 네트워크 파일 시스템 등이죠.
171. AWS Snow Family 실습
172. 아키텍처: Snowball에서 Glacier 까지

이번 강의에서는 시험에 나올만한 시나리오를 짧게 다루겠습니다. Snowball을 통해 데이터를 직접 Glacier에 불러올 수 있을까요.
Snowball은 Glacier에 데이터를 직접 끌어올 순 없고 그렇게 하려면 먼저 Amazon S3를 사용해서 수명 주기 정책을 생성하여 Amazon Glacier로 객체를 전환할 수 있습니다.
이해하면 아주 쉽습니다. Snowball이 데이터를 Amazon S3로 가져오면 S3의 수명 주기 정책을 통해 해당 데이터가 Amazon Glacier로 전환됩니다.
시험에 나오니 기억해 두세요
173. Amazon FSx 개요

이제 Amazon FSx를 살펴보겠습니다.
FSx는 AWS의 관리형 서비스로 이를 통해 AWS에서 타사 고성능 파일 시스템을 실행할 수 있습니다.
완전 관리형 서비스이며 Amazon S3나 EFS 대신 다른 서비스를 사용하고 싶은 경우가 있을 수 있는데요.
예를 들어 Lustre나 Windows File Server 혹은 NetApp ONTAP과 같은 파일 시스템을 사용하려는 경우 이들은 타사 파일 시스템이지만 FSx에서 직접 관리할 수 있어서 데이터베이스에서 직접 실행할 수 있죠.
시험 관점에서 봤을 때 FSx를 타사 고성능 파일 시스템을 실행하는 방법으로 생각해야 합니다. 그리고 Lustre용 FSx와 Windows File Server용 FSx에 관한 걸 물어볼 거예요. NetApp ONTAP은 시험에 나오지 않습니다. 그리고 향후 FSx가 FSx 서비스에 파일 시스템을 더 추가할 가능성이 매우 높습니다. 이번 슬라이드를 포함해 앞으로도 시험에 출제되는 부분만 보여드릴 예정이니 참고해 주세요. 따라서 이번 강의와 다음 강의에서는 Lustre용 FSx와 Windows File Server용 FSx만 다루도록 하겠습니다.

이제 Windows용 Amazon FSx와 문제를 살펴보겠습니다.
먼저 Windows File Server용 Amazon FSx입니다. EFS 기억나시나요? EFS는 Linux 시스템을 위한 공유 POSIX 시스템이었는데요.
Windows용 FSx도 이와 비슷합니다. Windows와 Linux 컴퓨터에서 액세스할 수 있는 완전 관리형 Windows 파일 시스템 공유 드라이브를 제공하죠. Windows NTFS는 물론 SMB 프로토콜을 지원하며
Microsoft Active Directory 통합 기능과 ACL 그리고 사용자 할당 기능이 있습니다. 모든 Windows 시스템에서 쉽게 공유할 수 있는 파일 시스템을 제공하죠.
Linux EC2 인스턴스에 탑재할 수도 있어서 Windows와 Linux 모두에서 작동합니다. 하지만 Windows용 파일 시스템이라는 걸 기억하세요.
대규모 처리 용량을 갖추고 있어서 수십 GB/s, 수백만 IOP 그리고 수백 PB의 데이터를 처리할 수 있습니다.
Storage Options
- Windows용 FSx 스토리지 옵션에는 SSD가 있는데 이것은 지연 시간에 민감한 워크로드에 적합합니다. 데이터베이스, 미디어 처리 데이터 분석이 이에 해당하죠
- 또 다른 옵션으로는 HDD가 있습니다. 홈 디렉토리나 CMS 등과 같은 워크로드용 하드 드라이브이죠. 이 경우 지연 시간의 중요도는 낮습니다. 물론 SSD가 HDD보다 비싸죠.
Windows용 FSx는 VPN나 직접 연결 서비스를 써서 온프레미스 인프라에서도 액세스할 수 있습니다.
다중 AZ로 구성하여 가용성을 높일 수 있고
데이터를 Amazon S3에 매일 백업할 수도 있죠.

이제 Amazon FSx의 두 번째 종류인 Lustre용 Amazon FSx를 살펴봅시다.
Lustre는 대규모 컴퓨팅에 사용되는 분산 파일 시스템을 수행합니다.
Lustre라는 단어를 설명하면 이해가 되실 텐데요. Lustre는 Linux와 Cluster에서 파생된 단어로
고성능 컴퓨팅 즉, HPC에서 머신 러닝에 사용됩니다. Lustre용 FSx를 배우면서 알아두어야 할 키워드이고요.
비디오 처리, 재무 모델링 전자 설계 자동화와 같은 애플리케이션에 사용됩니다.
대규모 처리 용량을 갖추고 있어서 초당 100GB의 처리량과 수백만 IOPS 그리고 밀리 초 이하의 지연 시간을 제공합니다.
스토리지에는 두 가지 옵션이 있는데요
- SSD는 지연 시간이 매우 짧고 IOPS 집약적 워크로드나 작고 임의의 파일 작업에 적합하고
- HDD는 처리량이 많은 워크로드나 대용량이면서 순차적인 파일 작업에 적합합니다. 그리고 SDD가 HDD보다 더 비싸죠.
Amazon S3로 무결절성 통합이 가능한데요.
- 즉, FSx를 통해 S3를 파일 시스템으로 읽을 수 있다는 뜻이죠.
- 또한 FSx에서 Amazon S3로 출력값을 다시 쓸 수도 있어요. 이 내용은 시험에 나올 수도 있어요.
마지막으로 Lustre용 Amazon FSx는 VPN 또는 직접 연결을 통해 온프레미스 서버에서 사용할 수 있습니다.

여러분이 알아 두셔야 할 FSx 파일 시스템 배포 옵션에는
두 가지가 있는데요
바로 스크래치 파일 시스템과 영구 파일 시스템입니다
- 스크래치 파일 시스템은 임시 저장소이며
- 데이터는 복제되지 않습니다. 기본 서버가 실패하면 저장한 파일을 잃게 된다는 의미죠.
- 하지만 최적화 덕분에 버스트 처리량이 매우 높습니다. 영구 파일 시스템보다 성능이 6배나 높죠. 초당 처리량은 TiB당 200MB입니다. 상당히 높은 편이죠.
- 스크래치 파일 시스템은 단기간 데이터를 처리해야 하거나 데이터를 복제하지 않고 비용을 최적화하려고 할 때 사용됩니다.
FSx의 경우 컴퓨팅 인스턴스가 가용영역(AZ) 1과 2에 연결되고 Lustre용 FSx 스크래치 파일 시스템에는 이 도식에 표시된 것처럼 데이터 복사본이 하나만 있습니다. 마지막으로 데이터 리포지토리에 대한 기본 버킷을 선택적으로 추가할 수도 있습니다.
영구 파일 시스템은
- 장기 보관을 위한 스토리지이며
- 데이터는 동일한 가용성 내에서 복제됩니다. AZ 전체가 아니라 동일한 AZ 내에 복제되는 것이죠.
- 이건 다시 말해 기본 서버에 장애가 발생한 경우 알지 못하는 사이에 파일이 몇 분 이내로 대체된다는 걸 의미합니다.
- 영구 파일 시스템은 이름에서 알 수 있듯이 민감한 데이터를 오래 처리하거나 보관하는 데 사용됩니다.
아키텍처 측면에서 보면 동일합니다. 기억하시겠지만 Lustre용 FSx는 단일 AZ 내에서만 존재하며 Lustre용 FSx 영구 파일 시스템에는 두 개의 데이터 복사본이 있습니다. 하나의 데이터 볼륨에서 다른 데이터 볼륨으로 복제되는 거죠. 시험에서는 스크래치와 영구 파일 시스템 중 어떤 것을 선택해야 하는지 묻는 시나리오 질문이 출제될 거예요. 충분히 이해하셔야 하고요 도움이 되셨길 바라며 다음 강의에서 뵙죠.
174. Amazon FSx - 실습


175. 스토리지 Gateway 개요

AWS가 하이브리드 클라우드라는 걸 추진 중인데, 그게 무엇일까요?
- 바로 인프라의 일부는 AWS 클라우드에 두고
- 일부는 온프레미스에 있도록 하는 겁니다.
여러 가지 이유로 사용되는데
- 더 길어진 클라우드 마이그레이션 때문이거나
- 보안 요건
- 또는 규정 준수 요건 때문일 수도 있고
- 탄력 있는 워크로드 클라우드를 이용하기 위해서이기도 합니다. 대신 많은 부분이 온프레미스에 보관됩니다.
AWS에는 정말 좋은 서비스가 많은데 예를 들면 Amazon S3 같은 사유 스토리지 기술이 있습니다. EFS와는 다른, NFS 규정 준수 파일 시스템이지요. 그러면 어떻게 S3 데이터를 온프레미스로 나타낼 수 있을까요?
S3와 온프레미스 인프라 사이를 잇는 가교 역할을 하는 것이 AWS 스토리지 게이트웨이입니다.

그래서 AWS의 스토리지 클라우드 네이티브 옵션을 보면 블록 스토리지인 Amazon EBS와 EC2 인스턴스 스토어가 있고
파일 시스템인 Amazon EFS와 Amazon FSX가 있습니다.
그리고 객체 레벨 스토리지인 Amazon S3과 Amazon Glacier가 있지요.

스토리지 게이트웨이는 온프레미스 데이터와 S3의 클라우드를 연결합니다.
스토리지 게이트웨이의 사용 사례가 많은데
- 재해 복구, 백업 및 복원 및 계층화된 스토리지에 쓰입니다.
스토리지 게이트웨이의 세 가지 유형은 시험에 나올 수 있습니다
- 먼저 파일 게이트웨이
- 볼륨 게이트웨이,
- 그리고 테이프 게이트웨이입니다.
조금 후에 자세히 다루겠지만 스토리지 게이트웨이는 데이터를 Amazon EBS 또는 Amazon S3이나 Glacier로 가져옵니다.
시험에 대비해서 세 가지 게이트웨이의 차이점을 잘 알아야 합니다. 관련한 시나리오도 많이 나올 겁니다.

파일 게이트웨이는 NFS와 SMB 프로토콜을 사용하여 액세스 가능하도록 S3 버킷을 구성할 수 있고
S3 표준, S3 IA, 또한 S3 One Zone IA 등의 스토리지 클래스 유형을 지원합니다.
또한 각 파일 게이트웨이의 IAM 역할을 사용하는 버킷 액세스가 보호되며
가장 최근에 사용된 데이터는 파일 게이트웨이에 캐시됩니다.
파일 게이트웨이는 온프레미스의 여러 서버에 장착될 수 있습니다.
마지막으로 시험을 대비해 알아두어야 하는 것은 만약 사용자 인증이 필요할 경우 온프레미스의 Active Directory와 통합되어 사용자 인증을 실행할 수 있습니다.
더 자세한 이해를 위해 도면을 보겠습니다.
애플리케이션 서버는 NFS 프로토콜인 V3 혹은 V4.12를 통해 파일 게이트웨이와 통신하고 파일 게이트웨이는 가교가 되어 AWS 클라우드를 연결합니다. 클라우드 안에는 S3 표준과 S3 IA가 있고 Glacier도 사용 가능합니다. 파일 게이트웨이는 HTTPS를 통해 클라우드의 버킷들과 접속 및 통신하게 됩니다. 따라서 아까처럼 사용자 인증이 필요하고 Active Directory를 설정한 상태라면 Active Directory와 파일 게이트웨이 사이의 통합으로, 파일 게이트웨이 레벨의 인증을 제공합니다. 이렇게 Amazon S3으로 파일이 액세스 및 확장되기 때문에 파일 시스템에 매우 큰 스토리지를 제공하게 됩니다. 게다가 가장 많이 쓰인 파일은 파일 게이트웨이에 캐시되어 파일 액세스 지연시간을 낮추도록 도와주기도 합니다. 즉 이런 방식으로 백엔드에서 Amazon S3을 활용하여 온프레미스의 NFS 크기를 확장할 수 있는 겁니다.

다음은 볼륨 게이트웨이인데 S3의 iSCSI 프로토콜을 사용하는 블록 스토리지입니다.
다시 말해 EBS 스냅샷으로 백업되는 볼륨을 가지게 되는데 필요한 경우 온프레미스 볼륨을 복구하는 데 도움을 줍니다.
볼륨 게이트웨이는 두 종류가 있어요. 최근 데이터의 액세스 지연 시간을 줄일 수 있는 캐시 된 볼륨이 있고
전체 데이터셋이 온프레미스에서 제공되는, 저장된 볼륨이 있는데 Amazon S3에 백업이 예약됩니다.
여기 애플리케이션의 서버 백업이 필요한 경우입니다. 이 프로토콜을 사용해서 볼륨 게이트웨이를 얻으면 볼륨 게이트웨이는 S3이 지원하는 Amazon EBS 스냅샷을 생성합니다. 여기도 마찬가지로 볼륨 게이트웨이의 목표는 온프레미스 서버의 볼륨을 백업하는 것입니다.

테이프 게이트웨이란 회사가 물리적 테이프를 써서 테이프 백업 시스템을 사용한다고 했을 때
테이프 게이트웨이를 사용하더라도 그 과정은 똑같고, 대신 테이프가 클라우드에 백업됩니다.
가상 테이프 라이브러리인 VTL은 Amazon S3와 Glacier로 지원되며
기존 데이터를 백업할 때 테이프 기반 프로세스 및 iSCSI 인터페이스를 사용합니다.
백업 소프트웨어 판매 업체와 협업하기도 합니다.
도면을 보면 기업 데이터 센터에 테이프 기반 백업 서버가 있습니다. Amazon S3나 Glacier에 테이프를 저장하는 방식으로 테이프 게이트웨이가 클라우드에 접속합니다.

마지막으로 아까 보았던 도면에서와 같이 게이트웨이가 설치되는 곳은 기업 데이터 센터이고 기업 데이터 센터 내에서 실행되어야 합니다. 그런데 때로는 추가로 게이트웨이를 실행할 가상 서버가 없을 수 있습니다. 이런 경우의 옵션으로 AWS의 하드웨어를 이용하는데 스토리지 게이트웨이 하드웨어 어플라이언스라고 해요.
즉 온프레미스 가상화가 없으면 스토리지 게이트웨이 하드웨어 어플라이언스를 사용할 수 있습니다 Amazon.co m에서 주문 가능하죠.
하드웨어 어플라이언스 설치를 끝내면
즉 인프라에 미니 서버가 설치되면 파일 게이트웨이나 볼륨 게이트웨이 혹은 테이프 게이트웨이로 설정할 수 있게 됩니다.
물리적인 설치가 필요하며 올바르게 작동하려면 충분한 CPU, 메모리, 네트워크 SSD 캐시 리소스 등이 필요합니다.
유용하게 쓰이는 경우는 소규모 데이터 센터에서 매일 NFS 백업을 수행하지만 가상화가 불가능한 경우 등입니다.

스토리지 게이트웨이를 정리해 봅시다
시험에서는 문제를 자세히 읽어야 어떤 게이트웨이를 사용할지 알 수 있습니다.
온프레미스 데이터와 클라우드 사이에 브리지가 필요하다면 스토리지 게이트웨이가 답입니다.
네트워크 파일 시스템과 함께 Active Directory을 사용하는 선택적 사용자 인증이 필요하면 파일 게이트웨이입니다.
데이터는 백엔드의 S3으로 이동하겠지요.
볼륨, 블록 스토리지, 그리고 iSCSI 백업이 필요한 경우 볼륨 게이트웨이를 사용하면 EBS 스냅샷이 생성되어 Amazon S3의 지원을 받을 겁니다.
백업에 테이프 솔루션이 필요하면 테이프 게이트웨이를 사용합니다.
그리고 온프레미스 가상화 시스템이 없는 경우라면 소스 게이트웨이에서 하드웨어 어플라이언스를 주문하고 데이터 센터에 설치합니다.
176. Amazon FSx 파일 Gateway

이번 강의에서는 새로운 종류의 파일 게이트웨이를 잠시 살펴볼게요. Amazon FSx 파일 게이트웨이입니다.
Amazon FSx 파일 게이트웨이는 AWS에서 Windows 파일 서버 오퍼링을 위해 Amazon FSx로의 네이티브 액세스를 제공해요.
이 예시를 보면 AWS 클라우드에 Windows 파일 서버용 FSx가 실행 중이고 여러 파일 시스템이 있고 기업 데이터 센터가 여기로 액세스하려고 합니다. 기업 데이터 센터에서 클라우드로 직접 액세스를 할 수도 있지만 로컬 캐시 등의 이유 때문에 Amazon FSx 파일 게이트웨이를 사용하는 것이 조금 더 효율적입니다. 파일 게이트웨이는 프록시가 되고 클라우드의 파일 시스템에 직접 액세스할 것입니다.
이때 파일 게이트웨이의 기능이 정말 좋은데요. 바로 자주 액세스되는 데이터의 로컬 캐시입니다. FSx 파일 게이트웨이에 데이터가 캐시되기 때문에 기업 데이터 센터에서 자주 액세스되면 지연 시간도 줄어들게 됩니다. 파일 게이트웨이를 사용할 때 가장 좋은 점이죠.
Windows에 완전히 호환되어 SMB 프로토콜을 사용할 수 있고 NTFS 통합 및 Active Directory 등이 있습니다.
또 이런 경우에 유용한데 예를 들어 그룹 파일 공유나 기업 데이터 센터의 홈 디렉터리를 백엔드에서 Amazon FSx로 백업하려는 경우입니다.
즉 FSx 파일 게이트웨이를 사용하는 진짜 이유는 FSx나 파일 서버에서 자주 액세스되는 데이터에 대해 로컬 캐시를 얻도록 하는 겁니다.
177. 스토리지 Gateway 실습
178. AWS 전송 제품군

이번 강의에서는 AWS 전송 제품군을 살펴봅시다 말하자면 이런 겁니다
Amazon S3 또는 EFS의 안팎으로 데이터를 전송하려고 하는데 대신 S3 APIs는 사용하고 싶지 않을 때 EFS 네트워크 파일 시스템도 사용하지 않고 FTP 프로토콜만 사용하려는 경우에 말이죠. 바로 이런 경우에 AWS 전송 제품군을 사용합니다.
세 가지 프로토콜을 지원하는데요
- 우선 FTP의 AWS 전송을 지원합니다. FTP는 파일 전송 프로토콜이라는 뜻이고요
- SSL을 통한 파일 전송 프로토콜인 FTPS는 암호화된 형태입니다.
- 또는 SFTP가 지원되는데 이건 보안 파일 전송 프로토콜입니다. 전부 자세하게 알 필요는 없고요. FTP는 암호화되지 않는 반면에 FTPS와 SFTP는 전송 중에 암호화된다는 것만 알아두세요. FTP 프로토콜을 사용해서 S3 혹은 EFS에 업로드할 수 있습니다.
전송 제품군은 완전 관리형 인프라이며 확장성, 안정성이 높고 가용성 또한 높다는 것이 특징입니다. 따라서 이런 성능에 대해 다 다룰 거고요.
가격 책정은 이렇습니다 시간당 프로비저닝된 엔드 포인트 비용에 전송 제품군 안팎으로 전송된 데이터의 GB당 요금을 더합니다.
또 서비스 내에서 사용자 자격 증명을 저장 및 관리할 수도 있고요.
다음과 같은 기존의 인증 시스템과 통합할 수도 있습니다. Microsoft Active Directory 또는 LDAP, Okta, Amazon Cognito 또는 사용자 지정 소스입니다.
사용 사례는 물론 Amazon S3나 EFS의 FTP 인터페이스를 갖기 위해서입니다. 파일 공유 및 공개 데이터셋 공유를 위해 그리고 CRM, ERP 등을 하기 위해서죠.

도면을 보면서 이해해 봅시다
전송 제품군에는 세 가지 종류가 있습니다. 사용자는 FTP의 엔드 포인트를 통해 직접 액세스하거나 선택적으로 Route 53라는 이름의 DNS를 사용하여 FTP 서비스에 고유의 호스트 이름을 제공할 수 있습니다.
그리고 FTP 서비스의 전송에는 IAM 역할이 있어서 Amazon S3나 Amazon EFS의 파일을 보내거나 읽도록 합니다. 이 과정은 손쉽게 이루어지며 많은 설정이 필요 없습니다.
마지막으로 전송 제품군 서비스의 보안을 위해 외부 인증 시스템을 통해서 사용자를 인증할 수 있는데 그런 시스템에는 Active Directory와 LDAP 아니면 지난 슬라이드에서 언급했던 것들 등이 있습니다.
?????????????



179. 모든 AWS 스토리지 옵션 비교

이번 강의에서는 AWS의 모든 스토리지 옵션을 비교합니다. 굉장히 많은 내용이기 때문에 한 걸음 물러서서 개괄적으로 내용을 파악하는 게 좋을 겁니다.
S3는 객체 스토리지이며 또한 서버리스입니다. 용량을 미리 프로비저닝할 필요 없고 많은 데이터베이스 서비스와 긴밀하게 통합됩니다. 굉장하죠,
그리고 Glacier는 객체 아카이브를 위한 곳입니다. 객체를 오랫동안 저장하고 싶고 회수할 일은 매우 드물 때 Glacier를 쓰는 거죠. 여기서 객체를 회수할 때는 우리에게 다시 가져오기까지 많은 시간이 걸리는데 왜냐하면 객체가 아카이브되었기 때문입니다.
EFS는 일래스틱 파일 시스템으로 Linux 인스턴스용의 네트워크 파일 시스템입니다. POSIX 파일 시스템이니 다시 Linux용이라는 말이 되겠죠. 모든 EC2 인스턴스에서 동시에 액세스 가능하며 AZ 전반에 걸쳐 공유됩니다.
Windows용 FSx는 EFS와 같지만 Windows를 위한 거죠. 즉 Windows 서버를 위한 네트워크 파일 시스템입니다.
Lustre용 FSx는 Linux와 클러스터로 고성능 컴퓨팅이 가능한 Linux 파일 시스템이죠. 여기에서 HPC가 실행됩니다. 상상 이상으로 IOPS가 높고 용량도 엄청납니다. 그리고 백엔드에서 S3와 통합됩니다.
EBS 볼륨은 네트워크 스토리지로 한 번에 EC2 인스턴스 하나만 액세스됩니다. 또 생성된 특정 가용 영역 내부에 바인딩됩니다. AZ를 변경하고 싶다면 스냅샷을 생성해서 해당 스냅샷을 이동시키고 거기에서 볼륨을 만들어야 합니다
인스턴스 스토리지는 EC2 인스턴스의 물리적 스토리지입니다. 그래서 하드웨어에 연결되어 있기 때문에 EBS보다 훨씬 높은 IOPS를 가지게 됩니다, 기억하시겠지만 EBS 볼륨은 최대 16,000 IOPS io1에선 최대 64,000 IOPS인데 인스턴스 스토리지는 EC2 인스턴스와 물리적으로 연결되기 때문에 수백만 IOPS도 가능해 매우 높은 겁니다. 하지만 EC2 인스턴스가 중단되면 해당 스토리지가 영구적으로 손실될 위험이 있습니다.
Storage Gateway는 온프레미스에서 AWS로 파일을 전송하는데요 여기에는 File Gateway, 캐시 및 저장을 위한 Volume Gateway 또 Tape Gateway가 있고 각각의 사용 사례가 다릅니다.
마지막으로 Snowball과 Snowmobile은 대용량 데이터를 S3의 클라우드로 물리적으로 옮깁니다.
그리고 데이터베이스는 데이터를 저장하는 방법입니다. 보다 특정한 워크로드에 사용되는데 일반적으로 인덱싱 및 쿼리와 함께 사용됩니다. 데이터베이스를 다루는 섹션에서는 그 종류를 더 깊게 다루고 있습니다.
보다시피 AWS에 아주 다양한 사용 사례와 옵션이 있는데
이것으로 잘 이해되었기를 바랍니다
그럼 시험에서 적절한 때에 각각의 의미를 제대로 파악할 수 있을 거예요
여기까지고요 다음 강의에서 뵙겠습니다



