70. 고가용성 및 스케일링성


확장성은 애플리케이션 시스템이 조정을 통해 더 많은 양을 처리할 수 있다는 의미입니다
확장성의 종류는 두 가지인데요
1. 우선 수직 확장성이 있고
2. 탄력성이라고 불리기도 하는 수평 확장성이 있습니다
확장성과 고가용성은 서로 다른 개념입니다. 연관된 개념이지만 서로 다르죠. 둘의 차이점에 대해 자세히 살펴본 후에 이들이 실제 사례에서는 어떻게 사용이 되는지 콜 센터를 재미있는 예시로 들어 알아 봅시다

먼저 수직 확장성입니다
수직 확장성은 인스턴스의 크기를 확장하는 것을 의미합니다. 전화 교환원을 예로 들어 보죠. 신입 교환원을 이제 막 고용했다고 합시다. 훌륭한 직원이지만 1분에 전화를 다섯 통밖에 받지 못 하죠.
그리고 회사에는 경력직 교환원도 있습니다 훨씬 더 일을 잘 하죠. 1분에 전화를 열 통 받을 수 있습니다. 신입 교환원을 그냥 경력직 교환원으로 확대한 겁니다. 더 빠르고 능숙해졌죠
이게 수직 확장성입니다
보시다시피 능력치가 올라갔죠. EC2를 쓸 때 애플리케이션이 t2.micro로 구동된다면 이 애플리케이션을 확장해서 t2.large에서 구동하게끔 만들고자 하는 거죠.
그러면 이런 수직 확장성을 언제 사용하게 되는 걸까요? 데이터베이스와 같이 분산되지 않은 시스템에서 흔히 사용됩니다. RDS나 ElastiCache 등의 데이터베이스에서 쉽게 찾아볼 수 있죠. 이 서비스들은 하위 인스턴스의 유형을 업그레이드해 수직적으로 확장할 수 있는 시스템들입니다. 하지만 일반적으로 확장할 수 있는 정도에는 한계가 있는데요. 하드웨어 제한이 걸려 있죠. 그래도 수직 확장성은 다양한 경우에 유용합니다
그럼 이번엔 수평 확장성을 한 번 살펴보죠
수평 확장성이란 애플리케이션에서 인스턴스나 시스템의 수를 늘리는 방법입니다. 다시 콜 센터 예시로 설명을 드리죠. 과중한 업무를 소화하고 있는 교환원이 있다고 해봅시다. 이 경우 수직적인 확장이 아니라 그냥 교환원을 한 명 더 고용해서 두 배의 작업량을 처리하게 하는 거죠 세 번째 교환원도 고용하고 교환원을 여섯 명 고용하면 더 좋겠죠. 콜 센터를 수평 확장한 겁니다.
수평 확장을 했다는 건 분배 시스템이 있다는 걸 의미합니다. 웹이나 현대적 애플리케이션은 대부분 분배 시스템으로 이루어져 있죠. 하지만 모든 애플리케이션이 분배 시스템인 건 아닙니다. 요즘은 Amazon EC2와 같은 클라우드 제공 업체 덕분에 수평적인 확장이 더욱 수월해진 것 같습니다.
그냥 웹 페이지에서 우클릭만 하면 되거든요. 그럼 순식간에 새 EC2 인스턴스가 생기고 애플리케이션을 수평적으로 확장할 수 있거든요.
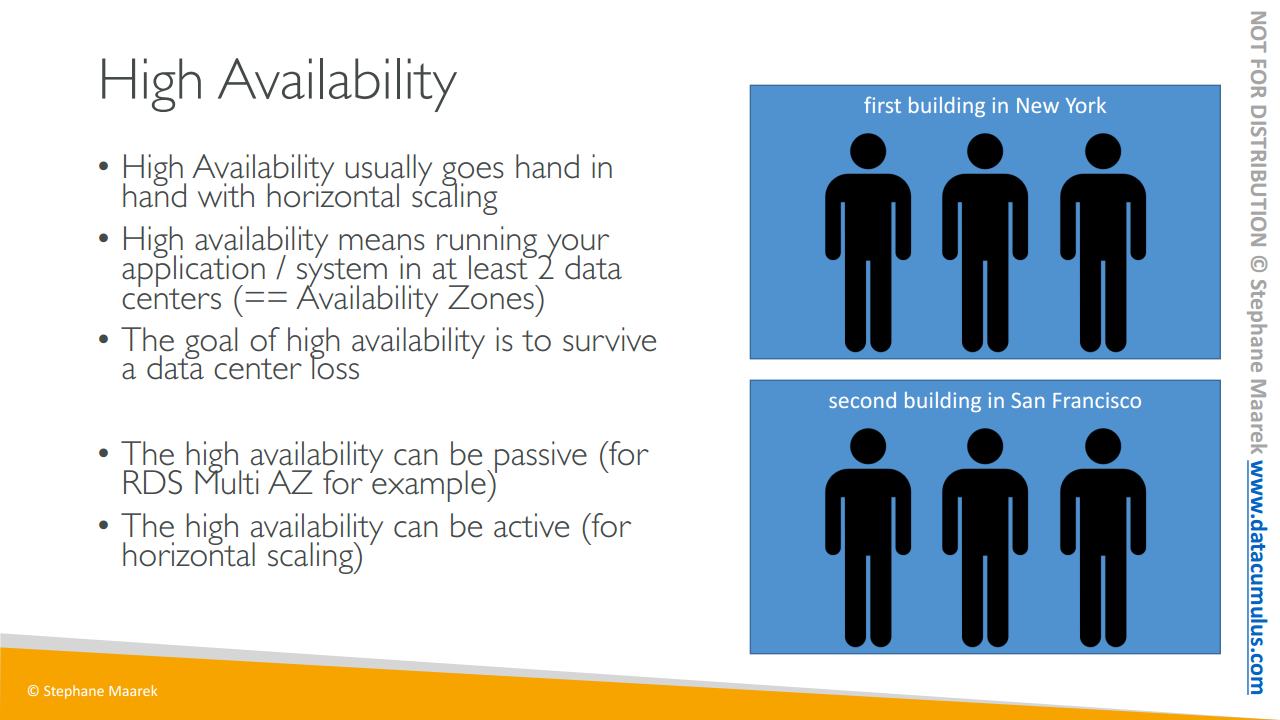
이번에는 고가용성을 봅시다
고가용성은 보통 수평 확장과 함께 사용되는 개념이지만 늘 그런 것은 아닙니다. 고가용성이란 애플리케이션 또는 시스템을 적어도 둘 이상의 AWS의 AZ나 데이터 센터에서 가동 중이라는 걸 의미합니다. 고가용성의 목표는 데이터 센터에서의 손실에서 살아남는 것으로 센터 하나가 멈춰도 계속 작동이 가능하게끔 하는 거죠.
다시 전화 교환원 예를 들어 봅시다. 뉴욕에 있는 첫 번째 지사에 세 명의 교환원이 있고 미국의 다른 지역인 샌프란시스코에 있는 두 번째 지사에 다른 세 명의 교환원이 있다고 해보죠. 뉴욕 지사의 인터넷과 전화 연결이 끊어져 업무가 불가능하지만 괜찮습니다. 샌프란시스코 지사 사무실의 연결은 끊기지 않아서 여전히 전화 업무 처리가 가능하거든요. 이런 경우에, 이 콜센터는 가용성이 높다고 할 수 있죠.
고가용성도 수동적일 수 있습니다. 예를 들어 RDS 다중 AZ를 갖추고 있다면 수동형 고가용성을 확보한 것이죠
하지만 활성형도 될 수 있습니다. 수평 확장을 하는 경우가 그렇죠. 뉴욕에 있는 사무실 두 개가 모든 전화 업무를 처리한다면 모든 전화가 동시에 처리되겠죠.

EC2에는 이게 어떤 의미일까요?
역시 수직 확장입니다 인스턴스의 크기를 늘리는 거죠. 확장(스케일 업), 축소(스케일 다운)를 의미합니다. 예를 들어 현재 AWS에서 사용 가능한 가장 작은 인스턴스는 t2.nano로 0.5GB 램에 1 vCPU이고 가장 큰 인스턴스는 u-t12tb1.metal로 12.3TB의 램을 갖춘 450 vCPUs를 갖췄죠. 꽤 큰 인스턴스죠, 물론 시간이 지나면 더 큰 것도 나오겠지만요. 이렇게 수직 확장을 통해 매우 작은 인스턴스부터 대규모로 확장이 가능합니다
수평 확장은 인스턴스의 수를 늘린다는 뜻인데 AWS 용어로는 스케일 아웃과 스케일 인이라고 합니다. 인스턴스의 수가 늘어나면 스케일 아웃이고요. 수를 줄이면 스케일 인이죠. 다른 스케일링 그룹이나 로드 밸런서에도 사용합니다.
마지막으로 고가용성은 동일 애플리케이션의 동일 인스턴스를 다수의 AZ에 걸쳐 실행하는 경우를 의미하죠. 다중 AZ가 활성화된 자동 스케일러 그룹이나 로드 밸런서에서도 사용됩니다.
71. Elastic Load Balancing(ELB) 개요
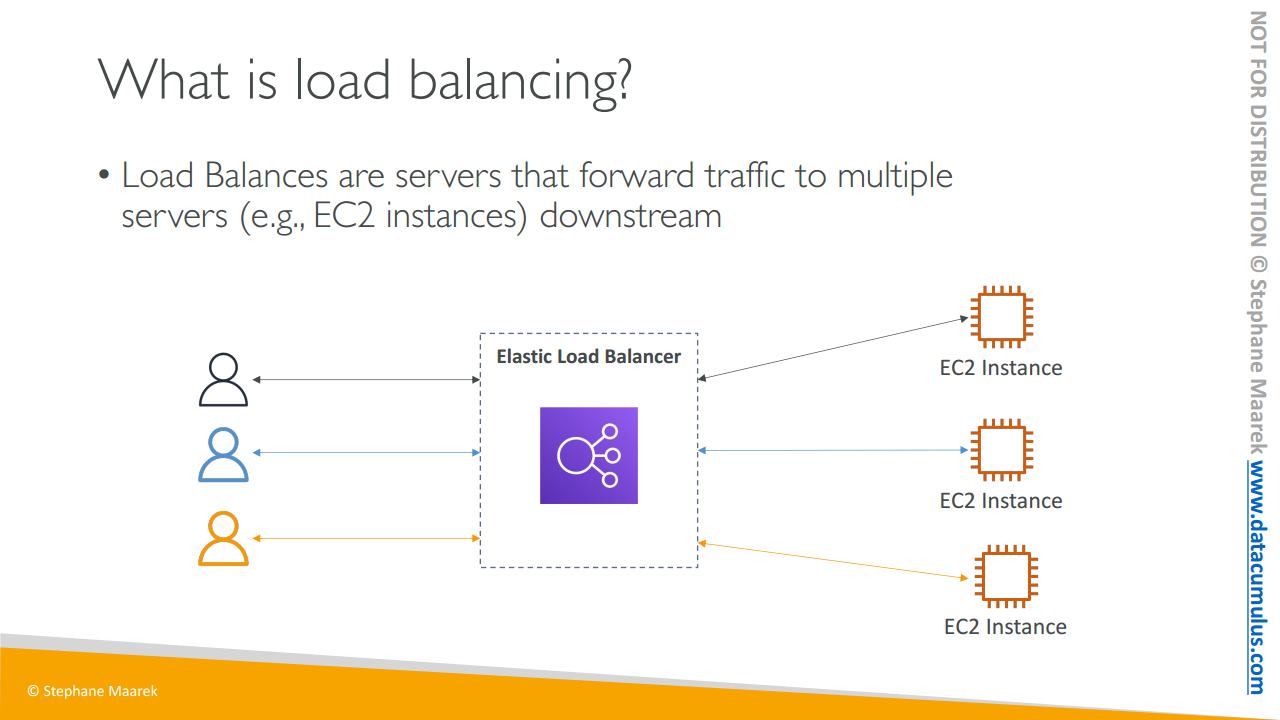
이번에는 로드 밸런싱에 대해 배워 봅시다. 로드 밸런싱이 대체 뭔지 궁금하실 겁니다
로드 밸런서는 서버 혹은 서버셋으로 트래픽을 백엔드나 다운스트림 EC2 인스턴스 또는 서버들로 전달하는 역할을 합니다. 예를 들어 EC2 인스턴스가 세 개 있다고 합시다. 인스턴스 앞에는 일래스틱 로드 밸런서가 있고 뒤에는 서버셋이 있죠. 이 예시에서 세 유저들은 일래스틱 로드 밸런서로 바로 연결됩니다.
첫 번째 유저의 로드는 백엔드 EC2 인스턴스 중 하나로 연결이 됩니다. 그리고 로드 밸런싱 덕분에 이때 다른 유저가 일래스틱 로드 밸런서에 연결된 경우 이 로드는 다른 EC2 인스턴스로 보내지게 되죠.
그리고 마지막으로 세 번째 유저가 일래스틱 로드 밸런서에 연결되면 로드 밸런싱에 의해 세 번째 EC2 인스턴스로 보내질 겁니다. 그러니 더 많은 유저가 연결될 수록 EC2 인스턴스로 가는 부하가 더욱 분산되는 거죠. 하지만 유저는 자신들이 백엔드 인스턴스 중 어떤 것에 연결되어 있는지 알 수 없습니다. 유저들은 자신들이 일래스틱 로드 밸런서에 연결되면 한 엔드 포인트에 연결이 된다는 것만 알고 있죠..

그럼 왜 로드 밸런서가 필요할까요?
부하를 다수의 다운스트림 인스턴스로 분산하기 위해서죠. 방금 말했듯 애플리케이션에 단일 액세스 지점(DNS)을 노출하게 되고 다운스트림 인스턴스의 장애를 원활히 처리할 수 있죠. 로드 밸런서가 상태 확인 메커니즘으로 어떤 인스턴스로 트래픽을 보낼 수 없는지 확인해 주거든요.
인스턴스의 상태를 확인할 수 있는 거죠. SSL 종료도 할 수 있으니 웹 사이트에 암호화된 HTTPS 트래픽을 가질 수 있죠. 쿠키로 고정도를 강화할 수 있고 영역에 걸친 고가용성을 가지며 클라우드 내에서 개인 트래픽과 공공 트래픽을 분리할 수 있습니다

일래스틱 로드 밸런서는 관리형 로드 밸런서이기도 합니다. AWS가 관리하며, 어떤 경우에도 작동할 것을 보장하죠. AWS가 업그레이드와 유지 관리 및 고가용성을 책임지며 그리고 로드 밸런서의 작동 방식을 수정할 수 있게끔 일부 구성 놉도 제공합니다. 일래스틱 로드 밸런서는 무조건 쓰는 편이 좋습니다. 자체 로드 밸런서를 마련하는 것보다 저렴하고 자체 로드 밸런서를 직접 관리하려면 확장성 측면에서 굉장히 번거롭기 때문이죠.
또한, 로드 밸런서는 다수의 AWS의 서비스들과 통합되어 있습니다. EC2 인스턴스와도 물론 통합이 가능하며 나중에 배우겠지만 스케일링 그룹 Amazon ECS와 인증서 관리(ACM) CloudWatch, Route 53, AWS WAF, AWS Global Accelerator 등 앞으로 더 늘어날 겁니다.
그러니 AWS 로드 밸런싱에는 무조건 일래스틱 로드 밸런서를 쓰는 것이 좋습니다.

상태 확인에 대해 잠깐 언급했었죠. 상태 확인은 일래스틱 로드 밸런서가 EC2 인스턴스의 작동이 올바르게 되고 있는지의 여부를 확인하기 위해 사용됩니다. 만약 제대로 작동하는 중이 아니라면 해당 인스턴스로는 트래픽을 보낼 수 없기 때문에 로드 밸런서에겐 인스턴스의 상태가 아주 중요하죠 그리고 상태 확인은 포트와 라우트에서 이뤄집니다.
화면에 있는 예시의 프로토콜은 HTTP이고 포트는 4567, 엔드 포인트는 /health입니다. 이런 라우트가 애플리케이션의 입장에서는 애플리케이션의 상태를 확인하기 쉬울 수 있겠죠. 만약 EC2 인스턴스가 괜찮다는 신호, 즉 HTTP 상태 코드로 200으로 응답하지 않는다면 인스턴스 상태가 좋지 않다고 기록됩니다. 그리고 일래스틱 로드 밸런서는 그쪽으로 트래픽을 보내지 않게 되죠.

AWS에는 네 종류의 관리형 로드 밸런서가 있습니다
클래식 로드 밸런서는 기존 세대나 V1이라고도 하며 2009년에 만들어진 CLB라고 불리는데요. HTTP, HTTPS, TCP, SSL와 secure TCP를 지원합니다. 하지만 AWS는 이제 이 로드 밸런서의 사용을 권장하지 않고 있기 때문에 콘솔에서 더 이상 사용할 수 없는 것으로 나오지만 사용이 가능하기는 합니다.
신형 로드 밸런서도 있습니다. 2016년에 출시된 애플리케이션 로드 밸런서인 ALB입니다. HTTP, HTTPS와 WebSocket 프로토콜을 지원하죠.
2017년에 새로 출시된 네트워크 로드 밸런서도 있는데 TCP, TLS, secure TCP와 UDP 프로토콜을 지원하죠.
그리고 2020년에 나온 게이트웨이 로드 밸런서도 있습니다GWLB라고 불리며 네트워크층에서 작동하므로 3계층과 IP 프로토콜에서 작동하는 거죠.
결론적으로, 더 많은 기능을 가지고 있는 신형 로드 밸런서를 사용하시는 것이 권장됩니다.
일부 로드 밸런서들은 내부에 설정될 수 있어 네트워크에 개인적 접근이 가능하고 웹사이트와 공공 애플리케이션 모두에 사용이 가능한 외부 공공 로드 밸런서도 있죠.

로드 밸런서를 둘러싼 보안에 대해서도 알고 계셔야 하는데요. 유저는 HTTP나 HTTPS를 사용해 어디서든 로드 밸런서에 접근이 가능한데요. 따라서 보안 그룹의 규칙은 화면에 보이는 이런 형태가 될 겁니다. 포트 범위는 80, 혹은 443이고 소스는 0.0.0.0/0인데 어디든 가능하다는 뜻이죠. 로드 밸런서에 유저의 연결을 허용하는 것이죠.
여기서 EC2 인스턴스는 로드 밸런서를 통해 곧장 들어오는 트래픽만을 허용해야 하기 때문에 EC2 인스턴스의 보안 그룹 규칙은 조금 달라야 할 겁니다. 포트 80에서 HTTP 트래픽을 허용하며 소스는 IP 범위가 아니라 보안 그룹이 되죠. EC2 인스턴스의 보안 그룹을 로드 밸런서의 보안 그룹으로 연결하는 겁니다.
이렇게 함으로써 EC2 인스턴스는 로드 밸런서에서 온 트래픽만을 허용하게 되는 다시 말해 강화된 보안 메커니즘이 되는 거죠.
72. Classic Load Balancers

클래식 로드 밸런서부터 살펴봅시다. 시험에서 중요하게 다루는 부분은 아니지만 출제될 가능성은 있고, 여전히 아주 유효한 로드 밸런서이기도 하죠.
이 로드 밸런서는 TCP나 트래픽 아니면 HTTP와 HTTPS를 지원합니다. TCP는 4계층으로 HTTP/HTTPS는 7계층인데요. 계층에 대해선 자세히 모르셔도 됩니다. TCP는 4계층, HTTP와 HTTPS가 7계층이라는 것만 알아 두세요
상태 확인은 TCP 또는 HTTP 기반으로 이루어집니다. 로드 밸런서, 즉 클래식 로드 밸런서로부터 고정 호스트 이름을 부여받습니다.
이번 시간에는 클라이언트가 HTTP 리스너를 통해 클래식 로드 밸런서에 연결되게 될 텐데요. 내부에서는 CLB가 트래픽을 EC2 인스턴스로 다시 전송하게 되죠. 그럼 이제 콘솔 내에서 설정 방법을 알아보겠습니다
73. Classic Load Balancers 실습
이번 시간에는 CLB를 생성해 볼 텐데요
가장 먼저 인스턴스부터 실행해야겠죠
빠르게 해봅시다 이전과 마찬가지로
Amazon Linux 2를 선택하고
t2.micro를 선택해서 이전과 같이 웹 서버 구성을 하겠습니다
이쪽에서 전체 내용을 복사해 통째로 붙여 줍니다
Add Storage를 누르고요 다 잘 됐네요
태그 추가, 보안 그룹
기존의 보안 그룹을 사용할 거니까
launch-wizard-1이고요
Reviwe and Launch를 누르면
EC2 인스턴스가 생성됩니다
이 EC2 인스턴스는 웹 서버를 갖게 될 겁니다
시작이 되는 동안 이 부분은 그대로 두겠습니다
그리고 왼쪽 메뉴에서 로드 밸런서로 이동합니다
로드 밸런서 콘솔에서 첫 번째 로드 밸런서를 생성해 보죠
네 가지 옵션이 가능한데요
애플리케이션 로드 밸런서와 네트워크 로드 밸런서
게이트웨이 로드 밸런서와 클래식 로드 밸런서가 있습니다
보시다시피 클래식은 구식이어서 요즘은 잘 사용하지 않아요
생성이 가능은 하지만 사용이 권장되지는 않죠
ALB와 NLB는 다음 강의에서 다룰 것이고
지금으로서 게이트웨이 로드 밸런서는 범위에 포함되지 않죠
그럼 클래식 로드 밸런서에서 Create을 눌러 봅시다
my-demo-clb라고 이름을 붙여 주고요
My Default VPC 내에 생성합니다
내부 로드 밸런서로 만들어 개인용으로 사용할 수도 있죠
우리는 컴퓨터에서 접근해야 하니
이 칸은 체크하지 않고 넘어 갑시다
고급 VPC 구성 칸도 체크하지 않을게요
리스너 구성의 경우에는
클래식 로드 밸런서가 HTTP 트래픽을 허용할 수 있도록
포트 80의 HTTP를 허용하게끔 설정합니다
그러면 포트 80을 통해 EC2 인스턴스로 가게 되고
HTTP 프로토콜로도 마찬가지죠 좋습니다
다음으로는 보안 그룹 설정으로
클래식 로드 밸런서를 위한 새로운 보안 그룹을 생성한 뒤
my-first-load- balancer-sg라고 부르겠습니다
설명은 그대로 두고요
모든 곳에서 오는 HTTP 트래픽을 허용해야 하니
유형은 HTTP, 포트는 80으로 0.0.0.0/0은 IPv4 주소라면
어디에서든 올 수 있다는 의미죠
IPv4와 IPv6 모두를 포함하려면 Anywhere을 선택하면 되지만
클래식 로드 밸런서는 IPv6를
지원하지 않기 때문에 여기 IPv6가 표시되지 않네요
그러면 다 끝났습니다
이제 보안 설정을 구성할 수 있죠
HTTPS나 SSL을 사용 중이지 않기 때문에 경고가 뜹니다
이 섹터에서는 이동 중인 트래픽을
암호화하지 않을 거니까 무시하셔도 괜찮습니다
다음은 상태 확인이죠
인스턴스에서 어떤 것들이 확인될지를 살펴봐야 합니다
상태 확인은 프로토콜 HTTP와
80번 포트에 있는 EC2 인스턴스를 확인할 겁니다
경로는 /index-html이 되죠
이게 작동될지 한 번 봅시다
이 공인 IPv4를 복사해서
붙여넣고 열어 볼게요
Hello World라는 문구가 표시되네요
이 경로에 /index.html라는 경로를 추가해 보면 어떨까요?
Enter를 치면 조금 전과 똑같은 URL이 표시됩니다
핑 경로가 잘 작동 중인 거죠
슬래시 핑 경로도 잘 작동 중이고요
여긴 슬래시만 둬도 됩니다
가령 /foobar처럼 존재하지 않는 경로를 입력하고
Enter를 한번 눌러 볼게요
그러면 에러가 뜨네요
이렇게 /foorbar로 상태 확인을 하면
상태가 좋지 않다고 보고될 겁니다
그러니 정상 작동이 되는 경로인 슬래시(/) 등을 사용해야 합니다
그냥 슬래시만 넣으면 URL이 올바르게 나오고
EC2 인스턴스에 Hello World가 뜨죠
좋습니다
상태 확인에는
타임아웃도 구성해야 하는데 5초가 적당합니다
상태 확인 빈도를 지정해야 하는데요
3초로 지정해 줍시다
몇 번을 확인한 후 비정상으로 판단할 것인가?
빈도를 5초로 바꿉시다
에러가 사라졌네요
인스턴스를 비정상으로 판단하기까지
몇 회의 상태 확인 실패가 필요한가?
2회면 적당합니다
인스턴스를 정상으로 간주하기 위해
몇 번을 확인할 것인가?
3 정도의 작은 숫자로 둡시다
즉, 세 번 확인해서 정상이면 인스턴스는 정상인 것이고
연속으로 두 번 비정상이 나오면 비정상으로 간주되는 거죠
다음으로 EC2 인스턴스를 추가해야 합니다
여기 이 EC2 인스턴스를 추가할 텐데요
Add Tags를 누르고 Create를 눌러 줍니다
그럼 첫 번째 클래식 로드 밸런서가 생성되어야 하는데
타임아웃은 확인 간격보다 짧아야 한다고 하네요
돌아가서 고쳐 줍시다
응답 타임아웃이 상태 확인 간격보다 짧아야만 하기 때문에
타임아웃을 4초로 설정하고
다시 Create를 눌러 주면 생성이 됐습니다
클래식 로드 밸런서가 성공적으로 생성된 겁니다
여기 생성된 클래식 로드 밸런서가 보이죠
활성화되기까지 조금 기다려야 하니까
영상을 잠깐 여기서 멈췄다가 활성화가 된 후 다시 돌아오겠습니다
지금 보시다시피 인스턴스가 작동하고 있지 않은데요
정보를 확인하면, 인스턴스 등록이 아직 진행 중이라고 하네요
이렇게 인스턴스가 작동하지 않는다면
질문을 하시기 전에 잠깐 기다려 보세요
이제 InService 작동 중으로 바뀌었죠
클래식 로드 밸런서가 작동 중이라는 뜻입니다
만약 1에서 2분 내로 작동이 시작되지 않는다면
가능한 원인이 몇 가지 있습니다
지금 당장은 전부 잘 작동하는 것 같네요
아직 Q&A에 질문을 올릴 단계는 아니죠
주소창에 클래식 로드 밸런서의 DNS 이름을 입력해 열어 주면
EC2 인스턴스에서 Hello World가 표시되죠
공공 IP를 사용했을 때도 마찬가지였습니다
즉, 클래식 로드 밸런서가 제대로 작동하고 있다는 뜻이죠
하지만 만약 제대로 작동되고
있지 않다면, 즉 인스턴스 상태가 비정상이라면 어떨까요?
보안 그룹 때문에 인스턴스의 상태가 비정상일 수 있습니다
보안 그룹으로 이동해
launch-wizard-1에서
이 HTTP 규칙들을 제거해 봅시다
HTTP 규칙을 삭제하고 규칙을 저장합니다
이렇게 규칙을 없앰으로써 여기 있는 인스턴스는
공공 인터넷은 물론이고
개인 인터넷에서도 접근을 차단할 겁니다
해당 보안 그룹에 유효한 포트 80이 없는 상태이기 때문이죠
즉, 이 예시에서는
인스턴스가 작동하지 않는다고 바로 표시가 될 겁니다
보시다시피 작동이 안 되고 있네요
이런 이유로 인스턴스가 작동하지 않을 수도 있고
인스턴스가 작동하지 않는 또 다른 이유로는
Hello World 자체의 문제가 있죠
부트스트랩 문구가 바르게 실행되지 않은 겁니다
이 두 가지가 인스턴스 미작동의 원인일 수 있습니다
이제 다시 인스턴스로 돌아가서
인바운드 규칙을 HTTP, 포트 80에서
0.0.0.0/0으로 IPv4 상 어디에서든 받는 걸로 지정하면
공공 IP와 클래식 로드 밸런서 모두에서
인스턴스로 접속이 가능해집니다
지금은 안 되네요 인스턴스가 다시 작동하기까지
15초 정도를 기다려야 하거든요
다시 작동 중이네요
새로 고침하면 작동합니다
문제는 EC2 인스턴스로의 접속이 직접적으로도, 클래식 로드 밸런서를
통해서도 가능하다는 건데요
이런 경우 보안을 강화하고자 합니다
이럴 때 보안 그룹 내에 굉장히 멋진 설정이 있는데요
인바운드 규칙을 80번 포트에서 HTTP를 허용하도록 지정하되
모든 주소를 허용하는 게
아니라, 로드 밸런서의 보안 그룹에서만 허용을 하는 거죠
my-first-load-balanc... 보안 그룹이죠
이렇게 EC2 인스턴스의 보안 그룹으로 로드 밸런서 보안 그룹에서
오는 모든 트래픽을 허용하게끔 설정할 수 있습니다
설명에는 'ELB에서 오는 트래픽만 허용하기' 라고 입력합니다
ELB는 인스턴스에 접근이 가능해야 하지만, 유저들의 직접적인
인스턴스 접근은 차단하기 위해서죠
이제 이 페이지를 새로 고침하면 무한 로딩이 표시될 겁니다
이 창에서는 새로 고침을 해도 여전히 접근이 가능하죠
이제 EC2 인스턴스에는 로드 밸런서를 통해서만 접근이 가능해진 겁니다
보안이 강화된 거죠 AWS에서 굉장히 흔히 쓰이는 방식입니다
그럼 이제 다수의 인스턴스를 통해 로드 밸런싱의 진정한 파워를 보여 드리죠
이 템플릿에서 우클릭으로 Launch instance from template를 선택
이런, 그게 아니라 우클릭 메뉴에서 Launch instance를 선택해
t2.micro를 사용해 볼게요
인스턴스 세부정보는 그대로 둬도 됩니다
이전과 마찬가지로 유저 데이터를 불러와 주면 되죠
붙여넣고 Add Storage를 눌러 다음으로 넘어 갑니다
Add Tags, Security Group를 선택한 다음
launch-wizard-1을 보안 그룹으로 지정합니다
Launc 네, 키 페어도 있죠
한 인스턴스는 실행이 됐고 하나 더 만들 수 있죠
Launch Instancef를 다시 선택해
선택하고 넘어가서 t2.micro로 하고요
좀 빠르게 넘어 갈게요
유저 데이터를 붙여 넣고
저장소도 됐고요
보안 그룹은 launch-wizard-1
Review and Launch, Launch 됐습니다
이제 EC2 인스턴스 세 개가 실행된 상태입니다
각 인스턴스들은 Hello World 문구를 가지게 될 거고요
그럼 이제 이 인스턴스들을 클래식 로드 밸런서에 등록해야 합니다
로드 밸런서로 이동해서
인스턴스를 수정해 두 개 새 인스턴스를 추가해 줍니다
이제 클래식 로드 밸런서에는 세 개의 인스턴스가 등록되어 있죠
두 개는 아직 부팅이 되는 중이라 작동하지 않고 있습니다
작업을 성공적으로 완료하려면 EC2 인스턴스에
데이터 스크립트를 넣어줘야 합니다
그리고 EC2 인스턴스 등록이 완료되면
로드 밸런서에 의해 작동이 시작될 겁니다
다시 한 번, 인스턴스가 계속해서 작동하지 않는다면
유저 데이터 스크립트 오류 또는 보안 그룹 문제입니다
같은 보안 그룹에 속한 인스턴스들 중 일부는
작동하고 일부는 그렇지 않다면
보안 그룹 문제는 아닌 겁니다
완료될 때까지 잠시 기다려 보겠습니다
이제 인스턴스 세 개가 모두 작동 중이며
두 개의 가용 영역에 걸쳐 있습니다
us-east-2a와 us-east-2c죠
이제 로드 밸런서로 돌아가서 새로 고침을 하면
새로 고침을 할 때마다 새로운 EC2 인스턴스가 응답하기 때문에
매번 새로운 개인 IP가 Hello World 문구를 새로 띄울 겁니다
즉. 이렇게 브라우저를 새로 고침할 때마다
요청이 다른 EC2 인스턴스로 보내진다는 뜻이죠
로드 밸런서가 요청을 분산시키고 있다는 의미입니다
꽤 멋지죠
로드 밸런서에 대한 실습도 함께 마무리가 됐네요
실습은 여기까지입니다
클래식 로드 밸런서는 삭제해 주세요
사용할 일이 없을 테니까요
하지만 섹션 중 EC2 인스턴스는 작동하게끔 두시면
새로운 로드 밸런서를 생성해서 사용해 볼 겁니다
이렇게 마무리하고 다음 강의에서 뵙겠습니다
74. Application Load Balancer(ALB)

이제 살펴볼 로드 밸런서의 두 번째 타입은 애플리케이션 로드 밸런서입니다.
7계층, 즉 HTTP 전용 로드 밸런서로 머신 간 다수 HTTP 애플리케이션의 라우팅에 사용이 되죠. 이러한 머신들은 대상 그룹이라는 그룹으로 묶이게 되는데요. 이 부분은 직접 실습에 들어가면 쉽게 이해가 되실 겁니다. 동일 EC2 인스턴스 상의 여러 애플리케이션에 부하를 분산합니다. 컨테이너와 ECS를 사용하게 되죠. HTTP/2와 WebSocket을 지원하며 리다이렉트도 지원하므로 HTTP에서 HTTPS로 트래픽을 자동 리다이렉트하려는 경우 로드 밸런서 레벨에서 가능하다는 의미가 되겠죠.

경로 라우팅도 지원합니다. 대상 그룹에 따른 라우팅으로는 예를 들면, URL 대상 경로에 기반한 라우팅이 가능합니다. example.com/users나 example.com/posts같은 경우죠. /users와 /posts는 URL 상의 서로 다른 경로이고 이들을 다른 대상 그룹에 리다이렉트 할 수 있죠. 잠시 후에 자세히 살펴볼 겁니다
URL의 호스트 이름에 기반한 라우팅도 가능합니다. 로드 밸런서가 one.example.com 또는 other.example.com에 접근이 가능하다고 하면 두 개의 다른 대상 그룹에 라우팅이 될 수 있죠.
쿼리 문자열과 헤더에 기반한 라우팅도 가능합니다. 예를 들어 example.com/users id=123&order=false가 다른 대상 그룹에 라우팅 될 수 있는 거죠.
애플리케이션 로드 밸런서는 약자로 ALB라고 하는데요. 마이크로 서비스나 컨테이너 기반 애플리케이션에 가장 좋은 로드 밸런서로 이후 배우게 될 도커와 Amazon ECS의 경우에는 ALB가 가장 적합한 로드 밸런서가 될 겁니다.
왜냐하면 포트 매핑 기능이 있어 ECS 인스턴스의 동적 포트로의 리다이렉션을 가능하게 해주거든요. 이 부분은 ECS 섹션에서 제대로 다뤄 보겠습니다
클래식 로드 밸런서와 비교를 해보면 CLB 뒤에서 다수의 애플리케이션을 사용하는 경우에는 여러 개의 클래식 로드 밸런서가 필요할 겁니다. 실제 애플리케이션 개수만큼의 로드 밸런서가 필요한 거죠. 반면 애플리케이션 로드 밸런서는 하나만으로도 다수의 애플리케이션을 처리할 수 있습니다
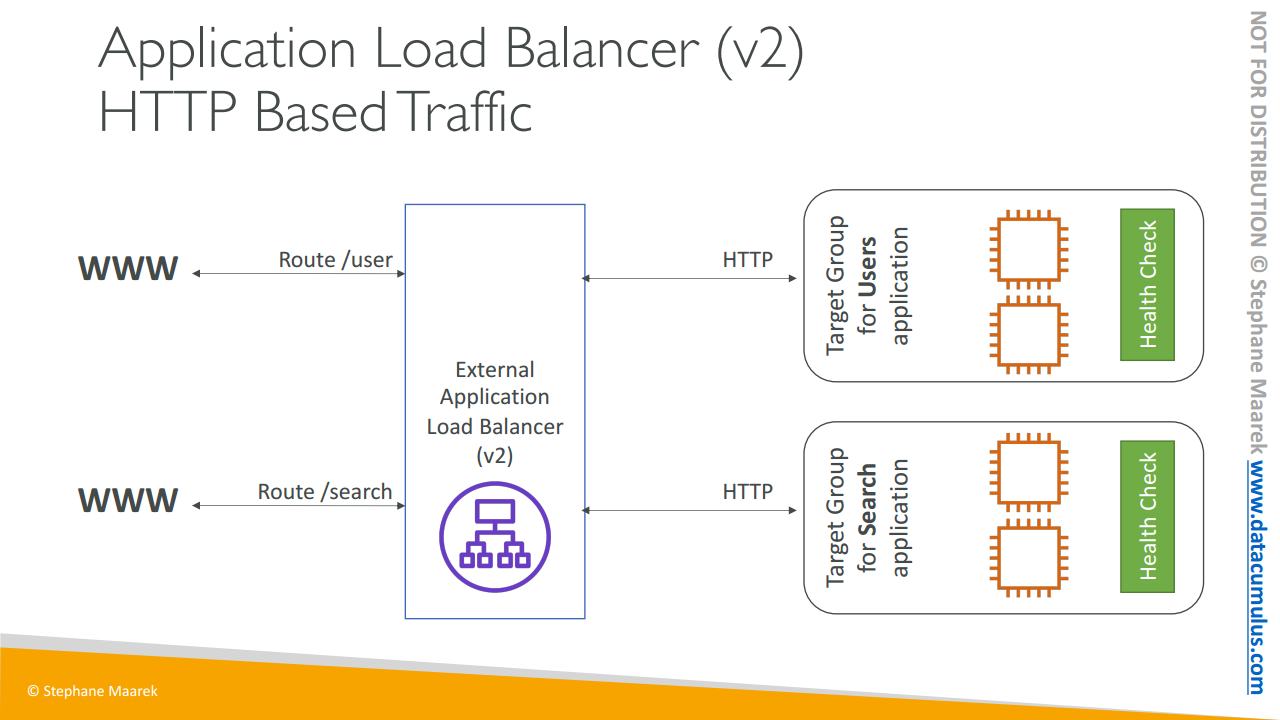
도표를 보시면 이해가 되실 겁니다. 외부 애플리케이션 로드 밸런서가 있고 이는 공공 대상이죠 그리고 그 뒤에는 EC2 인스턴스로 구성된 첫 번째 대상 그룹이 있습니다. 이건 Route /user로 라우팅 될 텐데요.
그리고 EC2 인스턴스로 구성된 두 번째 대상 그룹은 검색 애플리케이션으로 사용이 될 거고 여기선 상태 확인도 가능하게 됩니다. 그리고 이는 /search라는 규칙에 따라 라우팅되죠
즉, 두 개의 독립된 마이크로 서비스가 서로 다른 작업을 처리하는 겁니다
첫 번째는 유저 애플리케이션으로
두 번째는 검색 애플리케이션으로 작동하죠
하지만 이들은 URL에서 사용되는 라우팅을 기반으로 해 각 대상 그룹으로 지능적으로 라우팅하는 방법을 알고 있는 동일 애플리케이션 로드 밸런서의 뒤에 있는 겁니다

그렇다면 여기서 대상 그룹이란 뭘까요?
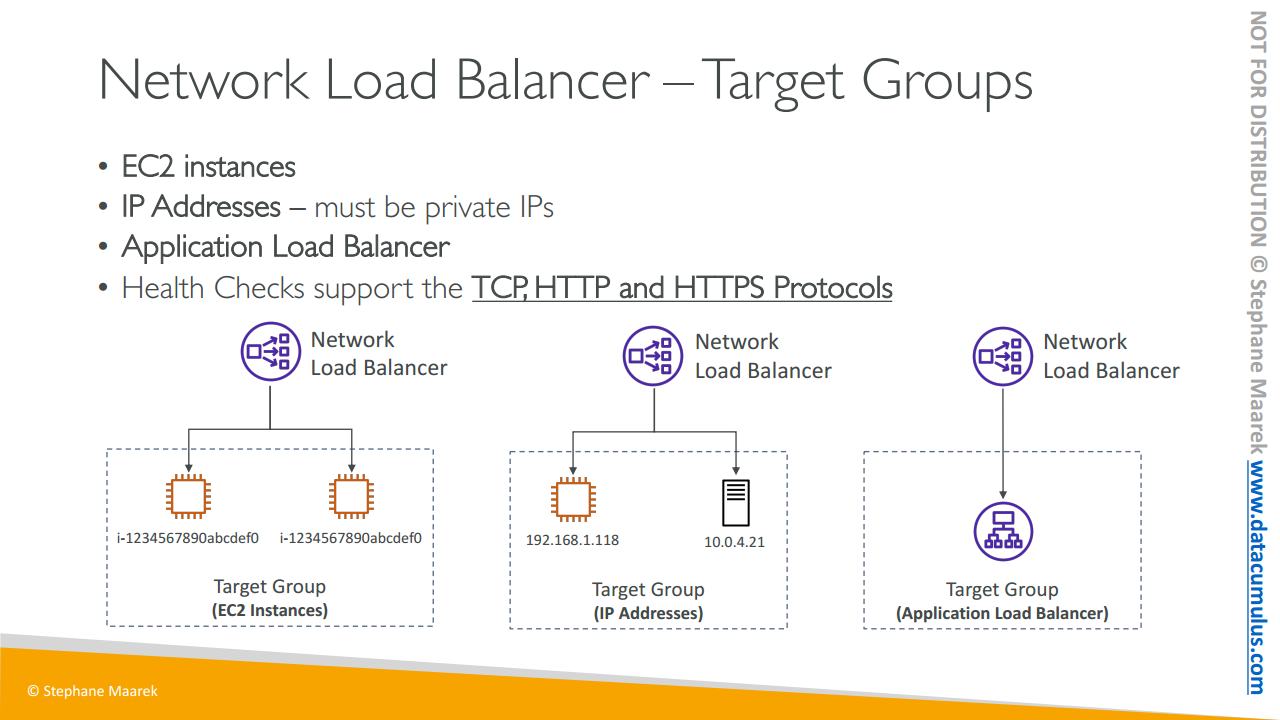
EC2 인스턴스가 대상 그룹이 될 수 있습니다. 이후에 배우게 될 테지만 이들은 오토 스케일링 그룹에 의해 관리될 수 있죠
ECS 작업도 될 수 있죠 이는 ECS 섹션에서 살펴볼 겁니다
람다 함수가 될 수도 있는데 잘 알려진 내용은 아닙니다. 람다 함수 앞에도 애플리케이션 로드 밸런서가 있을 수 있는 거죠. 이후의 섹션에서 배울 내용이지만 람다 함수는 AWS에서 무서버로 불리는 모든 것들의 기반이 되는 함수입니다.
마지막으로, ALB는 IP 주소들의 앞에도 위치할 수 있는데요. 꼭 사설 IP 주소여야만 합니다. ALB는 여러 대상 그룹으로 라우팅할 수 있으며 상태 확인은 대상 그룹 레벨에서 이뤄집니다.
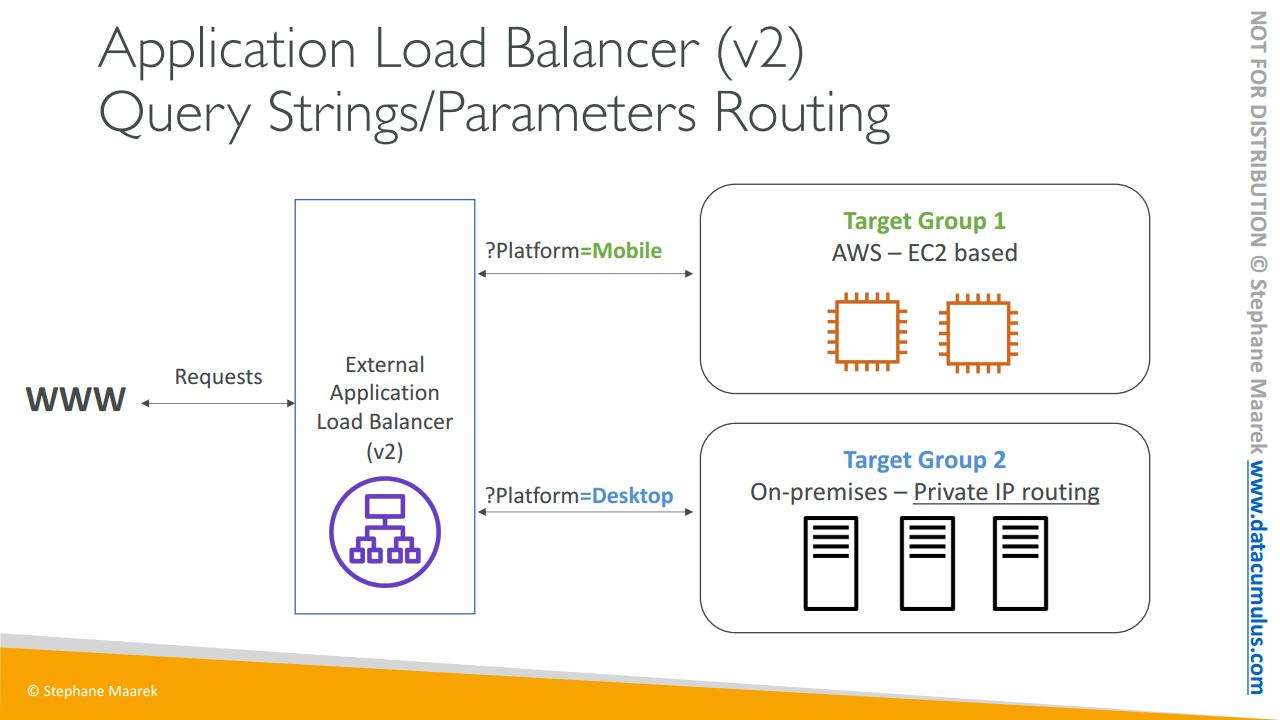
또 다른 예시도 한 번 살펴봅시다. ALB와 두 개의 대상 그룹이 있습니다
첫 번째는 AWS 기반의 EC2 인스턴스고
두 번째 대상 그룹은 데이터 센터 내부의 온프레미스 개인 서버죠
대상 그룹이 존재하기 위해서는, 등록을 위해 서버의 사설 IP가 대상 그룹에게 지정되어야 합니다.
그럼 ALB를 통해 요청을 처리하는 애플리케이션이 있다고 해봅시다. 첫 번째 대상 그룹으로는 모바일 기반 트래픽 전체를 그리고 두 번째 대상 그룹에게는 데스크탑 기반 트래픽 전체를 보내는 상황입니.다 이런 경우에는 쿼리 문자열이나 매개변수 라우팅을 사용하면 됩니다. 클라이언트가 사용하려는 URL에 ?Platform=Mobile이 있는 경우 첫 번째 대상 그룹으로 리다이렉팅되도록 ALB에서 리다이렉션 라우팅 규칙을 만들 수 있고 ?Platform=Desktop이 있는, 즉 쿼리 문자열 또는 매개변수인 경우 두 번째 대상 그룹으로 리다이렉트하도록 만들 수 있겠죠.
이게 어떤 상황에 활용될지는 모르겠지만 그냥 예시를 들어드린 겁니다

실습으로 들어가기 전 알아 두면 좋을 내용을 봅시다
첫 번째, 클래식에서와 마찬가지로 애플리케이션 로드 밸런서를 사용하는 경우에도 고정 호스트 이름이 부여됩니다
애플리케이션 서버는 클라이언트의 IP를 직접 보지 못하며 클라이언트의 실제 IP는 X-Forwarded-For라고 불리는 헤더에 삽입됩니다. X-Forwarded-Port를 사용하는 포트와 X-Forwarded-Proto에 의해 사용되는 프로토콜도 얻게 되죠.
즉, 클라이언트의 IP인 12.34.56.78가 로드 밸런서와 직접 통신해 연결 종료라는 기능을 수행합니다. 그리고 로드 밸런서가 EC2 인스턴스와 통신할 때에는 사설 IP인 로드 밸런서 IP를 사용해 EC2 인스턴스로 들어가게 되죠. 그리고 EC2 인스턴스가 클라이언트의 IP를 알기 위해서는 HTTP 요청에 있는 추가 헤더인 X-Forwarded-Port와 Proto를 확인해야 합니다
75. Application Load Balancer(ALB) 실습
이제 HTTP와 HTTPS 유형의 애플리케이션 로드 밸런서(ALB) 생성을
연습해 보겠습니다 ALB의 원리도 확인할 수 있습니다
멋진 그래프도 있네요 다 알고 있는 내용이죠?
이름을 지정하겠습니다
DemoALB로 하겠습니다 Internet-facing과
Internal ALB는 개인 트래픽 용입니다
지금은 애플리케이션에 공공으로 액세스하기 때문에
인터넷 경계 체계를 사용하겠습니다
그리고 로드 밸런서에 액세스하기 위해
IPv4 유형의 스택을 사용하겠습니다
네트워크 매핑에서는 실행할 VPC를 지정하고
서브넷 개수와 실행할 AZ도
지정해야 합니다
3개 서브넷을 모두 선택하죠
eu-west-1b부터 1c와 1a입니다
자동으로 올바른 서브넷에 할당됩니다
이제 로드 밸런서에 보안 그룹을 할당해야 합니다
이미 생성했었죠
my-first-load-balancer 보안 그룹이 할당됩니다
이제 리스너와 라우팅을 지정해야 합니다
80번 포트에서 HTTP 프로토콜로
로드 밸런서에 액세스를 시도하면 허용하는 것입니다
이제 이에 관한 타깃 그룹을 생성합니다
새 대상 그룹을 생성해 보죠
인스턴스를 시작으로
ALB에 가능한 다른 대상 그룹도 있습니다
인스턴스, IP 주소, 람다 함수 또는 ALB가 있죠
이쪽은 ALB 사용 시에만 해당합니다
지금은 인스턴스를 사용하겠습니다
이제 ALB가 네트워크 트래픽으로 데이터를 EC2 인스턴스로
보내도록 하겠습니다
그래서 대상 그룹 이름은 my-first-target-group이라 하고
프로토콜은 HTTP와 80번 포트로 합니다
VPC는 이처럼 설정하고 HPPT1으로 설정한 뒤
스크롤을 더 내리면 보이는
Health checks에서 고급 상태 확인 설정이 가능합니다
정상 임계값은 3으로 설정하고 비정상 임계값은
2로 설정하겠습니다
시간초과는 4초로 하고
간격은 5초로 하죠
그리고 Success code는 200으로 하겠습니다
Next를 클릭하겠습니다
이제 3개 중 2개의 인스턴스를 등록하겠습니다
2개만 등록하는 이유는 잠시 후에 알려드리겠습니다
Review targets에 3개 중 2개의 인스턴스가 있습니다
이 대상 그룹을 생성하죠
생성을 확인하고 로드 밸런서로 돌아옵니다
새로고침 후 my-first-target-group을
선택합니다
Summary를 보시면 DemoALB에 Internet-faing, IPv4이고
이 보안 그룹에 연결됐습니다
네트워킹 매핑에는 3개의 AZ가 있고
80번 포트의 HTTP이며 이 대상 그룹으로 리디렉션됩니다
이제 로드 밸런서를 생성하면 끝입니다
로드 밸런서를 확인해 보죠
프로비저닝 될 때까지 기다려야 합니다
ALB가 프로비저닝 됐습니다
이제 DNS 이름으로 가서 열어 보면
이쪽의 IP와 Hello World가 나타납니다
새로고침 하면 다른 EC2 인스턴스의 Hello World가 나옵니다
따라서 ALB는 CLB와 마찬가지로 예상대로 작동하고 있는 것이죠
하지만 ALB이기 때문에 추가 장점이 있습니다
이것을 보여 드리기 위해 Target Groups로 가서
두 번째 대상 그룹을 생성하겠습니다
기존 대상 그룹이 있고
인스턴스로 기반으로 대상 그룹을 생성하는데
my-second-target-group이라고 하겠습니다
여기 보이는 것으로 VPC를 설정하고
HTTP1으로 설정한 뒤
스크롤을 내려서 상태 확인을 설정합니다
정상 임계값을 3으로 하고
시간초과는 4, 간격은 5로 설정합니다
이제 Next를 클릭하면 등록할 수 있습니다
어떤 인스턴스인지 모르겠지만 누락된 인스턴스가 있죠
사실 어떤 것을 선택해도 상관없습니다
어쨌든 저는 이 인스턴스를 추가하겠습니다
대상 그룹의 대상인 Include as pending below를 클릭하죠
이제 대상 그룹을 생성합니다
이제 두 번째 대상 그룹이 생성됐습니다
정말 재밌는 것은 다시 ALB로 돌아가면
여러 대상 그룹으로 리디렉션되는 다양한 리스너가 있는 것입니다
첫 번째 대상 그룹으로 가는 80번 포트의 리스너가 있네요
리스터를 확인하고 규칙을 수정해서
다른 대상 그룹에도 적용할 수 있습니다
규칙을 추가해 보겠습니다
Path를 /test라고 입력하고
두 번째 대상 그룹으로 응답을 보내도록 합니다
이제 이 규칙을 저장합니다
두 개의 규칙 중 첫 번째 규칙이 평가될 경로이며 일치하면
두 번째 대상 그룹으로 이동합니다
그렇지 않으면 기본적으로 첫 번째 대상 그룹으로 라우팅 됩니다
많은 라우트를 삽입할 수 있습니다
예를 들어, 경로를 /constant로 입력하고
그리고 반환되는 고정 응답은 404와
Constant error response!로 설정하겠습니다
마음대로 해도 됩니다
그리고 다시 저장하면 로드 밸런서의
다른 규칙이 생겼습니다
여러분도 생성할 수 있고 클래식 로드 밸런서보다
훨씬 강력한 것을 확인할 수 있습니다
path, Http header과 Query string와
Source IP 등으로 라우팅할 수 있습니다
로드 밸런서에서 여러 가지를 시도할 수 있죠
이제 확인해 보겠습니다
DemoALB에서 이쪽의 DNS를 열면
여기 이미 열러 있네요
잘 실행되고 있으며 2개의 인스턴스만 얻습니다
/constant를 입력하면 로드 밸런서에서 보낸
Constant error response! 가 나타납니다
/test를 입력하면 실행되지 않습니다
Not Found라고 나오는데 그 이유는
EC2 인스턴스가 /test 유형의 쿼리에 응답하도록 구성되지 않았기 때문이죠
하지만 이 쿼리는 두 번째 그룹으로 리디렉션되는데
이 부분을 보여드리려고 한 것입니다
이제 끝내기 위해서 정리를 하겠습니다
리스너에서 생성한 규칙을 삭제합니다
이 두 개를 삭제하면 됩니다
삭제 후에는 대상 그룹으로 와서
두 번째 그룹을 삭제합니다
그리고 첫 번째 대상 그룹에 대상을 하나 더 추가합니다
Register targets를 클릭하고
어떤 건지 모르니까 3개를 모두 추가해 보면
이쪽에 추가됐습니다
등록 중인 대상을 등록합니다
이제 상태 확인을 실행할
대상 그룹이 생성됐으니
인스턴스가 정상인지 확인합니다
3개 인스턴스가 모두 정상입니다
아주 좋습니다
이제 URL의 라우트에 있는 로드 밸런서로 돌아가면
총 3개의 인스턴스에서 Hello World를 얻습니다
대상 그룹이 잘 실행되는 것입니다
ALB는 여기까지입니다
즐거우셨길 바랍니다 다음 강의에서 뵙겠습니다
76. Network Load Balancer (NLB)

이제 마지막 로드 밸런서인 네트워크 로드 밸런서(NLB)를 살펴보죠. layer 4(L4) 밸런서로 TCP나 UDP 기반의 트래픽을 인스턴스로 전달하는 것입니다. 낮은 계층의 밸런서죠
초당 수백만 건의 요청을 처리할 수 있어 매우 고성능입니다. ALB보다 지연 시간이 훨씬 짧습니다. 숫자로 이해해 보자면 밸런서 애플리케이션의 평균 지연 시간은 400ms이고 반면에 NLB의 지연 시간은 약 100ms입니다.
NLB는 다른 점이 많은데 외부의 가용 영역 당 1개의 고정 IP를 노출하기 때문입니다. 특정 IP를 화이트리스트에 추가할 때 유용하며 NLB 자체의 IP를 가져오는 대신 일래스틱 IP 할당을 지원합니다
이는 엔트리 포인트를 2개를 얻고자 할 때 NLB를 사용하면 된다는 것입니다. 예를 들어, 애플리케이션 전용의 특정 IP를 지정하면 NLB가 해당 트래픽을 EC2 인스턴스로 보내는 것입니다. 바로 ALB, CLB와의 차이점이죠. 이 두 로드 밸런서는 고정 IP가 없고 고정 호스트 이름이 있습니다
NLB의 사용 사례를 살펴보면 고성능이나 TCP 또는 UDP 수준의 트래픽을 원할 때 사용합니다.
곧 시작할 실습에서는
NLB는 AWS 프리 티어에 포함되지 않습니다. 그래서 실습을 해 보시려면 메모리 비용을 지불해야 합니다. 비용 지불을 원치 않으시면
실습은 안 해도 됩니다
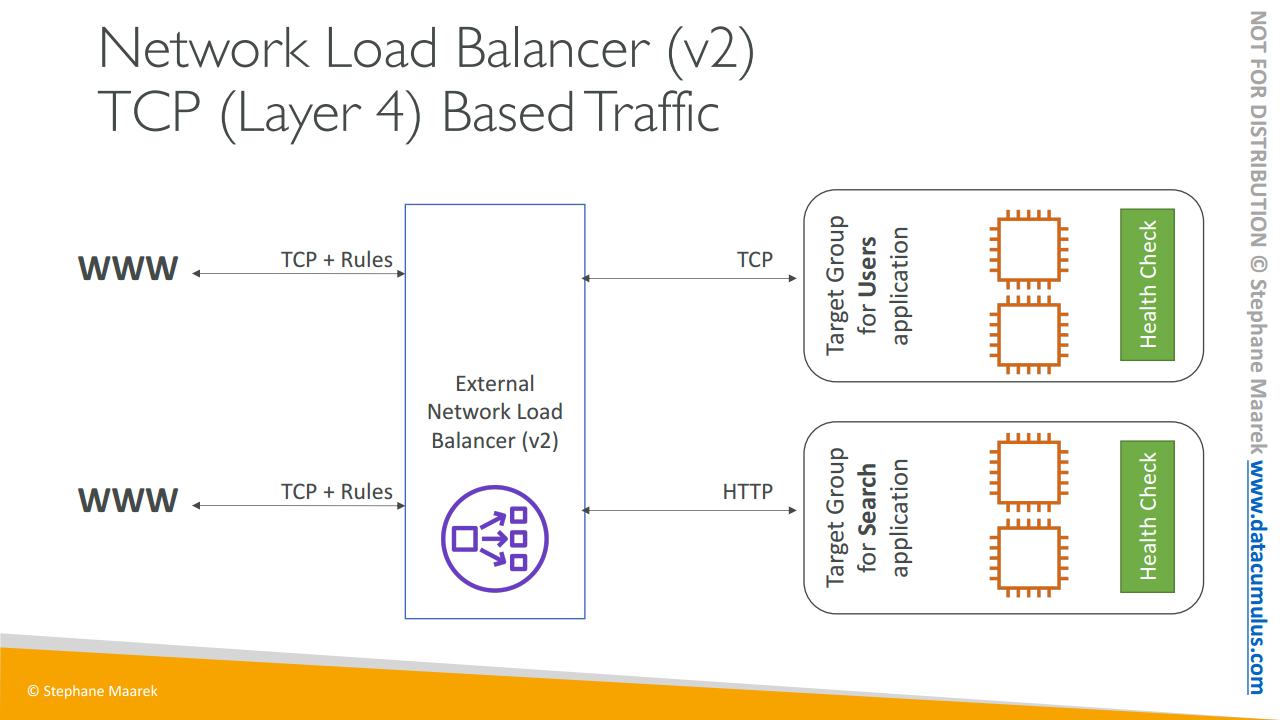
NLB가 L4라는 것은 대상 그룹이 이전처럼 EC2 인스턴스가 될 수 있다는 의미입니다. 하지만 지금은 TCP 기반의 트래픽이 대상 그룹에 도달할 것이므로 외부에서 올 수 있으며 대상 그룹으로 리디렉션 하는 방법에 관한 일부 규칙도 있습니다.
그렇다면 NLB는 무엇을 트래픽에 보낼까요?
여러 대상 그룹인데
첫 번째는 EC2 인스턴스로 대상 그룹에 EC2 인스턴스를 등록하면 NLB에서 트래픽 전송 방법을 파악합니다. 매우 직관적이죠
두 번째는 IP 주소입니다. 고정 IP와 개인 IP를 지정해서 NLB에서 직접 트래픽을 보내도록 합니다.
이유가 무엇일까요?
약간 과하지만 EC2 인스턴스의 경우 자체 데이터 센터에 서버가 있는 경우에는 가급적이면 그대로 개인 IP가 있는 서버의 로드 밸런서를 사용합니다. 이것이 두 번째 옵션입니다
세 번째 옵션은 ALB입니다
NLB와 ALB를 결합하는 것이 가능하죠. 왜 결합할까요?
NLB의 기능을 활용해서 고정 IP를 가질 수 있기 때문입니다. 따라서 NLB 수준의 고정 IP를 가지면서 규칙과 같은 HTTP 관련 기능에 ALB를 활용할 수 있는 것이죠
77. Network Load Balancer (NLB) 실습
NLB로 실습해 보겠습니다
새로운 NLB를 생성합니다
여기서 볼 수 있듯이 트래픽은 TCP, TLS, UDP 등의 트래픽입니다
이제 생성해 보죠
DemoNLB로 이름을 지정하고
인터넷 경계 체제를 선택합니다
그리고 IP 주소 유형은 IPv4로 지정하고
네트워크 매핑에서 VPC를 선택합니다
us-east-2a, us-east-2b와 us-east-2c를 선택하겠습니다
재밌는 것은 NLB에 관한 AZ를 선택할 때
IPv4 주소를 갖게 됩니다
NLB에는 고정 IPv4 주소가 있다는 것을 기억하세요
AWS에서 할당한 Ipv4를 사용하거나
자체 일래스틱 IP 주소를 제공할 수도 있는데
이쪽에서 일래스틱 IP를 생성하고
NLB에 할당할 수 있습니다
고정 IP를 갖는 NLB의 특성입니다
지금은 해보지 않지만 가용 영역 당 1개의 고정 IP를
할당할 수 있습니다
이제 리스너 관련해서는
80번 포트의 TCP 프로토콜로 설정합니다
HTTP 실행에 TCP에 의존함으로 제대로 작동할 것입니다
그래서 80번 포트의 TCP 면 실행될 것을 알 수 있죠
하지만 보시다시피 HTTP 옵션이 없습니다
HTTP 기반의 로드 밸런서가 아니기 때문입니다
TCP 기반의 로드 밸런서죠
80번 포트의 TCP가 올바르다면
대상 그룹을 생성해야 합니다
이제 NLB의 대상 그룹을 생성하겠습니다
인스턴스 기반의 대상 그룹을 생성하겠습니다
my-target-group-nlb-demo로 이름을 지정하겠습니다
TCP와 80번 포트로 설정하고 VPC는 아주 좋네요
이제 상태 확인을 수정하겠습니다
정상 임계값은 3으로 하고
간격은 조금 더 빠르게 10초로 설정합니다
이제 대상을 등록하겠습니다
3개 인스턴스를 모두 등록하고
등록 중 대상을 포함해서
대상 그룹을 생성합니다
이 대상 그룹은 NLB에만 해당하며
대상이 정상인지 아닌지 확인해야 합니다
이제 NLB로 돌아가죠
새로고침한 다음에 이쪽에 있는
대상 그룹을 선택합니다
여기서는 개요를 볼 수 있습니다 이제 NLB를 생성하겠습니다
로드 밸런서를 확인해 보겠습니다
이제 ALB와 NLB가 생겼습니다
여기 NLB가 있고
프로비저닝 될 때까지 기다려야 하므로
잠깐 영상을 정지하겠습니다
NLB 프로비저닝이 끝났습니다
URL을 클릭하고 Enter를 누르겠습니다
보시다시피 실행이 안 되네요
실행되지 않는 이유를 바로 보여드리겠습니다
대상 그룹을 확인해 보면 2개의 대상 그룹이 있습니다
첫 번째는 HTTP이고 두 번째는 TCP입니다
HTTP에는 3개의 대상이 있고 모두 정상입니다
3개의 정상 대상이 있지만
NLB를 자세히 살펴보면 Targets 탭에서
3개의 비정상 대상을 확인할 수 있습니다
NLB에서 TCP 기반의 대상 그룹을 실행하면
보안 그룹에서 고려하는 것은
EC2 인스턴스의 보안 그룹이기 때문입니다
NLB를 생성할 때 혹은 TCP에 대상 그룹을 생성할 때
생성했던 보안 그룹이 없었습니다
이는 문제 해결을 위해서
인스턴스의 보안 그룹을 수정해야 한다는 것입니다
launch-wizard-1의 인바운드 규칙을 보면
80번 포트의 HTTP는 첫 번째 로드 밸런서의 보안 그룹만 허용합니다
이제 NLB가 실행되도록 모든 HTTP를 다시 허용하는
새로운 규칙을 생성해야 합니다
그래서 전체로 선택하고
NLB에 필요한 것이라고 설명을 입력합니다
그 이유는 NLB가 클라이언트에서
EC2 인스턴스로 트래픽을 보내기 때문입니다
그래서 EC2 인스턴스 측면에서는
트래픽이 NLB에서 오는 것처럼 보이지 않죠
외부 클라이언트에서 오는 것처럼 보입니다
이 NLB 규칙을 추가한 뒤
대상 그룹으로 돌아가서 이 대상 그룹을 열면
인스턴스가 정상으로 바뀌는 것을 바로 확인할 수 있습니다
1분만 기다려 보죠
이제 인스턴스가 정상으로 바뀌고 있네요
새로고침하면 모두 정상인 상태입니다
보안 그룹을 수정했기 때문이죠
이제 NLB로 돌아가서 새로고침하면
인스턴스에서 Hello World를 얻는데
계속 새로고침하면
동일한 인스턴스로 리디렉션됩니다
연결이 다소 고정적이지만
NLB가 실행되는 것은 확인했습니다
이제 실습을 마치려면
NLB와 대상 그룹을 삭제하면 됩니다
이쪽의 NLB를 삭제하고
NLB 데모의 대상 그룹도
삭제하겠습니다
그리고 다시 보안 그룹으로 가서
이 규칙을 삭제해서
ALB만 있었던 상태로 다시 돌아가면 됩니다
실습은 여기까지입니다
즐거우셨길 바라요 다음 강의에서 뵙겠습니다
78. Gateway Load Balancer(GLB)

이제 가장 최근의 로드 밸런서인 게이트웨이 로드 밸런서(GWLB)를 살펴보죠
GWLB는 배포 및 확장과 AWS의 타사 네트워크 가상 어플라이언스의 플릿 관리에 사용됩니다. 잠시 후에 의미를 알려드리겠습니다
GWLB는 네트워크의 모든 트래픽이 방화벽을 통과하게 하거나 침입 탐지 및 방지 시스템에 사용합니다. 그래서 IDPS나 심층 패킷 분석 시스템 또는 일부 페이로드를 수정할 수 있지만 네트워크 수준에서 가능합니다.
도표를 통해 더 쉽게 이해하도록 하겠습니다. 여러분의 애플리케이션에 액세스하는 사용자가 있다고 해봅시다. 그리고 사용자는 예를 들어, ALB를 사용해 애플리케이션에 바로 액세스하고 트래픽은 사용자에서 ALB와 애플리케이션으로 바로 이동합니다.
하지만 애플리케이션으로 이동하기 전에 모든 트래픽을 검사하려면 어떻게 해야 할까요? 트래픽이 애플리케이션에 도달하기 전에 EC2 인스턴스와 같은 타사 가상 어플라이언스를 배포했고 트래픽의 애플리케이션에 도달 전에 트래픽을 통과하려면 원래는 많이 복잡했지만 GWLB를 사용하면 아주 간단합니다.
GWLB를 생성하면 이면에서는 VPC에서 라우팅 테이블이 업데이트됩니다. 꽤 고급 과정에 네트워크 측면이지만 집중해 주세요 이제 라우팅 테이블이 수정되면 먼저, 모든 사용자 트래픽은 GWLB를 통과합니다. 그리고 GWLB는 가상 어플라이언스의 대상 그룹 전반으로 트래픽을 확산합니다. 그래서 모든 트래픽은 어플라이언스에 도달하고 어플라이언스는 트래픽을 분석하고 처리합니다.
예를 들면, 방화벽이나 침입 탐지와 같은 것이죠. 이상이 없으면 다시 GWLB로 보내고 이상이 있으면 트래픽을 드롭 합니다. 방화벽을 예로 들면 트래픽을 드롭 할 수 있지만 허용되면 GWLB를 통과하며 GWLB에서는 트래픽을 애플리케이션으로 보냅니다.
애플리케이션에서는 명료하게 모든 트래픽이 GWLB와 타사 가상 어플라이언스를 통과해 모든 네트워크 트래픽을 분석하고 드롭 시킬 수도 있습니다. GWLB의 기능은 네트워크 트래픽을 분석하는 것 등입니다
원리는 어떨까요?
GWLB는 살펴봤었던 모든 로드 밸런서보다 낮은 수준에서 실행됩니다. IP 패킷의 네트워크 계층인 L3입니다. 이제 GWLB는 2가지 기능을 갖게 됩니다
첫 번째는 투명 네트워크 게이트웨이입니다
VCP의 모든 트래픽이 GWLB가 되는 단일 엔트리와 출구를 통과하기 때문입니다. 그리고 대상 그룹의 가상 어플라이언스 집합에 전반적으로 그 트래픽을 분산해 로드 밸런서가 됩니다. 이 부분이 GWLB에 관해 꼭 알아야 할 부분입니다.
마지막으로 시험 볼 때
6081번 포트의 GENEVE 프로토콜을 사용하세요. 바로 GWLB가 됩니다. 도표가 이해되길 바랍니다
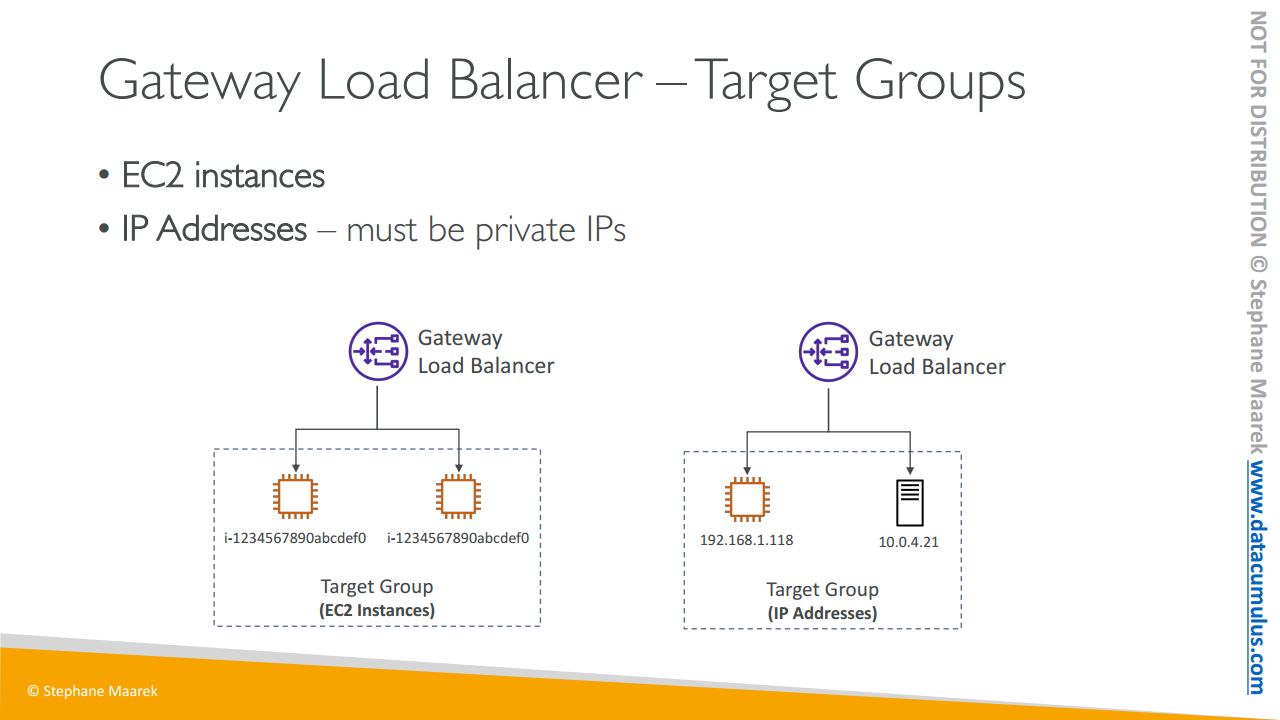
GWLB의 대상 그룹은 무엇일까요?
여기 타사 어플라이언스가 있습니다. EC2 인스턴스일 수도 있고 인스턴스 ID로 등록하거나 IP 주소일 수도 있습니다. 이 경우에는 개인 IP여야 합니다
예를 들어, 자체 네트워크나 자체 데이터 센터에서 이런 가상 어플라이언스를 실행하면 IP로 수동 등록할 수 있습니다. GWLB는 여기까지입니다
79. Elastic Load Balancer - Sticky Sessions + 실습

이제 일래스틱 로드 밸런서의 고정 세션 혹은 세션 밀접성을 살펴보겠습니다
고정성 혹은 고정 세션을 실행하는 것으로 그 개념은 로드 밸런서에 2가지 요청을 수행하는 클라이언트가 요청에 응답하기 위해 백엔드에 동일한 인스턴스를 갖는 것입니다. 2개의 EC2 인스턴스와 3개의 클라이언트가 있는 ALB와 같은 것입니다.
1번 클라이언트가 요청을 생성해 첫 번째 EC2 인스턴스를 통과하면 로드 밸런서에서 두 번째 요청을 실행할 때 동일한 인스턴스로 이동함을 뜻하며 이는 애플리케이션 밸런서가 모든 EC2 인스턴스 전반으로 모든 요청을 확산하는 것과는 다른 동작입니다.
2번 클라이언트에서는 ALB가 두 번째 인스턴스와 통신하면 동일한 인스턴스로 이동하고 3번째 클라이언트도 마찬가지입니다.
그리고 이 동작은 CLB와 ALB에서도 설정할 수 있습니다. 그 원리에 관해서는 쿠키라는 것이 있는데 클라이언트에서 로드 밸런서로 요청의 일부로서 전송되는 것입니다. 고정성과 만료 기간도 있죠. 즉, 쿠키가 만료되면 클라이언트가 다른 EC2 인스턴스로 리디렉션 된다는 것입니다.
세션 만료를 사용 시에는 사용자의 로그인과 같은 중요한 정보를 취하는 세션 데이터를 잃지 않기 위해 사용자가 동일한 백엔드 인스턴스에 연결됩니다.
고정성을 활성화하면 백엔드 EC2 인스턴스 부하에 불균형을 초래할 수 있습니다 일부 인스턴스는 고정 사용자를 갖게 됩니다

이제 더 자세히 살펴보죠 쿠키는 무엇일까요?
고정 세션에는 2가지 유형의 쿠키가 있습니다. 애플리케이션 기반 쿠키와 기간 기반의 쿠키가 있습니다.
애플리케이션 기반 쿠키는 대상으로 생성된 사용자 정의 쿠키로 애플리케이션에서 생성됩니다. 그리고 애플리케이션에 필요한 모든 사용자 정의 속성을 포함할 수 있죠. 쿠키 이름은 각 대상 그룹별로 개별적으로 지정해야 하는데 이런 이름은 사용하면 안 됩니다.
AWSALB, AWSALBAPP 혹은 AWSALBTG 같은 이름이죠. ELB에서 사용하기 때문입니다. 또는 애플리케이션 쿠키가 될 수도 있는데 지금은 로드 밸런서 자체에서 생성됩니다. 그리고 ALB의 쿠키 이름은 AWSALBAPP입니다
두 번째 유형은 기간 기반 쿠키입니다. 로드 밸런서에서 생성되는 쿠키로 ALB에서는 이름이 AWSALB이며 CLB에서는 AWSELB입니다. 특정 기간을 기반으로 만료되며 그 기간이 로드 밸런서 자체에서 생성되는 것입니다. 애플리케이션 기반의 쿠키는 애플리케이션에서 기간을 지정할 수 있습니다.
원리는 여기까지입니다
쿠키 이름이나 사용자 지정 혹은 애플리케이션을 모두 외울 필요는 없지만 애플리케이션 기반 쿠키와 기간 기반 쿠키가 있고 특정 이름이 있다는 것만 알면 됩니다
클라우드 프론트를 다룰 때 다시 살펴보겠습니다
이제 로드 밸런서를 확인해 보죠
새 탭에서 열었는데요
로드 밸런서에 있는 3개 인스턴스가 보입니다
이제 고정 세션을 활성화하겠습니다
이제 Target Groups로 가서
대상 그룹을 열고 Actions에서
대상 그룹의 속성을 수정합니다
하단에는 고정성 혹은 고정 세션이 있는데요
2가지 유형의 가능한 고정성이 있습니다
먼저, 기간 유형의 고정성인
로드 밸런서 생성 쿠키가 있습니다
범위는 1초에서 7일입니다
그리고 애플리케이션 기반의 쿠키가 있고
범위는 동일하게 1초에서 7일입니다
이제 앱에서 로드 밸런서로 보내는
쿠키 이름을 지정해야 합니다
MYCUSTOMAPPCOOKIE로 할 수 있습니다
이 이름은 로드 밸런서가 고정성 실행 시 사용합니다
여기까지가 고정성입니다
이제 로드 밸런서 생성 쿠키로 설정하고
고정성 기간은 1일로 해서
변경 사항을 저장하겠습니다
이제 확인해 볼까요?
이번에는 디버거도 열어서
네트워크의 상황을 살펴보죠
Network를 클릭하고
페이지를 새로고침을
여러 번 해 보면
동일한 인스턴스를 얻습니다
7-176이 계속 돌아오는 것이죠
이제 로드 밸런서에 관한
Get 요청으로 가서
글씨가 너무 작아서 죄송합니다
크기를 늘릴 수가 없네요
Cookies로 이동하면
Response Cookies에서 쿠키 만료는 내일인 것을 볼 수 있습니다
경로와 쿠키 값도 확인할 수 있죠
Request Cookies에서는
브라우저가 로드 밸런서에 요청을 보내면
여기 있는 쿠키를 다시 보냅니다
쿠키가 인스턴스를 통과했기 때문에
고정성이 실행되는 것이죠
지금까지 고정성의 원리를 자세히 살펴봤습니다
강의는 여기까지입니다 즐거우셨길 바랍니다
마지막으로 웹 개발자 도구는 Web Developer에서
Web Developer tools를 클릭합니다
빠르게 액세스하려면
Chrome과 Firefox도 동일한데
Network로 가서 요청에 관한 정보에 액세스할 수 있습니다
이제 대상 그룹으로 돌아가서
속성 수정으로 이동해
고정성을 비활성해서
다시 정상 동작하도록 하면 끝입니다
여기까지입니다 즐거우셨나요?
다음 강의에서 뵙겠습니다
80. Elastic Load Balancer - Cross Zone Load Balancing + 실습
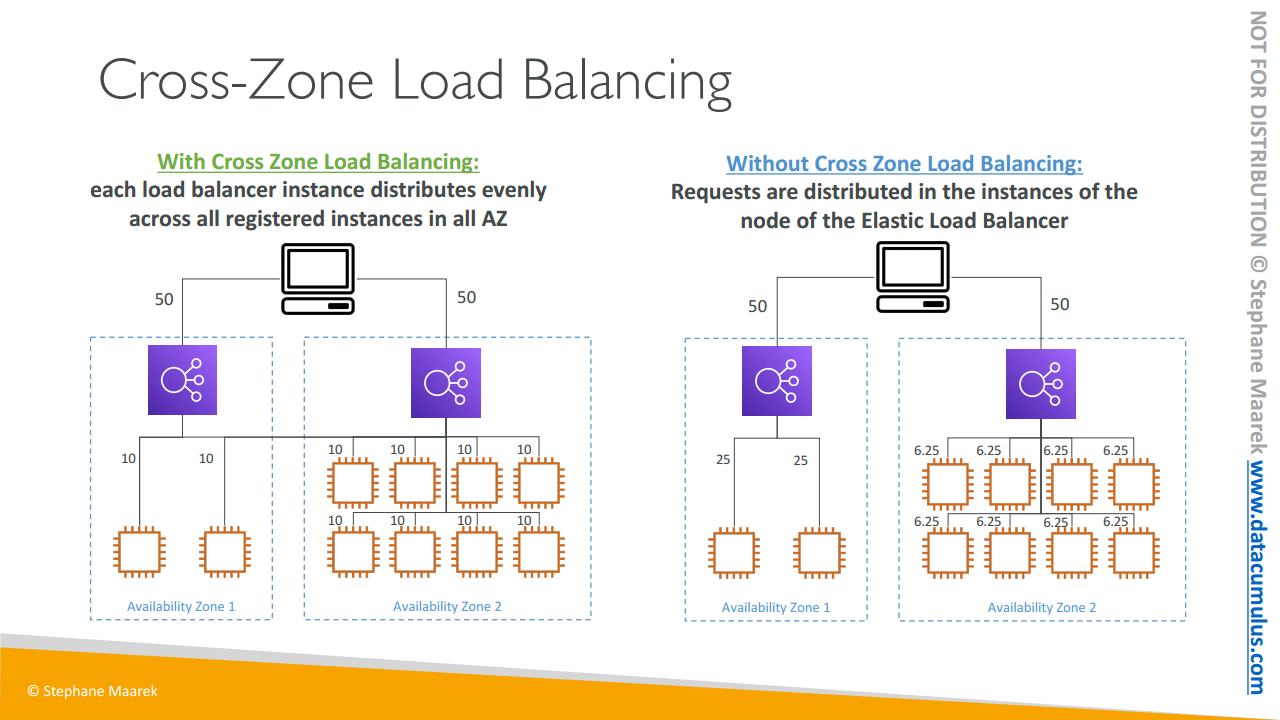
교차 영역 로드 밸런싱에 관해 알아보겠습니다
매우 불균형한 상황을 예로 들었지만 핵심을 설명하는 예시입니다. 2개의 가용 영역이 있습니다. 2개의 EC2 인스턴스가 있는 로드 밸런서가 있고 다른 하나도 로드 밸런서가 있는데요. 8개의 EC2 인스턴스가 있습니다
동일한 로드 밸런서 인스턴스로 일반적인 로드 밸런서입니다. 그리고 클라이언트는 두 로드 밸런서에 액세스하고 있습니다. 교차 영역 로드 밸런싱을 사용하면 각 로드 밸런서 인스턴스는 전체 가용 영역에 등록된 모든 인스턴스에 전반적으로 고르게 분산됩니다. 그러면 클라이언트는 50%의 트래픽을 첫 번째 ALB 인스턴스에 보내고 다른 ALB 인스턴스에 나머지를 보냅니다. 하지만 각 ALB는 가용 영역에 상관없이 10개의 EC2 인스턴스에 전반적으로 트래픽을 리디렉션합니다. 그래서 교차 영역 로드 밸런싱인 것이죠.
두 번째 ALB 인스턴스를 보면 전체 인스턴스에 수신한 트래픽의 10%를 보내는데 그 이유는 인스턴스가 총 10개이기 때문입니다. 그래서 각각 10%의 트래픽을 얻는 것이죠
첫 번째 ALB도 동일합니다. 전체 인스턴스의 트래픽의 10%를 보냅니다. 이 예시에서 교차 영역 로드 밸런싱을 사용하면 의도하는지는 모르겠으나 트래픽을 전체 EC2 인스턴스에 고르게 분산하게 됩니다. 그래도 이제 이 동작은 사용 가능합니다
두 번째로 사용 가능한 동작은 교차 영역 로드 밸런싱을 사용하지 않습니다. 예시는 동일하지만 교차 영역 로드 밸런싱 없이 일래스틱 로드 밸런서의 노드 인스턴스에 분산됩니다. 여기서 클라이언트는 트래픽의 50%를 첫 번째 가용 영역에 보내고 나머지 50%를 두 번째 가용 영역에 보냅니다. 하지만 첫 번째 ALB 인스턴스는 여기 있는 두 인스턴스에만 트래픽을 보내고 있습니다. 이는 이 가용 영역에 있는 EC2 인스턴스는 트래픽을 각각 25%씩 받는 것입니다. 반반씩 받는 것이죠.
그리고 오른쪽을 보시면 수신한 트래픽을 가용 영역 2에 등록된 EC2 인스턴스로 다시 분배합니다. 교차 영역 로드 밸런싱 없이도 각 가용 영역에 트래픽이 포함된 것이죠
하지만 각 가용 영역에 EC2 인스턴스 수가 불균형하면 특정 가용 영역의 EC2 인스턴스가 트래픽을 더 많이 수신하게 됩니다.
알기만 하면 됩니다. 정답도 오답도 없죠. 사용 사례에 따라 다릅니다

그래서 교차 영역 로드 밸런싱은 ALB에서 늘 활성화되어 있고 비활성화할 수 없습니다. 보통 데이터가 한 가용 영역에서 다른 가용 영역으로 이동하면 비용을 지불해야 합니다. 하지만 활성화되어 비활성화할 수 없으니 AZ 간 데이터 전송에 관한 비용이 없습니다.
네트워크 로드 밸런서에는 기본으로 비활성화되어 있어서 교차 영역 로드 밸런싱 활성화에 비용을 지불해야 합니다. 가용 영역 간 데이터 전송에 비용을 지불해야 하는 것이죠.
마지막으로 클래식 로드 밸런서에는 교차 영역 로드 밸런싱이 기본으로 비활성화되어 있습니다. 활성화하면 가용 영역 간 데이터 전송에 비용이 발생하지 않습니다.
모든 로드 밸런서에서 사용할 수 있는 것이죠. ALB에는 활성화되어 있고 NLB에서 활성화하려면 비용을 내야 합니다. 그리고 CLB에는 비용 없이 활성화할 수 있습니다.
그리고 실습을 위해서
CLB와 NLB를 생성했는데 이렇게 안 하셔도 됩니다
설정만 보여드리겠습니다
이쪽의 CLB에서
스크롤을 계속 내리면
교차 영역 로드 밸런싱이 기본으로 비활성화됐습니다
하지만 설정을 변경해서 활성화할 수 있죠
그러면 이 CLB에 등록된 전체 EC2 인스턴스에
전체적으로 트래픽이 분산됩니다
비용은 지불되지 않습니다
ALB에는 기본으로 활성화되어 있어서
교차 영역 로드 밸런싱에서 설정을 변경할 것이 없습니다
다시 말씀드리지만 기본으로 활성화됐기 때문입니다
NLB에서 스크롤을 내리면
교차 영역 로드 밸런싱이 기본으로 비활성화되어 있습니다
활성화를 해 보면
메시지가 나타나는데
교차 영역 로드 밸런싱이 활성화되면
지역별 데이터 전송에 비용이 발생한다는 거죠
NLB에서는 이 비용을 내야 하죠
Save를 누르면 활성화되지만
비용을 지불하게 됩니다
강의는 여기까지입니다
이 실습은 안 하셔도 됩니다
다음 강의에서 뵙겠습니다
81. Elastic Load Balancer(ELB) - SSL 인증서 + 실습

이번 강의에서는 SSL 및 TLS 인증서에 대해 알아 볼 겁니다. 지금 살펴볼 내용은 굉장히 단순화된 버전으로 실제로는 훨씬 복잡합니다만 이 내용이 낯선 분들을 위해 개념을 소개하려 합니다. SSL, TLS 에 대해 알고 계시더라도 SNI와 더불어 로드 밸런서의 통합에 대한 내용을 다룰 예정이니 강의를 뛰어 넘지 마시고 시청해 주시기를 부탁드립니다
SSL 인증서를 사용하면 클라이언트와 로드 밸런서 사이에서 전송 중에 있는 트래픽을 암호화할 수 있습니다. 인-플라이트 암호화라고 불리는 과정으로 즉 데이터가 네트워크를 통과하는 중에 암호화되고 발신자와 수신자만이 이를 해독할 수 있는 거죠.
SSL(Secure Sockets Layer)은 보안 소켓 계층을 뜻하며 연결을 암호화하는 데에 사용됩니다. 그리고 TLS는 SSL의 최신 버전으로써 전송 계층 보안을 의미하죠.
요즘에 주로 사용되는 건 TLC 인증서지만 저를 포함한 많은 사람들은 이를 여전히 SSL이라고 부르고 있습니다. 의도적인 실수인 셈이니 이 점 감안해 주세요. TLS 인증서라고 부르는 게 SSL 인증서라고 부르는 것보다 더 낫겠지만 여러 가지 이유로 인해 SSL이라고 부를 겁니다 이 편이 이해하기가 더 쉽거든요.
공용 SSL 인증서는 Comodo, Symantec, GoDaddy, GlobalSign, Letsencrypt 등의 인증 기관에서 발급됩니다
로드 밸런서와 연결된 공용 SSL 인증서를 사용하면 클라이언트와 로드 밸런서 사이의 연결을 암호화할 수 있습니다. 따라서 Google.com과 같은 웹사이트에 접속을 했을 때 초록색 자물쇠가 보이는 경우 이는 트래픽이 암호화되었다는 의미이고 트래픽이 암호화되지 않은 경우에는 빨간색 표시가 나타나며 트래픽이 암호화되지 않았으며 연결이 안전하지 않으니신용 카드나 로그인 정보를 넣지 말라는 경고가 나옵니다.
그리고 SSL 인증서에는 여러분이 설정한 유효 기간이 있고 인증을 위해 주기적으로 갱신되어야 합니다.

그러면 로드 밸런서 관점에서는 인증서가 어떻게 작동할까요?
유저가 HTTPS를 통해 연결됩니다. 이때 S는 SSL 인증서를 사용하고 있다는 의미이며 암호화되어 안전한 상태죠. 그리고 공용 인터넷을 통해 로드 밸런서와 연결되죠. 그리고 이때 로드 밸런서는 내부적으로 SSL 인증서 종료라는 작업을 수행합니다.
그리고 백엔드에서는 EC2 인스턴스와 통신할 수 있는데, HTTP를 사용하기 때문에 암호화는 되어 있지 않죠 하지만 트래픽은 어느 정도의 안전성을 보장하는 사설 네트워크인 VPC를 통해 전송됩니다. 그럼 로드 밸런서가 X.509 인증서를 불러옵니다. SSL 혹은 TLS 서버 인증서라고 불리는 인증서죠.
그리고 AWS에서 ACM을 사용해 SSL 인증서를 관리할 수 있습니다. ACM은 AWS 인증서 관리자의 약자죠. 이 강의에서는 ACM에 대해서 다루지 않겠지만 개념만 알려드린 겁니다
원하시면 여러분만의 인증서도 ACM에 업로드할 수 있습니다. HTTPS 리스너를 설정할 때는 기본 인증서를 지정해야 합니다. 그리고 다수의 도메인을 지원하는 인증서 선택 목록을 추가할 수 있죠. 그리고 클라이언트는 SNI, 즉 서버 이름 표시를 사용해서 도달하는 호스트 이름을 지정할 수 있습니다. 다음 슬라이드에서 SNI에 대해 자세히 살펴볼 테니 걱정 마세요. SNI의 개념을 이해하시는 게 굉장히 중요하거든요. 이 말인즉슨, 원하시는 경우 HTTPS에 대해 특정한 보안 정책을 설정할 수 있다는 의미로 레거시 클라이언트로 불리는 구형 TLS SLS를 지원하도록 지정할 수 있죠.
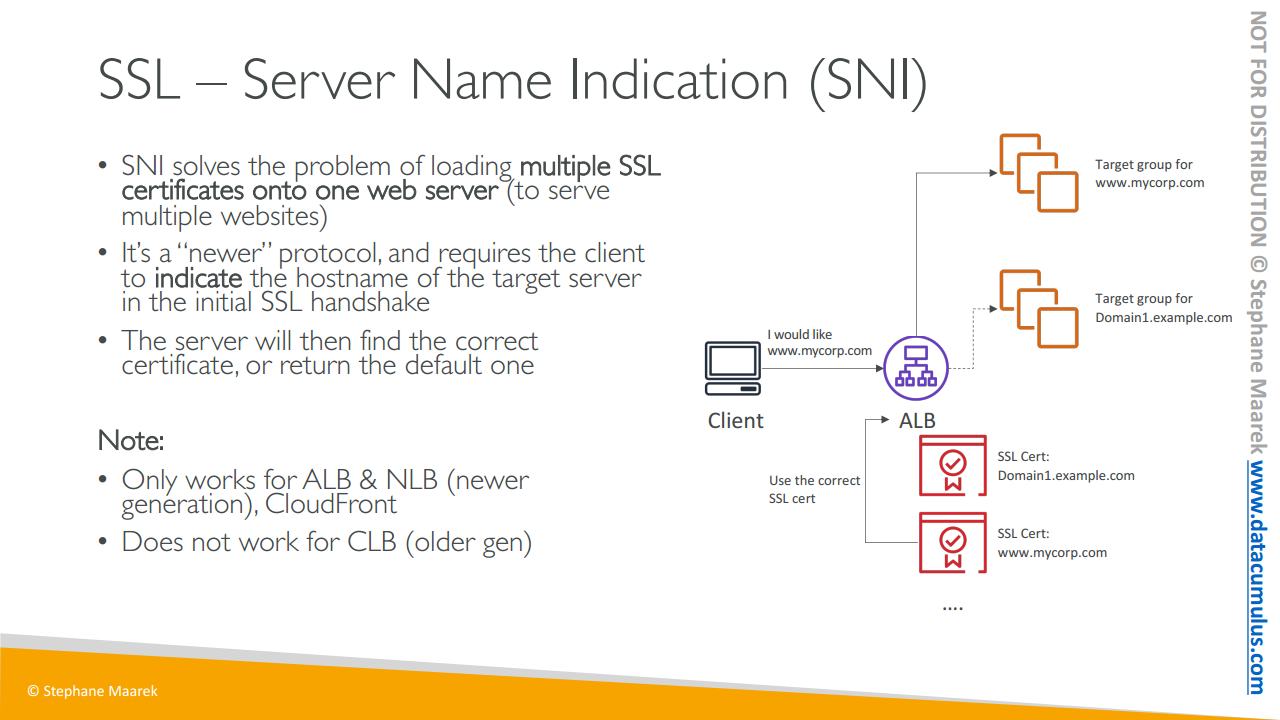
이제 아주 중요한 내용인 SNI를 살펴볼 차례입니다. SNI를 사용하면 한 웹 서버 상에 다수의 SSL 인증서를 발급해 단일 웹 서버가 여러 개의 웹 사이트를 제공하도록 하는 문제를 해결해 줍니다.
이는 최신 프로토콜이며 이를 위해서는 클라이언트가 초기 SSL 핸드셰이크에서 대상 서버의 호스트 이름을 명시해야 합니다. 즉, 클라이언트가 연결하고자 하는 웹사이트의 이름을 얘기하면 서버가 어떤 인증서를 불러올지 알 수 있겠죠
최신 프로토콜이기 때문에 모든 클라이언트가 이를 지원하지는 않습니다
이 프로토콜은 애플리케이션 로드 밸런서나 네트워크 로드 밸런서와 같은 최신 버전의 로드 밸런서나 클라우드 프론트에서만 작동하는데요. 클라우드 프론트는 이후 섹션에서 다룰 겁니다
그리고 이 프로토콜은 구형인 클래식 로드 밸런서를 사용하는 경우에는 작동하지 않죠.
따라서 로드 밸런서에 SSL 인증서가 여럿이라면 ALB 혹은 NLB 둘 중 하나라고 생각하시면 됩니다. 도면으로 살펴보겠습니다. 여기 ALB가 있고 대상 그룹은 두 개입니다. 첫 번째는 www.mycorp.com 두 번째는 Domain1.example.com이죠
ALB는 몇 가지 규칙에 따라 대상 그룹으로 라우팅을 할 텐데요 이 경우 규칙은 호스트 이름과 직접적인 관련이 있을 수 있죠. 그럼 ALB에 두 개의 SSL 인증서가 있겠죠. Domain1.example.com 또 www.mycorp.com입니다. 각각 대상 그룹에 해당되는 인증서죠.
이제 클라이언트가 ALB에 연결해서 www.mycorp.com에 연결을 요청합니다. 서버 이름 표시라고 할 수 있죠. 그럼 ALB는 클라이언트가 mycorp.com 연결을 요청했음을 확인하고, 요청에 맞는 SSL 인증서를 사용할 겁니다.
따라서 알맞은 SSL 인증서를 사용해 트래픽을 암호화하고 규칙 덕분에 mycorp.com이 올바른 대상 그룹임을 알 수 있는 거죠. 물론 또 다른 클라이언트가 Domain1.example.com를 요청하는 경우에도 올바른 SSL 인증서를 사용해 올바른 대상 그룹에 연결해 주겠죠.
따라서 SNI, 즉 서버 이름 표시를 사용하면 서로 다른 SSL 인증서를 사용하여 다른 웹사이트로 연결되는 다수의 대상 그룹을 가질 수 있죠.

좋습니다, 그러면 SSL 인증서를 어디에서 지원이 되는지 봅시다.
클래식 로드 밸런서에서는 하나의 SSL 인증서만 지원합니다. 여러 SSL 인증서가 있는 다중 호스트 이름이 필요한 경우에는 다수의 클래식 로드 밸런서를 사용하는 게 가장 좋죠
ALB는 v2라고도 하며 다중 SSL 인증서를 가진 다수의 리스너를 지원할 수 있어서 유용하죠. 그리고 이때는 방금 살펴본 SNI를 사용합니다.
NLB, 네트워크 로드 밸런서는 다중 SSL 인증서를 가진 다수의 리스너를 지원하며 역시 SNI를 사용합니다
--- 실습
그럼 클래식 로드 밸런서를 살펴보겠습니다
Listners 탭으로 이동하면
여기 편집 버튼으로 HTTPS 리스너를 추가할 수 있습니다
암호도 설정해야 하죠
지원하고자 하는 프로토콜이 보이고 보안 암호가 있습니다
이제 SSL 인증서를 설정합니다
여기로 바로 가져와서 수동으로 인코딩할 수 있으며
ACM, Amazon 인증서 관리자로부터 인증서를 선택할 수도 있는데요
당장은 없어서 사용할 수가 없네요
여기서 제가 보여드리고 싶은 건
HTTPS 인증서를 여기서 설정할 수 있고
하나의 SSL 인증서만 지원한다는 점입니다
여기까지 클래식 로드 밸런서였고
애플리케이션 로드 밸런서에서도 리스너를 추가하겠습니다
이번 리스너는 HTTPS이고
기본 행동은 Forward to로 전달 그리고 대상 그룹을 선택합니다
보안 정책은 이렇게 설정됐는데
기본 SSL 인증서는 어떻게 설정하면 될까요?
from ACM, from IAM 아니면 Import 중에서
원하는 인증서를 선택할 수 있죠
각각의 규칙에 대해서
별개의 SSL 인증서를 가질 수 있으며
그러면 SNI, 서버 이름 표시를 사용할 수 있기 때문에
다양한 대상 그룹에 대해 다수의 SSL 인증서를 가질 수 있죠
좋습니다
지금 하진 않을 겁니다
아직 올바른 인증서가 없는 상태죠
NLB 또한 Listners 탭에서 리스너를 추가할 수 있습니다
여기는 안전한 TCP를 위해 TLS로 설정할 수 있고
역시 마찬가지로 기본 SSL 인증서는
ACM이나 IAM에서 불러오거나 혹은 수동으로 입력할 수 있죠
이번 강의는 여기까지입니다
설정이 어떻게 되는지를 보여드렸죠
CLB는 구형 버전으로 SNI를 지원하지 않는다는 점
기억해 두세요
반면 ALB와 NLB는, SNI 및 다중 SSL 인증서를 지원하죠
82. Elastic Load Balancer (ELB) - 연결 드레이닝

이제 시험에 나올 수 있는 기능을 살펴봅시다
바로 연결 드레이닝입니다. 사실 다른 이름도 있는데 클래식 로드 밸런서를 사용할 경우에는 연결 드레이닝이라 부르고 애플리케이션 밸런서나 네트워크 로드 밸런서를 사용하는 경우에는 등록 취소 지연이라고 부릅니다.
인스턴스가 등록 취소, 혹은 비정상인 상태에 있을 때 인스턴스에 어느 정도의 시간을 주어 인-플라이트 요청, 즉 활성 요청을 완료할 수 있도록 하는 기능이죠. 연결이 드레이닝되면 즉 인스턴스가 드레이닝되면 ELB는 등록 취소 중인 EC2 인스턴스로 새로운 요청을 보내지 않는 거죠.
도면을 보며 이해해 보도록 하겠습니다
EC2 인스턴스가 세 개 있습니다. 그리고 그 중 하나는 드레이닝 모드로 설정할 겁니다. 그러면 EC2 인스턴스에 이미 연결된 유저는 충분한 드레이닝 시간을 얻게될 것이고 기존 연결 및 기존 요청을 완료할 수 있을 겁니다. 그리고 작업이 끝나면 모든 연결이 정지되죠.
만약 새로운 유저가 ELB에 연결하려고 하면 ELB는 기존의 EC2 인스턴스가 드레이닝 상태에 있으므로 새로운 연결은 다른 EC2 인스턴스와 수립될 거라는 점을 알고 있습니다. 두 번째나 세 번째 EC2 인스턴스를 사용하겠죠.
연결 드레이닝 파라미터는 매개변수로 표시할 수 있습니다. 1부터 3,600초 사이의 값으로 설정할 수 있는데 기본적으로는 300초, 즉 5분입니다. 그리고 이 값을 0으로 설정하면 전부 다 비활성화할 수 있죠. 값이 0이면 드레이닝도 일어나지 않는다는 뜻입니다.
짧은 요청의 경우에는 낮은 값으로 설정하면 좋습니다. 예를 들어 1초보다 적은 아주 짧은 요청인 경우에는 연결 드레이닝 파라미터를 30초 정도로 설정하면 됩니다. 그래야 EC2 인스턴스가 빠르게 드레이닝될 테고 그 후에 오프라인 상태가 되어 교체 등의 작업을 할 수 있겠죠. 요청 시간이 매우 긴, 즉 업로드 또는 오래 지속되는 요청 등의 경우에는 어느 정도 높은 갚으로 설정하면 됩니다. 그러면 EC2 인스턴스가 금방 사라지지는 않겠죠 연결 드레이닝 과정이 완료되기를 기다려야 할 겁니다.
83. Auto Scaling Group(ASG) 개요

이제 ASG(오토 스케일링 그룹)가 무엇인지 알아봅시다.
웹사이트나 애플리케이션을 배포할 때 웹사이트 방문자가 갈수록 많아지면서 로드가 바뀔 수 있습니다. 그리고 우리는 클라우드 즉 AWS에서 EC2 인스턴스 생성 API 호출을 통해 서버를 빠르게 생성하고 종료할 수 있다고 배웠습니다.
이를 자동화하고 싶다면 ASG를 생성할 수 있습니다. 이 부분이 중요한데 ASG의 목표는 스케일 아웃 즉 증가한 로드에 맞춰 EC2 인스턴스를 추가하거나 그리고 스케일 인 즉 감소한 로드에 맞춰 EC2 인스턴스를 제거하는 겁니다. 따라서 ASG 크기는 시간이 지나면서 변할 것입니다. 또한 ASG에서 실행되는 EC2 인스턴스의 최소 및 최대 개수를 보장하기 위해 매개변수를 전반적으로 정의할 수도 있습니다.
ASG는 또 한 가지 멋진 기능이 있습니다. 로드 밸런서와 페어링하는 경우 ASG에 속한 모든 EC2 인스턴스가 로드 밸런서에 연결됩니다.
다른 멋진 기능은 한 인스턴스가 비정상이면 종료하고 이를 대체할 새 EC2 인스턴스를 생성합니다
ASG는 무료이며 EC2 인스턴스와 같은, 생성된 하위 리소스에 대한 비용만 내면 됩니다.
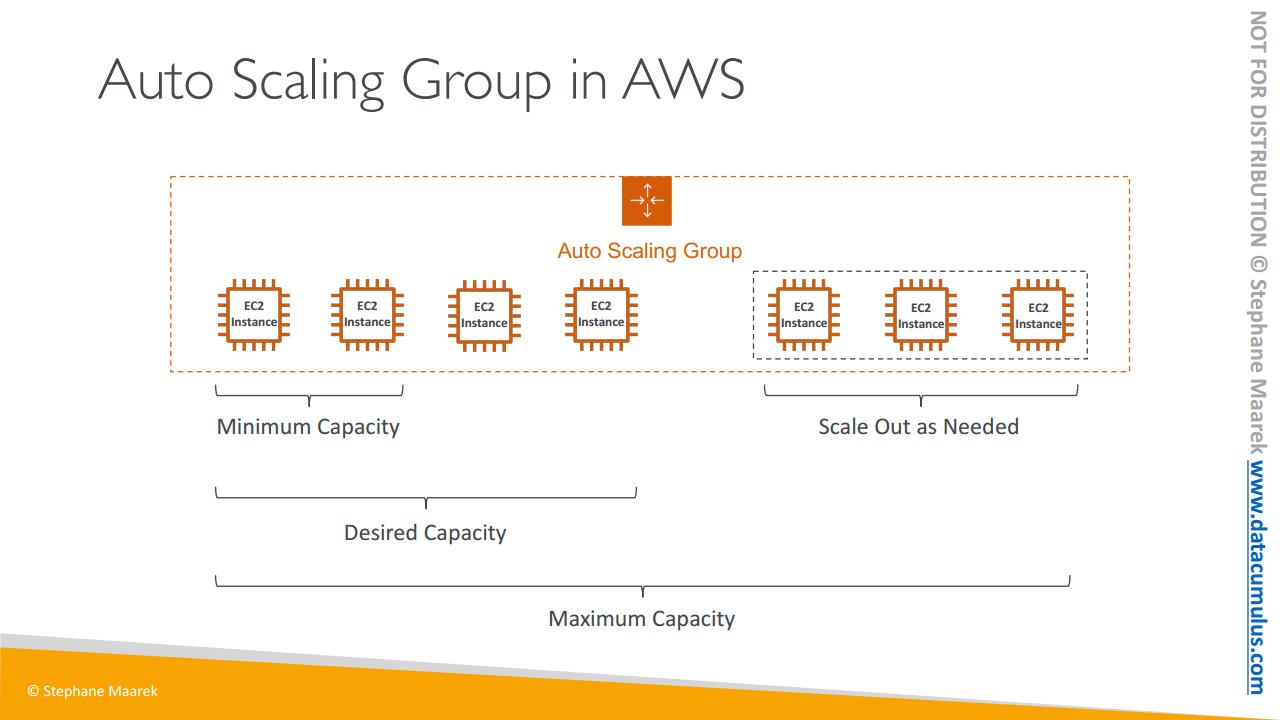
그럼 ASG가 AWS에서 어떻게 작동하는지 봅시다.
먼저, 최소 용량 즉 ASG 내 인스턴스의 최소 개수를 설정합니다. 예를 들어 2개로 설정할 수 있겠죠. 다음으로 희망 용량 즉 ASG 내 인스턴스의 희망 개수를 설정합니다. 예를 들어 4개로 설정할 수 있겠죠. 마지막으로, 최대 용량 즉 ASG 내 인스턴스의 최대 개수를 설정합니다. 최대 용량 내에서 희망 용량을 더 높은 숫자로 설정하면 스케일 아웃이 됩니다. 즉, EC2 인스턴스를 추가합니다. 따라서 ASG가 점점 더 커지겠죠. 예시의 경우 최대 용량은 7입니다
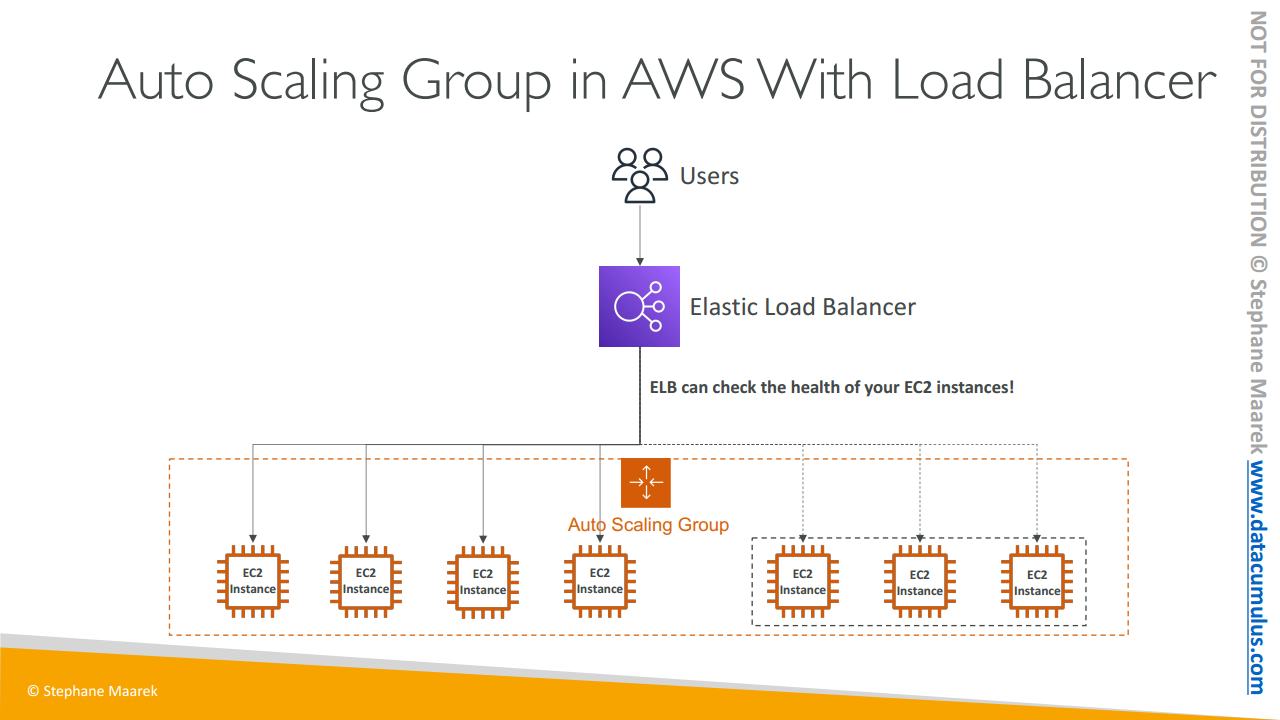
ASG는 로드 밸런서와도 작동한다고 했었죠. 따라서 ASG에 4개의 인스턴스가 등록되어 있으면 ELB(Elastic Load Balancer)가 모든 인스턴스에 트래픽을 즉시 분산하여 사용자가 로드 밸런싱된 웹사이트에 액세스 가능토록 합니다
게다가 ELB는 상태 확인을 통해 EC2 인스턴스의 상태를 확인하고 ASG로 전달할 수 있습니다. 따라서 로드 밸런서가 비정상이라 판단하는 EC2 인스턴스를 ASG가 종료할 수 있어 매우 편리합니다.
또한, 스케일 아웃이 되면 즉 EC2 인스턴스를 추가하면 ELB가 트래픽을 보내고 로드를 분산시킬 것입니다. 따라서 로드 밸런서와 ASG은 정말 좋은 조합입니다

인스턴스 속성을 기반으로 ASG를 생성하려면 시작 템플릿(Launch Template)을 생성해야 합니다. 이전에 존재했던 시작 구성(Launch Configurations)은 더 이상 사용되지 않지만 개념은 같습니다. 시작 템플릿에는 ASG 내에서 EC2 인스턴스를 시작하는 방법에 대한 정보가 포함되어 있습니다.
다음과 같은 정보인데 AMI 및 인스턴스 유형, EC2 사용자 데이터, EBS 볼륨, 보안 그룹, SSH 키 페어, EC2 인스턴스의 IAM 역할, 네트워크 및 서브넷 정보, 로드 밸런서 정보 등 더 많은 정보가 있습니다.
이러한 모든 매개변수는 EC2 인스턴스를 생성할 때 지정한 매개변수와 매우 유사합니다. 또한 ASG의 최소 크기, 최대 크기 초기 용량을 정의해야 합니다. 스케일링 정책 또한 정의해야 하죠.

스케일링 정책이 나왔으니 CloudWatch 경보(Alarms)가 오토 스케일링과 통합되는 방식을 살펴보겠습니다.
아직 CloudWatch에 대해 잘 모르실 텐데 간략하게 설명하겠습니다
CloudWatch 경보를 기반으로 ASG를 스케일 인 및 스케일 아웃할 수 있습니다. 예를 들어, 세 개의 EC2 인스턴스를 포함한 ASG가 있는데 경보가 울리게 되면 스케일 아웃이 발생합니다
그럼 무엇이 경보를 울릴까요?
정답은 지표(metric)입니다 즉 모니터링할 수 있는 평균 CPU나 원하는 사용자 지정 지표 어떤 것도 지정할 수 있습니다. 예를 들어, ASG 전체의 평균 CPU가 너무 높으면 EC2 인스턴스를 추가가 필요한데 지표에 따라 경보가 울리고 경보가 ASG의 스케일링 활동을 유발합니다. 이것이 오토 스케일링 그룹이라고 불리는 이유입니다. 경보에 의해 내부에서 자동적인 스케일링 이루어지죠. 경보를 기반으로 스케일 아웃 정책을 만들어 인스턴스 수를 늘리거나 스케일 인 정책을 만들어 인스턴스 수를 줄일 수 있습니다. 그리고 이 모든 것들이 함께 ASG를 구성합니다.
84. Auto Scaling Group (ASG) 실습
오토 스케일링 그룹(ASG)을 사용해서 연습해 봅시다
우선 모든 인스턴스를 선택하고
실행 중인 EC2 인스턴스가 없도록 전부 종료하세요
이제 오토 스케일링 그룹을 생성해 보겠습니다
왼쪽 Auto Scaling Groups 메뉴로 이동하세요
첫 오토 스케일링 그룹을 만들게요 Create Auto Scaling group을 클릭하고
오토 스케일링 그룹 이름은 DemoASG라고 할게요
Launch template을 참조해야 하는데
Create a launch template을 클릭해서 생성할게요
실행 템플릿의 이름은 MyDemoTemplate이고
설명도 지정해야 합니다
Template, 좋습니다
스크롤을 내려서 다른 옵션도 지정합니다
우리가 사용할 AMI, 즉
Amazon Machine Image의 경우 Quick Start 메뉴로 가서
Amazon Linux 2의 버전 x86으로 선택합니다
이 AMI는 프리 티어로 사용할 수 있으니 좋아요
다음으로 인스턴스 유형은 프리 티어인 t2.micro입니다
프리 티어 옵션이면 상관 없어요
아래 Key pair의 경우 EC2 Tutorial을 선택해요
이렇게 설정하면
실행 템플릿 내부, 즉 제 ASG 내부에서
EC2 인스턴스가 시작되는 방식을 정의할 수 있죠
EC2 인스턴스가 자체적으로 실행될 때와
비슷한 옵션을 사용하고 있어요
Subnet에서는 서브넷을 실행 템플릿에 포함하지 않습니다
Firewall 보안 그룹은 기존에 있던 launch-wizard-1을 선택하세요
그리고 8 GiB와 gp2으로 스토리지 구성을 하고요
Advanced details에서 맨 아래로 스크롤을 내리면
User data를 찾을 수 있습니다
여기에 이전에 사용했던 사용자 데이터를 입력하겠습니다
붙여 넣으면 다 됐습니다
이렇게 하면 모든 EC2 인스턴스로
웹 서버가 생성되고 ASG의 일부가 됩니다
이제 다 됐습니다 Create launch template을 누를게요
MyDemoTemplate이 만들어졌습니다
새로 고침 하고 생성된 템플릿을 선택합니다
MyDemoTemplate은 버전 1이고
요약 정보가 있습니다 Next를 클릭해서 계속할게요
인스턴스 실행 옵션을 설정합니다
VPC는 기본으로 선택하고
서브넷으로 실행할 가용 영역 세 개도 선택합니다
eu-west-1a와 1b 그리고 1c예요
Instance type requirements에는 템플릿이 제공한 t2.micro가 있지만
원한다면 템플릿을 덮어쓸 수 있습니다
덮어쓸 경우 인스턴스 속성을 지정하거나
인스턴스 유형을 직접 추가하죠 온디맨드, 스팟 인스턴스와 함께
다양한 인스턴스 유형의 혼합을 가질 수 있습니다
확실히 더 고급 기능이지만 지금은 이대로 할게요
Instance type requirements은 템플릿에 따라
t2.micro만 선택하겠습니다
Next를 클릭하고 추가 설정을 구성하죠
로드 밸런싱은 선택용입니다
즉 ASG를 생성할 때
로드 밸런서가 없어도 되지만 그런 사용 사례는 별로 없습니다
우리에게는 이미 로드 밸런서가 있기 때문에
'존재하는 로드 밸런서에 연결'을 선택하겠습니다
그리고 DemoALB, 즉 애플리케이션 로드 밸런서
my-first-target-group을 선택하여
ASG의 일부로 실행된 EC2 인스턴스가
애플리케이션 로드 밸런서에 직접 연결되게 합니다
상태 확인도 선택사항이지만 두 가지 종류가 있어요
첫 번째 EC2 상태 확인은
EC2 인스턴스가 실패할 경우
오토 스케일링 그룹에서 자동으로 제거되게 합니다
저는 ELB 유형의 상태 확인을 활성화할게요
만약 ELB가 인스턴스를 비정상으로 간주하게 되면
ASG가 자동으로 인스턴스를 종료할 겁니다
추가 설정은 활성화하지 않고 내버려 둘게요
Next를 클릭하고 ASG 그룹 크기를 설정합니다
희망 용량은 1이고 최소 용량 1, 최대 용량 1이죠
ASG 내에 인스턴스가 하나라는 뜻입니다
그런데 최대 용량을 10으로 하면
ASG 용량을 1에서 10 사이로 다양하게 선택할 수 있습니다
지금은 모두 1로 유지합니다
스케일링 정책은 지금은 None으로 두고
자세한 내용은 나중에 살펴봅시다
Next를 클릭합니다
알림 및 태그 단계는 넘어가고
모두 검토한 다음에 Create Auto Scaling group을 누를게요
이제 오토 스케일링 그룹이 생성되었습니다
이제부터 오토 스케일링 그룹이
EC2 인스턴스를 한 개 생성해 줄 겁니다
오토 스케일링 그룹을 클릭하면
세부 사항을 알 수 있습니다 희망 및 최대, 최소 용량과
이 ASG에 사용된 실행 템플릿을 볼 수 있지요
그런데 Activity 탭에서
신기한 걸 볼 수 있습니다
ASG가 EC2 인스턴스를 생성하기로 결정하면
Activity notification에 기록이 나타나요
따라서 새로 고침 하면 아, hitory와 헷갈렸네요
Activity history에서 새로 고침 하면
여기에 새로운 인스턴스가 실행 중임을 알 수 있습니다
오토 스케일링 그룹 용량은 0인데 우리는 1을 원했기 때문에
그만큼 ASG에 있는 EC2 인스턴스 숫자를 늘려서
희망 용량과 일치하게 만든 거예요
Instance management 탭으로 가보면
보다시피 EC2 인스턴스 하나가 ASG에 의해 생성되었습니다
Instances 탭으로 이동하면
EC2 인스턴스가 현재 실행 및 초기화 중입니다
아주 좋아요
여기서 좋은 점은 대상 그룹과 연결하도록
우리가 ASG를 설정했기 때문에
왼쪽의 Target Groups 메뉴로 이동해서
my-first-target-group의
Targets 탭으로 들어가 EC2 인스턴스를 선택하면
EC2 인스턴스가 ALB에 등록 중임을 알 수 있죠
EC2 인스턴스 상태가 비정상으로 표시되는데
EC2 인스턴스가 아직 부트스트래핑 중이라 그런 거고요
하지만 조금 후에는 정상으로 표시될 겁니다
그런 다음 ALB에 등록됩니다
영상을 잠시 중단하고 기다릴게요
이제 인스턴스 상태가 정상입니다 그러면 ALB로 이동해서
새로 고침 하면 응답으로 Hello World를 얻죠
모두 작동되고 있습니다
ASG에서 인스턴스가 생성되었고 EC2 콘솔에서 확인할 수 있어요
로드 밸런서에 연결된 대상 그룹에 등록되었으며
따라서 로드 밸런서가 제대로 작동하고 있습니다
인스턴스가 정상이 되지 않고 계속 비정상인 상태라면
ASG가 비정상 인스턴스를 종료하도록 설정했으므로
해당 인스턴스가 종료되고
새 인스턴스가 생성될 겁니다
Activity history에 관련 기록이 있을 거예요
이런 일이 생기는 이유는
EC2 인스턴스가 잘못 구성되었기 때문입니다
보안 그룹 문제일 수 있고
EC2 사용자 데이터 스크립트 문제일 수 있죠
그러니 Q&A에 질문 전에 먼저 확인해 보세요
하지만 그런 문제들로 오류가 생길 수 있습니다
이제 EC2 인스턴스를 하나 만들었고 실행 중이니
스케일링을 해볼 수 있습니다
오토 스케일링 그룹 크기를 조정하면 됩니다
인스턴스 희망 용량을 2로 지정하고
최대 용량도 거기에 따라 늘릴게요
이렇게 업데이트합시다
그러면 ASG로 하여금
우리 대신 하나 이상의 EC2 인스턴스를 생성하게 합니다
Activity history를 새로 고침 하면
곧 새로운 활동 내용이 나타납니다
EC2 인스턴스를 시작하겠다는 내용일 거예요
네, 새로운 EC2 인스턴스를 실행 중이라고 표시됩니다
희망 용량을 1에서 2로 바꿨는데
ASG의 실제 인스턴스 개수는 하나뿐이라서
이렇게 두 번째 EC2 인스턴스가 생성되었어요
잠시 후에는 대상 그룹에
등록되고 추가될 겁니다
그 과정 동안 잠시 영상을 정지하겠습니다
인스턴스가 정상 상태니깐 ALB로 가볼게요
새로 고침 하면 두 개의 IP가 ALB를 통해 반복되고 있습니다
모두 잘 작동하고 있는 거죠
마지막으로 Activity 탭을 봅시다
EC2 인스턴스 두 개가 제대로 실행되었죠
반대의 경우를 살펴볼까요
용량을 낮춰서
희망 용량을 1로 되돌리고 업데이트해 보겠습니다
이렇게 업데이트하면
인스턴스가 두 개 있는 상태에서 이제는 하나만 필요하기 때문에
ASG가 여기 있는 인스턴스 중 하나를 선택하고
종료시킬 겁니다
보다시피 인스턴스 하나를 종료 중이라고 하네요
ASG 구성을 변경해서 그렇습니다
따라서 인스턴스가 종료되면 대상 그룹 등록이 해제됩니다
그러면 ASG에 다시 하나의 EC2 인스턴스만 남겠죠
이번 강의는 여기까지입니다 ASG의 모든 기능을 살펴보았고
다음은 자동 스케일링에 대해 이야기해 보겠습니다
85. Auto Scaling Group (ASG) 조정 정책

오늘은 오토 스케일링 그룹의 스케일링 정책에 대해 살펴보겠습니다
두 가지로 나뉘는데
먼저 동적 스케일링 정책부터 보겠습니다. 동적 스케일링 정책은 세 가지 유형이 있습니다. 첫 번째는 대상 추적 스케일링으로 가장 단순하고 설정하기도 쉽죠. 예를 들면 모든 EC2 인스턴스에서 오토 스케일링 그룹의 평균 CPU 사용률을 추적하여 이 수치가 40%대에 머무를 수 있도록 할 때에 사용합니다. 이처럼 기본 기준선을 세우고 상시 가용이 가능하도록 하는 거죠.
단순과 단계 스케일링은 좀 더 복잡합니다. CloudWatch 경보를 설정하고 가령 다음과 같이 전체 ASG에 대한 CPU 사용률이 70%를 초과하는 경우 용량을 두 유닛 추가하도록 설정할 수 있죠. 그리고 전체 ASG 내의 CPU 사용률이 30% 이하로 떨어지면 유닛 하나를 제거한다는 설정도 추가할 수 있습니다. 단 CloudWatch 경보를 설정할 때에는 한 번에 추가할 유닛의 수와 한 번에 제거할 유닛의 수를 단계별로 설정할 필요가 있습니다
마지막으로 예약된 작업이 있습니다. 나와 있는 사용 패턴을 바탕으로 스케일링을 예상하는 거죠. 예를 들어서 금요일 오후 5시에 큰 이벤트가 예정되어 있으니 여러 사람들이 애플리케이션을 사용하는 데에 대비해 여러분의 ASG 최소 용량을 매주 금요일 오후 5시마다 자동으로 10까지 늘리도록 하는 겁니다. 스케일링이 필요함을 미리 알 때에 예정된 작업을 설정하면 됩니다.
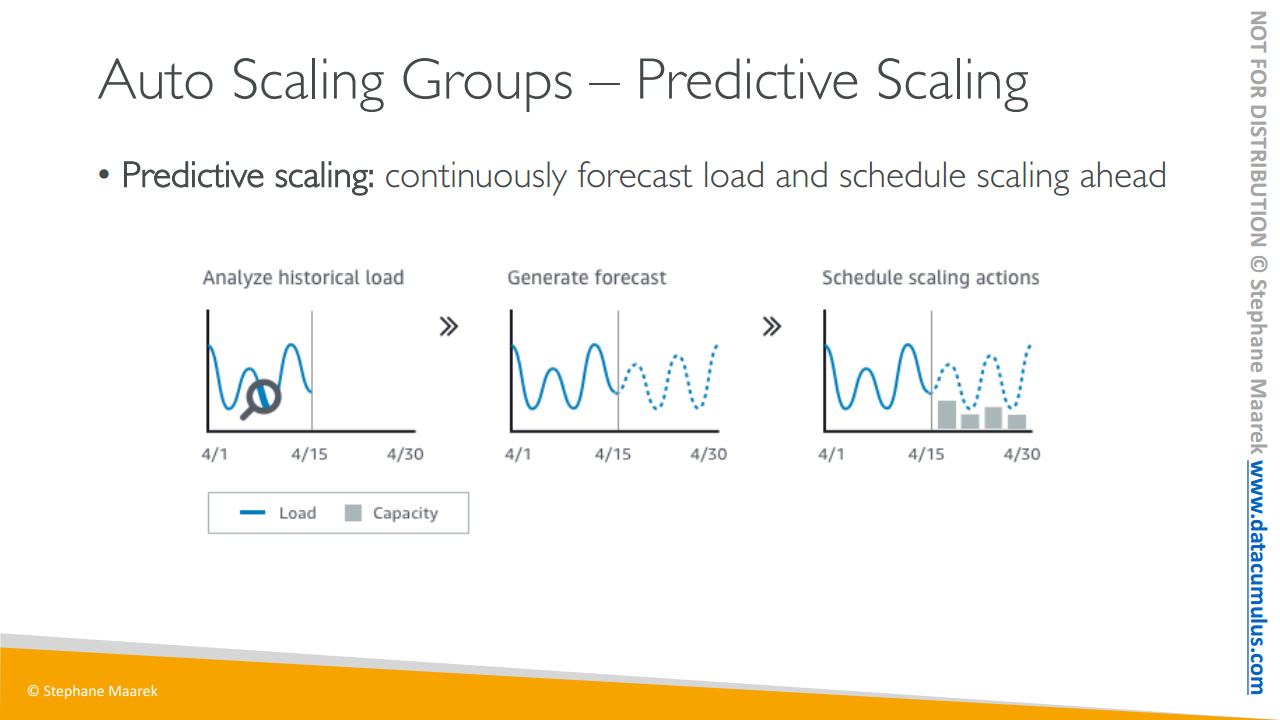
그리고 새로운 스케일링 중 하나로 예측 스케일링이 있습니다. 예측 스케일링을 통해서 AWS 내 오토 스케일링 서비스를
활용하여 지속적으로 예측을 생성할 수 있습니다. 로드를 보고서 다음 스케일링을 예측하는 거죠.
시간에 걸쳐 과거 로드를 분석하고 예측이 생성됩니다. 그리고 해당 예측을 기반으로 사전에 스케일링 작업이 예약됩니다. 이 또한 대단한 스케일링 방법 중 하나로 제 생각에는 머신 러닝을 기반으로 하며 손쉬운 ASG 오토 스케일링 중 하나인 예측 스케일링이 향후 더욱 대두될 겁니다.
따라서 스케일링 기반이 될 훌륭한 지표가 있어야겠죠. 여러분의 애플리케이션의 목적과 작동 방식에 따라 달라지긴 하지만 대표적인 것들을 살펴보겠습니다
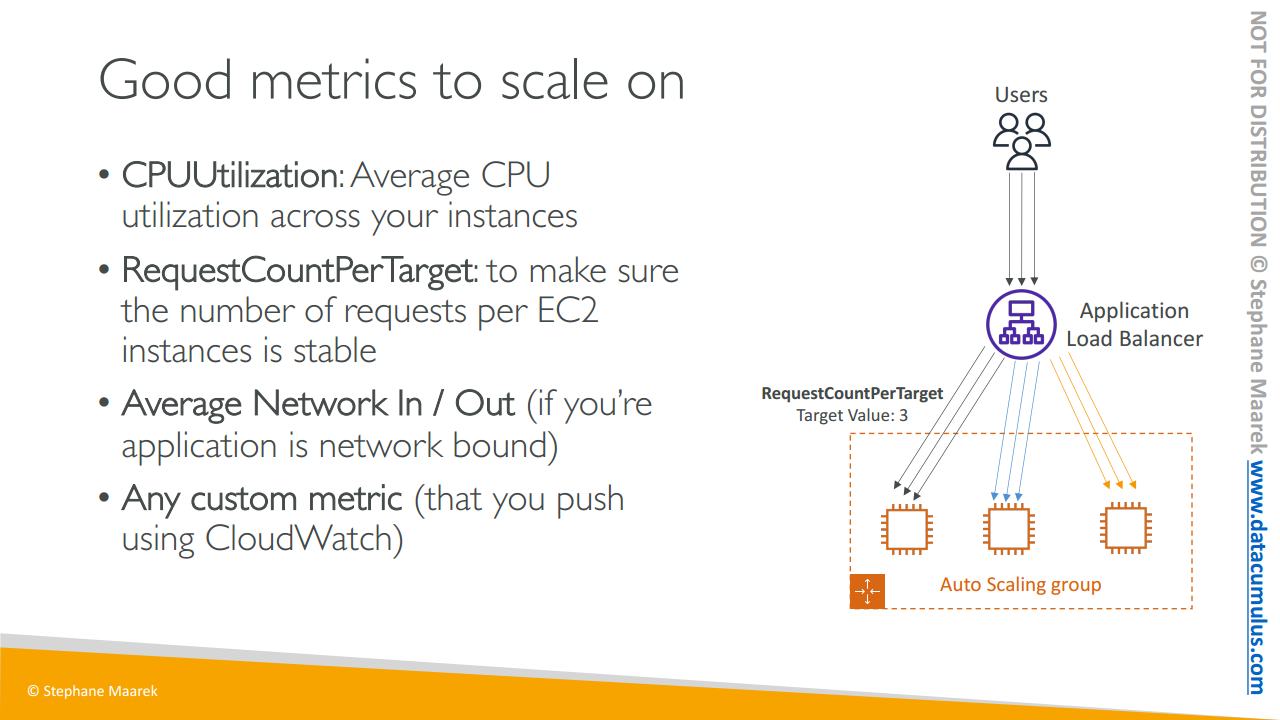
첫째로는 CPU 사용률을 들 수 있습니다. 일반적으로 인스턴스에 요청이 갈 때마다 일종의 연산이 수행되어야 하므로 이 과정에서 일부 CPU가 사용됩니다. 모든 인스턴스의 평균 CPU 사용률을 봤을 때 이 수치가 올라가면 인스턴스가 잘 사용되고 있다는 의미이니 스케일링에 있어서 좋은 지표가 될 겁니다.
또 다른 지표를 보겠습니다. 애플리케이션에 따라 다를 수 있습니다만 테스트를 기반으로 하는 대상별 요청의 수를 들 수 있습니다. EC2 인스턴스는 한 번에 대상별로 1,000개의 요청까지만 최적으로 작동하므로 바로 이 대상을 스케일링에 활용할 수 있겠습니다.
예시를 하나 살펴보죠. 세 개의 EC2 인스턴스를 갖는 오토 스케일링 그룹이 있으며 현재 ALB에서 이들 전체로 요청이 분산되어 나가고 있습니다. 따라서 현재 대상별 요청 수 지표는 3이 됩니다. 평균적으로 각 EC2 인스턴스에 세 개의 미해결 요청이 있기 때문이죠.
다음으로는 애플리케이션이 네트워크에 연결된 경우 예를 들어서 업로드와 다운로드가 많아 EC2 인스턴스에 대해 해당 네트워크에서 병목 현상이 발생할 것으로 판단된다면 평균 네트워크 입출력량을 기반으로 스케일링을 수행해서 특정 임계값에 도달할 때 스케일링을 수행하도록 설정할 수 있습니다.
또는 여러분이 직접 CloudWatch에서 애플리케이션 별로 지표를 설정하고 이를 기반으로 스케일링 정책을 바꿀 수 있습니다.

스케일링 정책 중 또 다른 중요한 내용으로는 스케일링 휴지(Scaling Cooldown)입니다. 스케일링 작업이 끝날 때마다 인스턴스의 추가 또는 삭제를 막론하고 기본적으로 5분 혹은 300초의 휴지 기간을 갖는 것입니다. 휴지 기간에는 ASG가 추가 인스턴스를 실행 또는 종료할 수 없습니다. 이는 지표를 이용하여 새로운 인스턴스가 안정화될 수 있도록 하며 어떤 새로운 지표의 양상을 살펴보기 위함입니다.
따라서 스케일링 작업이 발생할 때에 기본으로 설정된 휴지가 있는지 확인해야 합니다. 그럴 경우에는 해당 작업을 무시하고 아닐 경우에는 인스턴스를 실행 또는 종료하는 스케일링 작업을 수행하는 거죠.
즉시 사용이 가능한 AMI를 이용하여 EC2 인스턴스 구성 시간을 단축하고 이를 통해 요청을 좀 더 신속히 처리하는 것이 좋습니다. EC2 인스턴스 구성에 할애되는 시간이 적으면 즉시 적용이 가능할 테니 말이죠. 이렇게 활성화 시간이 빨라지면 휴지 기간 또한 단축되기 때문에 ASG 상에서 더 많은 동적 스케일링이 가능해집니다. 또한 ASG가 일 분마다 지표에 접근할 수 있도록 세부 모니터링 기능 등을 사용하도록 설정하고 이와 같은 지표를 신속히 업데이트할 필요가 있습니다.
86. Auto Scaling Group(ASG) - 스케일링 정책 실습
이제 ASG에 대한 오토 스케일링을 살펴보도록 하죠
보셨던 바와 같이 세 가지 범주로 나뉘죠
각각 동적 스케일링과 예측 스케일링 정책 그리고 예약된 작업입니다
가장 단순한
예약된 작업부터 보면, 이를 통해서 향후 스케일링 작업을 예약할 수 있습니다
Create를 눌러 보죠
희망 용량 Desired capacity 또는 최소 Min이나 최대 Max 용량을 설정합니다
일주일에 한 번인지 매시간마다 인지
혹은 특정한 예약 주기를 정할 수도 있죠
그리고 시작 시간과 끝 시간을 정할 수도 있습니다
설정이 아주 단순하며 미리 예정되어 있고
사전에 알고 있는 이벤트에 대해서 작업을 예약할 수 있습니다
가령 다음 주 토요일에 대규모 프로모션이 진행될 때에 이 기능을 사용할 수 있겠죠
다음으로는 예측 스케일링 정책이 있는데 이는 머신 러닝을 기반으로 합니다
예측을 토대로 스케일링을 수행하죠
과거를 바탕으로 실제 정책과 실제 스케일링을 살펴볼 필요가 있습니다
그리고 지표를 확인해야겠죠
예를 들어서 CPU 사용률 또는 네트워크 입출력량
애플리케이션 로드 밸런서 요청 수 혹은 사용자 지정 지표가 있습니다
예를 들어서
인스턴스 당 50%의 CPU 사용률을 대상으로 설정할 수 있습니다
추가 설정 또한 가능하죠
단, 이와 더불어서 실제 지난주 예약된 사용률을 기반으로
예측이 생성되며
이에 따라서 ASG가 스케일링됩니다
지금 당장 여러분에게
예시를 보여 드릴 수는 없습니다 일주일가량 애플리케이션을
돌린 후에 그 사용량을 봐야 하니 말이죠
그래도 예측 스케일링 정책 설정이 쉽다는 것은 살펴볼 수 있습니다
사용하고자 하는 지표와 대상 사용률을 지정하기만 하면
머신 러닝이 적용된 스케일링 작업이 시작되죠
함께 살펴볼 수 있는 정책으로는 동적 스케일링 정책이 있는데
직접 생성해 보도록 하죠
세 가지 옵션이 나오는데
대상 추적, 단계 스케일링 단순 스케일링이 있습니다
단순 스케일링 먼저 살펴보죠
정책 이름을 설정하라는 칸 다음에 CloudWatch alarm 칸이 나오는데
경보가 발동될 때마다 용량이 스케일링됩니다
그전에 경보를 생성해 주어야 하는데 그 부분은 나중에 살펴보도록 하죠
경보가 발동되었을 시에는
용량 유닛 두 개를 추가하도록 설정하거나
그룹의 10%를 추가하도록 설정할 수 있습니다
혹은 용량 유닛을 두 개로 합친 만큼의 용량 유닛을 추가할 수도 있죠
지금까지 단순 스케일링 정책이었습니다
이 스케일링 정책으로 스케일 아웃일 때 인스턴스를 추가하는 Add나
스케일 인일 때 인스턴스를 제거하는 Remove 작업을 수행할 수 있죠
혹은 Set to 작업도 지정할 수 있습니다
다음은 단계 스케일링입니다
이 정책은 경보 값을 기준으로 여러 단계를 갖도록
다수의 경보를 설정할 수 있습니다
가령 경보 값이 아주 높은 경우에는
10개의 용량 유닛을 추가하도록 설정할 수 있죠
단, 너무 높지 않은 경우에는 하나만 추가하는 거죠
단계 스케일링 정책의 원리입니다
여기서는 대상 추적 스케일링 정책을 사용할 텐데요
이 정책을 통해서 CloudWatch 경보를 생성할 수 있기 때문입니다
정책 이름은 Target Tracking Policy
이를 통해 평균 CPU 사용률의 대상 값을 40으로 두고 추적합니다
이제 Create으로 정책을 생성해 주겠습니다
이제 정책 내용을 보면
본 ASG의 목표가 CPU 사용률을 40으로 유지하는 것이라고 나와 있습니다
그리고 이를 초과할 때는 용량 유닛을 추가하도록 설정되었죠
이 정책이 작동하는 것을 보려면 몇 가지 사항을 변경해야 합니다
현재는 최소 Min과 희망 용량 Desired가 1로 설정되어 있습니다
이때 최대 Max 용량을 2나 3으로 설정해 줍니다
이를 통해서 최대 용량이
최소 용량을 넘어
1에서 2나 3까지 증가하도록 설정한 거죠
목적은 오토 스케일링 그룹에 대한
CPU 사용률이 대상 값인 40에 도달하도록 하는 겁니다
지금은 CPU 사용률이 0으로 나오겠죠
EC2를 살펴보겠습니다
EC2 인스턴스도 현재 수행하는 작업이 없으니 0에 가까운 수치를 보일 겁니다
지금부터 EC2로 이동해서
CPU 사용률이 100%에 달하도록 stress를 실행해 보겠습니다
EC2 인스턴스로 이동한 다음
Connect를 이용해서 EC2 인스턴스를 연결하고
구글에서 install stress Amazon Linux 2를 입력해 줍니다
몇 가지 명령이 나오는데 첫 번째 명령을 복사해서 입력해 줍니다
그리고 두 번째 명령을 복사해서 stress를 설치해 줍니다
이제 stress가 설치되었군요
그리고 stress - C 4 명령을 실행하면
한 번에 4개의 vCPU가 사용되면서
네 개의 CPU 유닛을 활용함에 따라 CPU 사용률이 100%가 됩니다
이렇게 하면 현재 CPU 사용률이 100%에 달하는데
ASG의 현재 상태를 보면 CPU Utilization이
상당히 높게 상승했다는 것을 볼 수 있습니다
그리고 Activity에서 스케일링 작업을 살펴보도록 하죠
한 개의 인스턴스에서 두 개의 인스턴스가 됐는지를 보는 겁니다
지금부터 잠깐 동영상을 멈추고
현재 CPU 사용률이 아주 높다는 것을 지표가 제대로 파악할 시간을 주겠습니다
그런 다음 대상 추적 정책이 어떻게 작동하는지 함께 알아보죠
Activity에서 Activity History를 보면
경보가 발동되었으며
대상 추적 정책으로 인해
용량이 하나의 인스턴스에서 두 개의 인스턴스로 늘어났다는 내용이 나옵니다
Instance management를 보면 스케일링으로 인해 이제 두 개의 EC2 인스턴스가 표시됩니다
Monitoring에서 EC2를 살펴보면
CPU Utilization 즉 사용률이 스케일링 후 크게 높아졌습니다
스케일링 작업을 확인하려면 Automatic scaling으로 가서
Target Tracking Policy를 직접 볼 수 있습니다
여기서 백엔드를 한번 살펴볼 텐데
cloudwatch 서비스를 검색하고
CloudWatch로 이동합니다
좌측에 있는 Alarms로 이동합니다
보이는 것처럼 대상 추적 정책에 대해 두 개의 경보가 생성되었습니다
하나는 AlarmHigh로 스케일 아웃 시에 인스턴스를 추가하고
또 다른 하나는 AlarmLow로 스케일 인일 때 인스턴스를 제거합니다
AlarmHigh는 CPU 사용률이
3분 이내에 세 개의 데이터 포인트에 대해
40%에 도달하는지를 확인하고 경보 상태로 바꾸며
AlarmLow는 CPU 사용률이
15분 이내에 15개 데이터 포인트가 28%에 도달하는지를 확인하고 작동합니다
이로써 AlarmHigh의
지표가 경보 상태로 발동된 상태임을 알 수 있는데
이는 CPU 사용률이 정해져 있던 제한치를 초과함으로써
오토 스케일링 그룹에 대한 스케일링 활동이 수행된 것이며
이에 따라 새로운 인스턴스가 사용되기 시작한 겁니다
다시 stress로 이동해서 이 명령을 멈춰 보죠
중지가 가능한지는 모르겠지만 말입니다
그대로 닫아 보겠습니다
이 명령을 중지한 다음
EC2 인스턴스를 재부팅해 보도록 하죠
아마 이 인스턴스였던 것 같습니다
재부팅해 보죠
이 인스턴스도 재부팅하고
아닐 수 있으니 여기 이 인스턴스도 재부팅해 보겠습니다
이것으로 CPU 사용률이 다시 0으로 돌아가고
15분 이내에 스케일링 작업이 시작될 겁니다
다시 잠깐 동영상을 멈추고 본 ASG에 대해
Activity 상에 새로운 스케일링이 시작되는지 살펴보도록 하겠습니다
지금부터 잠깐 멈추도록 하죠
하지만 여전히 CPU 사용률이 높은 상태이며
희망 용량이 2에서 3으로 설정되어 있기 때문에
또 다른 인스턴스가 추가되는 것을 볼 수 있습니다
오토 스케일링 그룹의 성능을 보여 주는 거죠
Instance managements를 보면 세 개의 EC2 인스턴스가 나와 있습니다
종료될 때까지 좀 더 기다려야겠군요
Activity를 살펴보면 더 많은 동작이 현재 수행되고 있습니다
인스턴스 중 일부는 이미 종료되었습니다
경보가 낮은 CPU로 이동할 때
즉 용량이 3에서 2로 이동할 때
그리고 2에서 1로 이동함에 따라 종료된 거죠
다시 Instance Management를 보면 인스턴스 하나는 이미 종료되었고
남은 하나는 종료 중이라고 표시됩니다
즉 대상 추적 정책이 작동 중임을 알 수 있죠
Alarms에 표시된 이 경보가 작동 중인 것인데
여기서 알 수 있듯 CPU Utilization이
증가했다가 다시 감소하며 28%라는 임계값을
지나자마자 경보가 발동됩니다
이때부터 ASG가 인스턴스를 제거하기 시작하는 거죠
지금까지 대상 추적 정책을 살펴봤습니다
모든 작업이 끝나면 해당 정책을 필히 삭제하시고
정리 단계로 돌입하시면 됩니다
그럼 다음 강의에서 뵙도록 하겠습니다
87. Auto Scaling Group(ASG) - 솔루션 아키텍트용 + 나중에
ASG의 솔루션 설계자로서 알아야 할 두 가지 사항이 더 있습니다
첫 번째는 인스턴스가 종료되는 방식에 규칙이 있다는 겁니다. 기본적으로 ASG 기본 종료 정책이 있고 좀 더 단순한 버전이 있습니다.
먼저 가장 많은 인스턴스가 있는 AZ를 찾습니다. 그런 다음 AZ에 선택할 인스턴스가 여러 개인 경우 가장 오래된 실행 구성이나 실행 템플릿이 있는 인스턴스를 삭제합니다
오른쪽에 있는 그림을 보면 오토 스케일링 그룹이 있고 두 개의 가용 영역이 있습니다. 하나는 A에 두 개의 v1 인스턴스
두 개의 v2 인스턴스가 실행 구성으로 되어 있고
AZ B에는 세 개의 v1 인스턴스가 있습니다
v1은 가장 오래된 실행 구성입니다
그러나 보시듯 오토 스케일링 그룹은
AZ A를 인스턴스로 선택할 겁니다
가장 많은 인스턴스를 가진 가용 영역이기 때문이죠
그래서 AZ A가 선택되고
가용 영역 A에 있는 네 개의 인스턴스 중
ASG는 v1 인스턴스를 선택할 겁니다
가장 오래된 실행 구성을 갖고 있기 때문입니다
기본 종료 정책을 사용하는 ASG는
AZ 전체에 걸쳐 인스턴스 수의 균형을 맞추려고 합니다
사용자가 알아두어야 할 사항이죠
짜잔 바로 이 인스턴스가
사라지게 됩니다
수명 주기 후크는 ASG의 또 다른 기능입니다
기본적으로 ASG에서 인스턴스가 실행되자마자 서비스가 시작되지만
인스턴스를 실행할 때 발생하는
긴 프로세스가 있습니다
따라서 인스턴스가 실행되면 보류 상태가 되고
보류 상태에서 수명 주기 후크를 정의하면
인스턴스가 보류 대기 상태로 바로 전환되고
해당 인스턴스를 구성하거나 많은 작업을 수행할 수 있는 옵션이 생깁니다
그런 다음 준비가 되면 보류 중인 진행으로 이동합니다
보류 중인 진행에 들어가면 바로 서비스가 시작됩니다
수명 주기 후크가 없는지 확인 후
보류에서 서비스 중으로 바로 바뀝니다
인스턴스가 서비스 중으로 선언되었는지 확인하기 전에
추가 소프트웨어를 설치할 수 있는 옵션이 있는 개념입니다
비슷하게 이벤트에 스케일링이 수행돼서
인스턴스가 종료되면
종료 상태가 됩니다
종료 상태에서 수명 주기 후크를 정의하면
종료 대기 상태가 된 다음
종료 진행 이후에 종료됩니다
종료 수명 주기 후크가 있는 이유는 무엇일까요?
예를 들어 ECM2 인스턴스가
완전히 종료되기 전에 로그 또는 파일에 대한 정보를
추출하려는 경우
수명 주기 후크를 사용하는 사례가 될 수 있습니다
이 부분은 시험에도 출제될 수 있습니다
이제 실행 템플릿과 실행 구성의 차이점에 대해 이야기해 보겠습니다
실행 템플릿과 실행 구성은 모두
EC2 인스턴스의 AMI ID를 지정할 수 있습니다
인스턴스 유형 연결하려는 키 페어
보안 그룹 및 태그 EC2 사용자 데이터 등과 같이
원하는 파라미터들을 지정할 수 있습니다
이 두 가지를 모두 써서 ASG의 일부로
EC2 인스턴스를 실행하는 방법을 정의할 수 있습니다
다만 실행 구성은 레거시로 간주되므로
단일 매개변수를 업데이트할 때마다
다시 생성되어야 합니다
실행 템플릿은 ASG의 새로운 기능이고
AWS도 사용하길 권장합니다
그 이유는 실행 템플릿이 여러 버전을 가지기 때문에
버전 관리가 되어서죠
파라미터의 서브셋을 생성해서
여러 템플릿에서 재사용하고
상속해야 하는 부분 구성을 정의할 수 있습니다
또 온디맨드 인스턴스와 스팟 인스턴스를 혼합하여
프로비저닝하여 실행 구성보다
비용 구조가 더 나은 스팟 플릿을 갖게 될 수 있습니다
T2 무제한 버스트 기능도 사용할 수 있습니다
그리고 말씀드렸듯 AWS에서 권장합니다
시험 중에 질문을 볼 때
실행 구성보다 실행 템플릿을
쓰는 것이 더 편할 겁니다
매우 오래된 기술인데다가 완전히 대체된 실행 구성을
쓸 이유가 없다고 저는 생각합니다
실행 템플릿이 훨씬 더 낫고
최신입니다
실행 템플릿과
실행 구성에 대해 알아야 할 사항은
여기까지입니다
재밌으셨길 바라며 다음 강의에서 뵙겠습니다
'자격증들 > 22) AWS Certified SAA' 카테고리의 다른 글
| AWS Certified Soultions Architect Associate Day 10(Route 53) (0) | 2022.11.02 |
|---|---|
| AWS Certified Soultions Architect Associate Day 09(RDS+Aurora+ElastiCache) (0) | 2022.10.26 |
| AWS Certified Soultions Architect Associate Day 07(EBS) (0) | 2022.10.19 |
| AWS Certified Soultions Architect Associate Day 06(EC2-SAA) (0) | 2022.10.19 |
| AWS Certified Soultions Architect Associate Day 04(EC2) (0) | 2022.09.29 |



