[ 실습 ]
1. Registry 만들기
2. AWS S3를 만들어서 파일을 저장하고 다운받기
- file storage : NFS, CIFS(shared storage - 폴더형태)
- block storage : FC, iSCSI(volume)
- object storage : 사용자에게 저장공간 제공. user별 저장공간 제공 ( key-value 형태 )
최종 S3를 local directory의 특정 디렉토리와 연결
로컬 서버(DB) --- sync, cp --- s3@aws
(mgmt) /var/lib/mysql
cron을 이용해서 db를 s3에 백업하는 작업하기
매번 올릴때마다 그날 그날의 날자로
[ 사설 저장소 ]
도커는 이미지 저장을 위해 3곳의 저장소를 운영가능
1. local repo : 현재 도커를 사용하고 있는 컴퓨터 또는 서버, 로컬 저장소에 등록된 이미지는 다른 사용자와 공유가 불가능
2. private repo : 다른 사용자들과 저장 공간(이미지)를 공유할 수 있으나 지정된 사용자, 지정된 위치, 지정된 서버에서만 접속, pull, push가 가능하다. docker-hub에서 registry를 생성시 "Private"을 선택하면 가능하다.
-> 이후에 그룹을 생성하고 그룹내에 사용자를 추가해야 한다. 그룹별, 사용자 별로 role 지정이 가능하므로 수정, push, pull을 제한할 수 있다.(일반 사용자는 pull 만 가능하도록) 단, 비용발생함.
aws, gcp, azure는 프로젝트 단위로 클라우드를 사용할 수 있다. 프로젝트에 참여하는 팀원들이 생성한 이미지를 팀원간에만 공유하고 싶을 것이다. 퍼블릭 클라우드는 이러한 이미지 저장소를 프로젝트 내에 제공하며 허가된 사용자의 접속만을 허용한다. 이렇듯 퍼블릭 클라우드 내에서도 사설 저장소를 생성하여 운영할 수 있다.
Private Docker Registry를 구축하기 위한 오픈소스 Harbor 도입기 - LINE ENGINEERING (linecorp.com)
Private Docker Registry를 구축하기 위한 오픈소스 Harbor 도입기 - LINE ENGINEERING
안녕하세요. LINE+에서 엔지니어로 일하고 있는 이지현입니다. 저는 현재 전 세계에 퍼져 있는 수많은 LINE 엔지니어들이 좀 더 효율적으로 업무를 수행할 수 있도록 여러 가지 공통 엔지니어링
engineering.linecorp.com
예시중 하나인 Harbor 도입기
3. public repo : docker-hub의 public 으로 생성한 저장소는 공인저장소가되며 모든 사용자들이 이미지를 검색하고 pull 할 수 있다.
docker search mysql
mysql -> 도커에서 제공한 오피셜 버전(기본 이미지)
user1/mysql:1.0 -> 사용자가 만든
aws에도 두개의 계정이 있다.
루트 사용자 -> 회사 계정으로 개발자, DB 등을 정의할 수 있게 된다. 그리고 IAM 사용자를 정의해서 사용할 수 있는 기능의 범위를 제한한다.

---
[ registry ] 를 이용한 사설 저장소 구축
- 필수 조건 : https를 사용해야 한다. 인증서를 미리 발급받고 해당 인증서가 사설 저장소에서 발급한 인증서인지 여부를 확인한 뒤 접속이 가능하도록 할 수 있다.
- 인증서 발급을 위해서는 사전에 인증기관이라 할 수 있는 CA(Certificate Authority)가 생성되어 있어야 한다. 또한 인증서 발급을 해 두어야 한다.
- 이를 통해 이미지 pull/push가 될 경우 보안성을 보장 받을 수 있다.
- 우리는 CA 문제가 해결되지 않았기에, https가 아닌 http를 통해 접속이 되도록 만들기. 그래서 웹페이지 자체가 따로 필요하다.
1. 패키지 설치하기
sudo yum -y install nfs-utils
sudo yum -y install yum-utils device-mapper-persistent-data lvm2
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
sudo yum -y install docker-ce
먼저 docker을 설치하자
2. registry 배포하기
docker container run -d -p 5000:5000 --name registry --restart=always registry실재로 이미지를 배포할때 전체가 다 올라가는 않고 기존 이미지 대비 차이나는 부분만을 저장한다고 한다.
이와 유사하게 코드 형상관리도구로 git이 존재한다. 각각의 버전을 commit 하면 이미지가 만들어진다. 그러면 이 지점을 관리하기 위한 commit 번호도 만들어진다. 실제 활용은 7자리만 사용한다. 그리고 버전별 변경사항도 따로 만들어진다.

docker container exec registry ls
하면 registry 컨테이너에 ls 명령어를 던질 수 있다.
docker container exec registry ls /var/lib/registry
그리고 이미지가 저장될 공간은 /var/lib/registry 이다.
이제 이미지를 storage의 주소인 211.183.3.199:5000으로 넣어주자
(만약 user1/test:1.0 으로 업로드하면 public 저장소에 이미지를 넣어준다.)
????
이때 사용자를 차단하기 위해서 https가 아닌 http를 이용하여보자
일단 docker hub로 로그인
docker login
<docker hub 아이디>
<docker hub 패스워드>
테스트용 이미지 다운로드 -> docker pull nginx
이름 바꾸기
docker tag nginx:latest 211.183.3.199:5000/newnginx:1.0

cd /var/lib/docker/image/overlay2/imagedb/content/sha256
가보면 이미지의 갯수만큼 무언가가 있다.

위와같이 이미지가 바뀌지 않았는데 tag를 붙이면 이미지의 갯수는 그대로 유지된 상태로 남는다.
이 상태에서 이미지를 그냥 올릴려고 하면 에러가 난다.
docker push 211.183.3.199:5000/newnginx:1.0
https를 통한 접근이 아니므로 로컬에 있는 도커는 이를 차단. 우리는 보안성이 없는 상태에서 이를 push/pull 할 수 있도록 조정하기
3. insecure 모드로 이미지 push 하기
이미지를 push 하는 곳에서 설정해야 함. 만약 5대의 도커에서 이미지 사설 저장소를 사용한다면 5대 모두에서 아래의 설정을 해야한다.
cd /etc/docker
vi daemon.json
{
"insecure-registries":["211.183.3.199:5000"]
}위와같이 입력해주자.

이제는 업로드가 된다.
실재로 registry의 결과를 확인해보자
docker container exec registry ls /var/lib/registry/docker/registry/v2/repositories

해당 파일이 존재한다.
하지만 이건 너무 기니까 더 간단하게 보기 위해
curl http://211.183.3.199:5000/v2/_catalog
위치의 값을 긁어와보자

curl http://211.183.3.199:5000/v2/newnginx/tags/list

5. private registry web-ui 배포하기
이제 이 저장소를 웹에서 볼 수 있기 위해 웹을 앞에다 두자
docker run -d -p 8080:8080 --name registry-web --link registry \
--restart=always \
-e REGISTRY_URL=http://registry:5000/v2 \
-e REGISTRY_NAME=localhost:5000 \
hyper/docker-registry-web
정상적으로 Web Registry를 확인할 수 있다.
도커는 자체적으로 DNS를 사용하기 떄문에 생성된 모든 컨테이너에 대하여 이름을 자체 DNS ????(문서에 적혀있음)

개발자가 명령을 주면 Kubelet을 통해 명령이 docker에 전달되고 Pod을 생성한다. 사용자는 Network Proxy를 따라서 DNS를 타고 Pod에 접속한다.
8. (Quiz) manager에서 nginx를 도커 허브에서 pull 한 다음 211.183.3.199:5000/newnginx:2.0을 push 해보기
web-ui에서도 확인 가능해야 한다.
KVM1에 있는 manager을 원격에서 만지기 위해서 mgmt 에서 이걸 처리해주어야 한다.
그래서 mgmt로 이동한 다음
cd ~/.ssh
conn=ssh -i /root/.ssh/gildong.pem root@211.183.3.128
$conn docker pull nginx
$conn docker tag nginx:latest 211.183.3.128:5000/newnginx:2.0
$conn echo "{"insecure-registries":["211.183.3.199:5000"]}" > /etc/docker/daemon.json
$conn docker push nginx:latest 211.183.3.128:5000/newnginx:2.0
이제 처음에는 manager가 대리인을(ansible, terraform) 통해 모든 worker 들에게 명령을 전달해줄것이다.
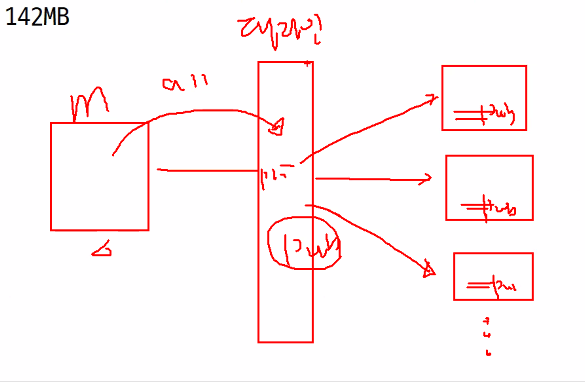
이제 manager에 commit 을 올릴것인데 git이 바뀔때마다 이를 감지하고 호스팅 해주는 곳이 필요해진다.
대표적인 호스팅 하는 곳이 github, bitbucket, gitlab이 존재한다. 여기에 올리면 얘네들이 바뀐것을 감지해서 명령들을 ansible에 전달해주는 jenkins가 필요하다.
9. s3 다루기

mgmt에 가서 /var/lib/mysql에 가보니 우리가 만든 db가 보인다.
이중에서 sqldb를 다루어보자
이중에서 clouddb를 aws s3에 백업해보자.
백업하는 방법도 여러가지가 있는데
1. 로컬에 백업하기
2. 원격지에 백업하기 -> 워크벤치 이용하여 윈도우에 백업하기
-> 다른 서버/스토리지에 백업하기
-> cloud에 백업하기 : S3 이용하기. 로컬에 있는 DB와 클라우드에 있는 DB를 연결
1) S3를 이용합 웹호스팅
2) DB 데이터를 S3의 버킷에 보관하기
- S3
어디에서나 원하는 양의 데이터를 저장하고 검색할 수 있도록 구축된 객체 스토리지
객체 스토리지 : 계층 구조가 없고, 고유 식별 번호와 데이터 그리고 메타 데이터 등 최소한의 정보만을 가지고 있기 때문에 파일 개수가 많아져도 파일 스토리지에 비해 많은 수의 파일들을 처리할 수 있음. 일반적으로 수십억 단위의 파일까지 처리할 수 있음

계층적 구조가 아님. Object 형태로 되어 있음
파일 스토리지
어떤 애플리케이션은 공유 파일에 액세스해야 하고 파일 시스템이 있어야 한다. 이러한 유형의 스토리지는 NAS(Network Attached Storage) 라고 하며, 서버에서 주로 지원된다. AWS 는 EFS(Elastic File System) 이라 불리는 파일 스토리지도 제공하는데, 주로 대규모 콘텐츠 저장소, 개발환경, 미디어 스토어 또는 사용자 홈 디렉토리 등과 같은 환경에 적합하다
블록스토리지
데이터베이스 또는 ERP 시스템과 같은 기타 엔터프라이즈 애플리케이션은 지연 시간이 짧은 전 용 스토리지가 필요한 경우가 많습니다. 이러한 스토리지는 DAS(Direct Attached Storage) 또는 SAN(Storage Area Neetwork) 를 사용한다. AWS 에서는 EBS(Elastic Block Store)와 같은 블록 기반 스토리지 솔루션을 제공한다. 개별 가상 서버로 제공되기 때문에 고성능 워크로드에 필요한 짧은 지연 시간을 사용하는 작업에 적합하다.
얘는 IP와 같이 데이터 손실이 없게 보낼 수 있도록 한다.
????
S3 기본
- 파일 크기는 0 바이트 부터 5TB 까지 저장가능
- 파일수는 제한없음. 무제한 저장가능
- S3 버킷은 폴더 혹은 파티션과 유사하며 각 버킷별로 접근 권한이나 보안 설정 등을 다르게 지 정할 수 있음
- 버킷은 웹 사이트의 주소나 DNS 주소를 갖기 때문에 중복되는 이름을 만들 수 없다. 따라서 모든 리전에서 유일해야 한다.
- HTTPS 를 제공하고, AWS IAM 등을 통해 인증된 사용자만 데이터에 접근할수 있으며, 별도의 프 로그램 설치나 개발을 하지 않아도 콘솔 화면에서 간단히 설정가능하다
- 새로운 파일을 덮어쓸 때 기존 파일에 대한 정보를 유지키시고 싶다면, 버저닝(versioning)을 활성화하여 백업본을 만들 수도 있다
global 환경에 만들고 리전을 선택해서 배포한다.그리고 이 파일을 http로 연결이 가능해진다.
결국 버킷은 S3 내에서 unique 해야 한다. 마치 공인 IP와 유사하다.

S3 스탠다드
일반적은 형태. AWS 자체적으로 여러 가용 영역에 백업을 하기 때문에 2곳 이상의 가용 영역에 서 문제가 생기지 않는 이상, 작동에 문제가 없도록 설계되어 있음. 높은 가용성을 유지하는 만큼 가격이 높음
S3-IA(Infrequently Accessed)
비교적 사용이 적은 편이지만, 빠른 전송속도를 필요로 할 때 설정할 수 있음. S3에 비해 가격이 저렴하지만, 호출 될 때마다 추가 비용이 발생. 데이터의 백업용으로 적합
S3 One-Zone-IA
자주 사용하지도 않고 중요하지도 않은 데이터에 사용. 비용은 저렴하지만 S3 스탠다드에 비해 내구성이 낮음
Glacier
가격이 저렴한 저장 장치. 주로 데이터를 백업하여 저장하기 위한 용도로 많이 사용

먼저 AWS에 들어와서 S3로 이동하자
버킷에 객체를 넣는다. 객체는 반드시 "key: value" 형태로 정의가 가능해야 한다.

이름을 위와같이 만들고 ACL은 접속못하게 만들자

모든 퍼블릭 액세스를 차단하되 그 안에 포함된 객체가 퍼블릭 상태가 될 수 있음을 알고 있다고 넣어주자
나머지는 그대로 두고 생성하자
Free Bootstrap Themes & Templates - Start Bootstrap
Free Bootstrap Themes & Templates - Start Bootstrap
Landing Page A clean, functional landing page theme
startbootstrap.com
Bootstrap Template에서 하나를 가져오자

이 녀석의 파일을 받아와보자

드래그 앤 드랍으로 파일을 업로드해주자

편집을 누르자

버킷 ARN을 복사해오자
그리고 정책 생성기를 누르자



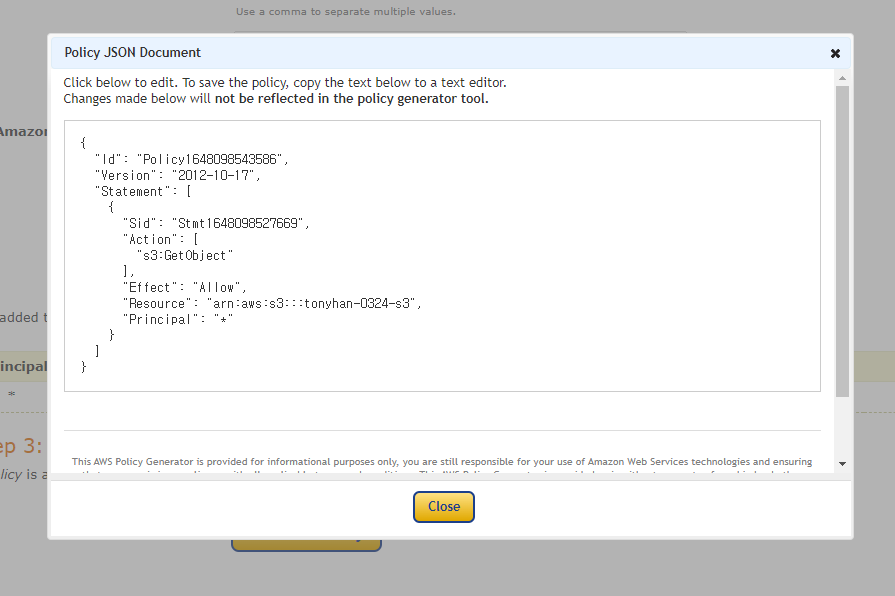

정책을 복붙하면 완성이다.

하지만 가끔식 접속이 안되는 경우가 생기기 때문에 끝에 별을 붙여주자.
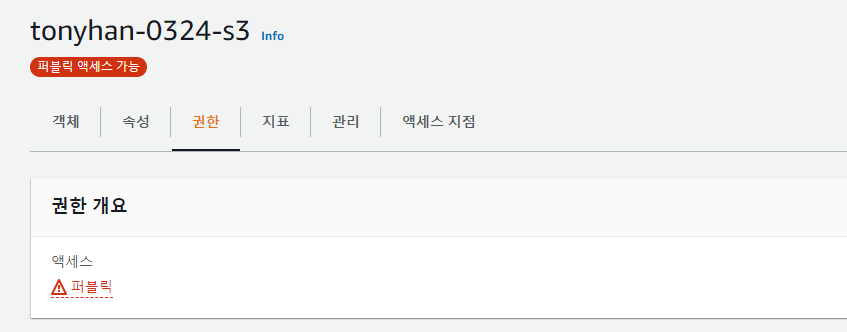
속성으로 가보자

정적 웹 사이트 호스팅으로 사용자가 실재로 접속이 가능하도록 만들어보자

정적 웹 사이트 호스팅 편집에서 활성화를 누르고 인덱스 문서와 오류 문서에 위와같이 작성해주자

호스팅 되었다.

정상적으로 페이지가 보인다.
이걸 실재 웹사이트와 연결하기 위해서는 DNS에서 이걸 CNAME으로 연결해주어서 짧은 주소와 연결되도록 할 수 있다.
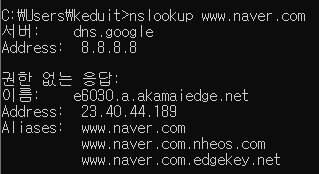
이게 무슨 말이냐면 naver도 서버명이 naver.com이 아니다. 3개의 추가적인 이름을 써서 연결하고 있다.
하지만 최종목표는 DB 정보를 S3에 보관(저장, 복사)하기이다.
awscli를 이용하여 DB 서버의 특정 디렉토리에 있는 파일들을 S3에 있는 버킷의 특정 디렉토리로 복사, 동기화 해 본다.
외부에서 S3를 관리할 수 있는 별도의 계정이 필요하다. 그 계정에 권한을 부여해야한다.
그래서 S3에 버킷 생성 -> 해당 버킷에서 폴더 생성 -> 로컬서버에서 특정 디렉토리를 S3의 디렉토리와 동기화하거나 파일을 cp해서 넘겨준다.(오픈스택 glance)
- IAM 계정 생성(오픈스택 KeyStone)
---
일단 S3 관련 데이터를 삭제하자. 내부 오브젝트까지 모두 삭제해야 S3 삭제가 가능해진다.

IAM에 들어가서 사용자 탭으로 이동해서 사용자 추가를 해주자
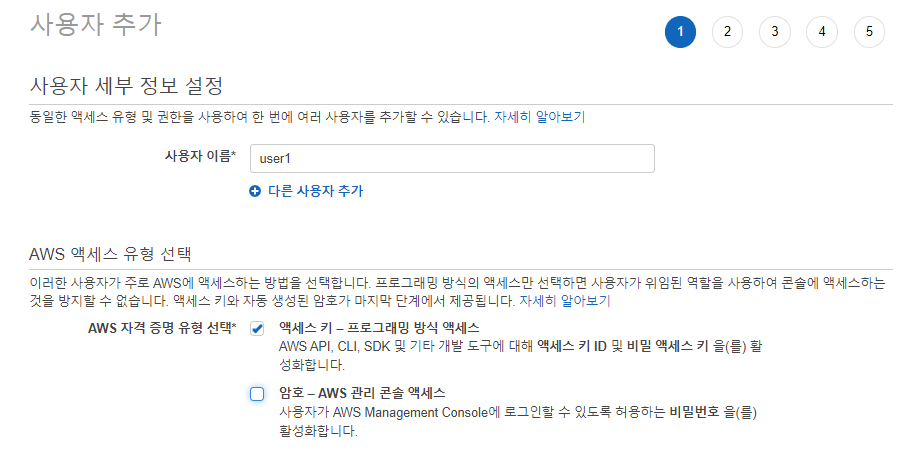
액세스 키는 개발 도구에 대한 액세스 키 ID 및 비밀 액세스 키를 활성화한다.
????
어짜피 들어와서 직접 볼거 아니면 암호 줄 필요가 없다.

기존 정책 직접 연결로 s3full을 넣어주자.

사용자가 보인다. csv 다운로드해서 이걸 이용하자

아까와 동일하게 이름만 바꾸어서 만들자.

만들어진 s3의 폴더 만들기에 들어가자

clouddb로 만들자

이 안에 데이터를 백업하자
---
다시 mgmt로 와서
1. aws cli 설치하기
yum install -y awscli
2. aws configure

aws configure을 입력하면 ID, key, name을 입력하는 cli가 나온다.
여기에다가 아까 저장한 정보를 기록하자

aws s3 ls 하면 우리가 생성한 BUCKET 정보가 보인다.

더 자세하게 들어가서
aws s3 ls s3://tonyhan-0324-backup/clouddb/ 를 입력하니 아무것도 없다고 뜨게 된다.
마지막으로 아래의 것을 입력해주자
aws s3 cp /var/lib/mysql/clouddb/* s3://tonyhan-0324-backup/clouddb/

위와같이 s3에 데이터가 올라간것을 확인할 수 있다.
Amazon EC2 인스턴스 시작, 나열 및 종료 - AWS Command Line Interface
Amazon EC2 인스턴스 시작, 나열 및 종료 - AWS Command Line Interface
이 페이지에 작업이 필요하다는 점을 알려 주셔서 감사합니다. 실망시켜 드려 죄송합니다. 잠깐 시간을 내어 설명서를 향상시킬 수 있는 방법에 대해 말씀해 주십시오.
docs.aws.amazon.com
더 자세하게 살피어 보기 위해 위의 링크로 들어가서 보면 아래와 같이 ec2에 인스턴스를 만들 수 있는 코드가 나오게 된다. 이거는 중요하니 꼭 기억해야 하는 링크이다.
aws ec2 run-instances --image-id ami-xxxxxxxx --count 1 --instance-type t2.micro --key-name MyKeyPair --security-group-ids sg-903004f8 --subnet-id subnet-6e7f829e
{
"OwnerId": "123456789012",
"ReservationId": "r-5875ca20",
"Groups": [
{
"GroupName": "my-sg",
"GroupId": "sg-903004f8"
}
],위와같은 것이 있기 때문에 좀 더 찾아봐서 아래의 퀴즈를 해보자
Quiz. crontab을 이용하여 5분마다 /var/lib/mysql/clouddb 디렉토리를 압축(tar 포함)하여 s3 버킷에 복사하라. 단, 파일의 이름은 아래의 형태여야 함.
ex. 2203240315.tar.gz -> s3에 복사
Bash Shell - 날짜, 시간 가져오기 (codechacha.com)
Bash Shell - 날짜, 시간 가져오기
Bash shell script에서 날짜, 시간을 가져오는 방법을 알아보겠습니다. 다음 코드들은 date의 실행 결과를 today 변수에 저장합니다. quotes(\`) 또는 `$`를 사용하는 방법 중에 하나를 선택하시면 됩니다.
codechacha.com
[LINUX] 크론탭 (Crontab) (tistory.com)
[LINUX] 크론탭 (Crontab)
기본 명령어 현재 작동중인 크론탭 보기 crontab -l 크론탭 등록 crontab -e 크론탭 편집기에서 주석 # Comment.. 크론탭 전체 삭제 crontab -d 크론 탭 등록 방법 1. 같은 파일에 덮어 씌우는 방법 스케줄러_
sunghs.tistory.com
대충 위의 두개를 이용해서 다음과 같이 만들어주자
copymysql.sh
#!/bin/bash
now=`date +%Y%m%d%H%M`
tar -zcvf $now.tar.gz /var/lib/mysql/clouddb/*
aws s3 cp $now.tar.gz s3://tonyhan-0324-backup/clouddb/
crontab -e
*/5 * * * * /root/0324/copymysql.sh
Quiz. 각각의 파일과 디렉토리는 stat을 통해 atime, ctime, mtime을 확인할 수 있다.
atime : 파일에 접근한 시간
mtime : 파일 내용을 수정한 시간
ctime : 파일의 내용이 아니라 chmod, chown, 링크 등을 변경한 시간


일단 위와같이 version 주석 부분을 없애주자
find ./* -atime +2
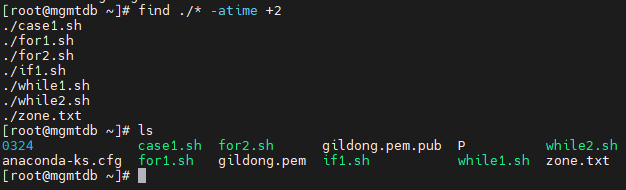
gildong.pem 등과 같은 파일은 보이지 않는다.
즉 접속한 시간이 2틀보다도 전에 만졌던 것들을 출력하라는 이야기이다.
find 와 a/c/mtime을 이용하여 파일을 백업하거나 백업된 파일을 자동으로 삭제, 보안 검색 등에 사용할 수 있다.
/usr/bin 아래에 있는 파일들이 1일 이내에 수정된 파일이 있다. 실행파일의 경우 파일내용이 수정될 일은 거의 없다. 하지만 수정이 되었다면 이는 보안 위협요인으로 의심할만하다. 이러한 파일을 찾아보자.
find /usr/bin/* mtime -2 로 명령어 중에 수정된 파일이 있는지 확인해볼 수 있다.
앞서 우리는 5분마다 파일을 백업했다. 이 파일들의 시간을 확인하여 2일이 지났다면 해당 파일을 삭제하는 스크립트 작성. 테스트를 위해 다음 명령어로
리눅스 날짜 기준으로 파일 삭제하기 - 제타위키 (zetawiki.com)
리눅스 날짜 기준으로 파일 삭제하기 - 제타위키
다음 문자열 포함...
zetawiki.com
위와같이 존재한다.
touch -t 201301010101 newfile
find ./* -mtime +2 -delete
#!/bin/bash
now=`date +%Y%m%d%H%M`
tar -zcvf /root/0324/$now.tar.gz /var/lib/mysql/clouddb/*
aws s3 sync /root/0324 s3://tonyhan-0324-backup/clouddb/
for i in $(find /root/0324 -mtime +2)
do
echo $i "is delete"
rm -rf /root/0324/$i
done
aws s3 sync /root/0324 s3://tonyhan-0324-backup/clouddb/ --delete
'Development(Web, Server, Cloud) > 22) LINUX - Cloud' 카테고리의 다른 글
| 클라우드 57일차 (0) | 2022.03.27 |
|---|---|
| 클라우드 56 일차 (0) | 2022.03.25 |
| 클라우드 54일차 - 오픈스택 보강 (0) | 2022.03.22 |
| 클라우드 54일차 (0) | 2022.03.22 |
| 클라우드 53일차 (0) | 2022.03.21 |



