CKA 준비하기

학습 계획
이번주 ch2까지
다음주 ch3까지
그 다음주 ch5까지
그 다음주 ch7까지
한 다음주 7월 28-30 사이에 시험보기

curriculum/CKA_Curriculum_v1.26.pdf at master · cncf/curriculum · GitHub
GitHub - cncf/curriculum: 📚Open Source Curriculum for CNCF Certification Courses
📚Open Source Curriculum for CNCF Certification Courses - GitHub - cncf/curriculum: 📚Open Source Curriculum for CNCF Certification Courses
github.com
GitHub - cncf/curriculum: 📚Open Source Curriculum for CNCF Certification Courses
GitHub - cncf/curriculum: 📚Open Source Curriculum for CNCF Certification Courses
📚Open Source Curriculum for CNCF Certification Courses - GitHub - cncf/curriculum: 📚Open Source Curriculum for CNCF Certification Courses
github.com
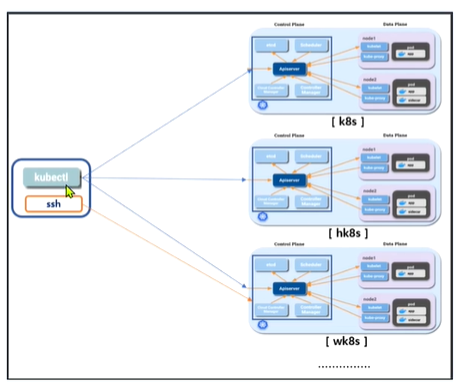
실습환경은 위와같이 생기었다.
멀티 클러스터에서 시험을 보아야 한다. 이 환경에서 시험을 보는 것에 익숙해져야 한다.

위와같이 우리 컴퓨터에 시스템을 구축하고 진행해주자.

https://kubernetes.io/docs/home/
Kubernetes Documentation
Kubernetes is an open source container orchestration engine for automating deployment, scaling, and management of containerized applications. The open source project is hosted by the Cloud Native Computing Foundation.
kubernetes.io
위의 문서에서 찾아보면서 문제를 풀면 된다.
Part2 Cluster Architecture, Inatllation & Configuration
01. ETCD Backup & Restore

- etcd : 마스터노드 저장소
노드마다 kubelet이 서비스 데몬 형태로 각 노드에서 동작중이다. 클러스터 운영중이다. 이 안에는 cAdvisor이 포함되어 있다.
하드웨어와 컨테이너 엔진의 다양한 이벤트와 정보들을 수집하는게 cAdvisor이다. kubelet은 수집된 정보를 마스터 API에게 보낸다. etcd에는 k8s의 모든 정보가 들어가 있다. API는 정보를 etcd에 key:value 형태로 저장한다.
etcd가 한 번 죽으면 전체가 죽기 때문에 etcd를 최소 3대 운영해준다.(5대, 7대도 가능하지만 보통 3대) => 3대 이상이면 고가용성 클러스터라고 부른다.
이 내용들은 모두 /var/lib/etcd 안에 저장되어 있다.
etcd도 pod 형태로 동작중이다.
yaml 파일을 보기 위해서는
```
cd /etc/kubernetes/manifests/
```
로 이동해서 etcd.yaml 을 확인해보면 된다.

저장공간을 별도의 파일로 보존하는 방법이 ETCD backup이다.
file 복제, 보존 == snapshot
restore == snapshot 상태로 되돌리기


ps -ef | grep kube | grep trusted-ca-file
ps -ef | grep kube | grep cert-file
ps -ef | grep kube | grep key-file
명령어 세개를 이용해서 cacert, cert, key 값 위치를 찾아내고 Backup 명령어에 넣어준다.
sudo ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
snapshot save /tmp/etcd-backup위와같이 명령어를 입력하면 백업파일이 /tmp/etcd-backup 폴더 안에 쌓이게 된다.
ETCDCTL_API=3 etcdctl snapshot restore --data-dir <data-dir-location> snapshotdb위의 명령어로 원복시키어 주면 된다.
[ 문제 ]

나중에는 인증서 파일은 시험에서 알려주기 때문에 이 키 파일이 무엇인지 알고 작업할 수 있다.
sudo ETCDCTL_API=3 etcdctl \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
snapshot save /tmp/etcd-snapshot.db
두 번째 문제
ETCDCTL_API=3 etcdctl \
--data-dir /var/lib/etcd-previous \
snapshot restore /data/etcd-snapshot-previous.db위의 형식으로 data-dir도 적절하게 정해주고 어떤 db를 가지고 올지도 적어준다.
02. kubernetes Upgrade

control plane 업그레이드 해주는 방법과 worker node 업그레이드 방법이 다르다.
control plane은 여러가지 컴포넌트가 있기 때문에 추가 작업이 발생한다.

https://kubernetes.io/ko/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/
kubeadm 클러스터 업그레이드
이 페이지는 kubeadm으로 생성된 쿠버네티스 클러스터를 1.26.x 버전에서 1.27.x 버전으로, 1.27.x 버전에서 1.27.y(여기서 y > x) 버전으로 업그레이드하는 방법을 설명한다. 업그레이드가 지원되지 않는
kubernetes.io
정확하게 어떤 버전으로 업그레이드 하라는 말이 나온다.
sudo cat /etc/os-release우선 내 os의 버전을 확인해준다.
나 같은 경우 ubuntu로 되어 있기 때문에 해당 명령어를 사용한다.
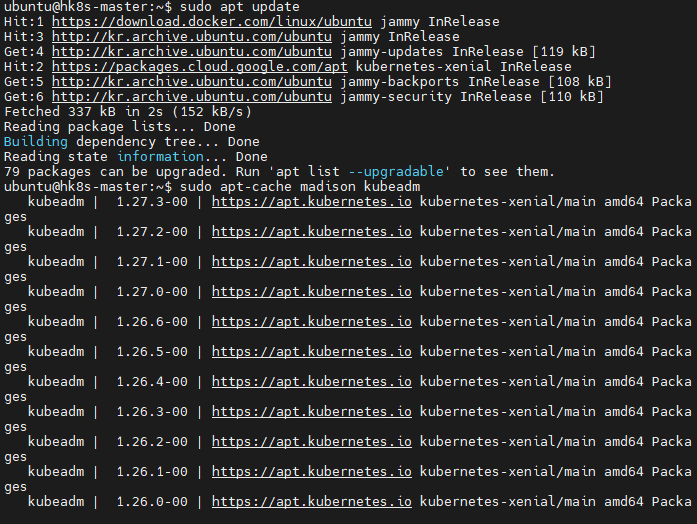
업그레이드 가능한 버전들을 볼 수 있다.
sudo apt-mark unhold kubeadm && \
sudo apt-get update && sudo apt-get install -y kubeadm=1.27.0-00 && \
sudo apt-mark hold kubeadm컨트롤 플레인 노드의 버전을 올려준다.

sudo kubeadm version
sudo kubeadm upgrade plan이 명령은 클러스터를 업그레이드할 수 있는지를 확인하고, 업그레이드할 수 있는 버전을 가져온다. 또한 컴포넌트 구성 버전 상태가 있는 표를 보여준다.
sudo kubeadm upgrade apply v1.27.0이 업그레이드를 위해 선택한 패치 버전으로 x를 바꾼다.
우리는 컨트롤 플레인이 1개 였지만 2개 혹은 3개라면 3개 모두 업그레이드 해주어야 한다.
지금은 안 해주어도 된다.
sudo kubeadm upgrade node
sudo kubeadm upgrade apply
특정 노드에 있는 포드들을 모두 다른 곳으로 옮기거나 특정 노드에는 포드들이 스케쥴링 되지 않도록 제한을 걸어둘 필요가 있다.
마스터 노드에는 중요한 컨테이너가 있기 때문에 마스터 노드에 있는 파드들을 모두 지워주는 명령어를 drain으로 사용하기
https://arisu1000.tistory.com/27845
kubectl drain hk8s-master --ignore-daemonsets
이제 kubelet과 kubectl을 업그레이드 해준다.
sudo apt-mark unhold kubelet kubectl && \
sudo apt-get update && sudo apt-get install -y kubelet=1.27.0-00 kubectl=1.27.0-00 && \
sudo apt-mark hold kubelet kubectl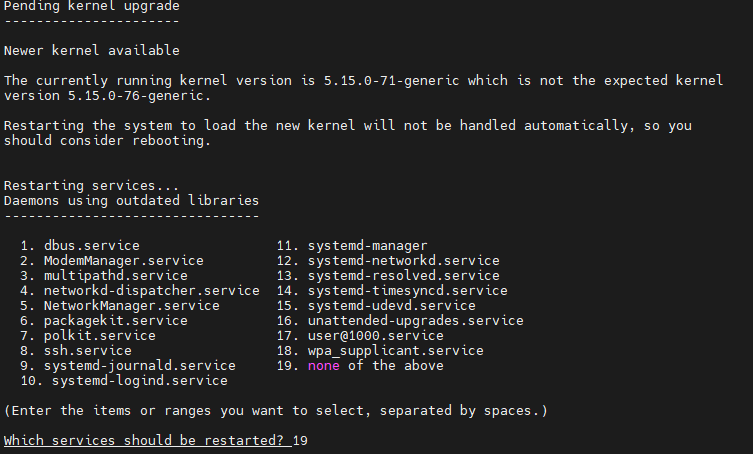
업그레이드를 진행하는 과정에서 위와같이 데몬 리로드에 대한 요청이 날라오는데 나는 그냥 none으로 해 놓고 이후에 내가 직접 reload해주었다.
sudo systemctl daemon-reload
sudo systemctl restart kubelet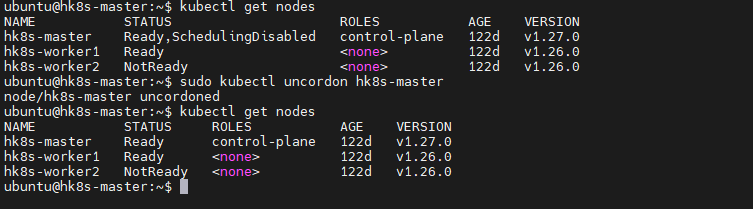

이제 노드 업그레이드를 해주자
이거 역시 메뉴얼에 그대로 나와있다.
ssh hk8s-worker1
sudo apt-mark unhold kubeadm && \
sudo apt-get update && sudo apt-get install -y kubeadm=1.27.0-00 && \
sudo apt-mark hold kubeadm
exit
# master에서만 실행 가능한 명령어이다.
kubectl drain hk8s-worker1 --ignore-daemonsets
ssh hk8s-worker1
sudo apt-mark unhold kubelet kubectl && \
sudo apt-get update && sudo apt-get install -y kubelet=1.27.0-00 kubectl=1.27.0-00 && \
sudo apt-mark hold kubelet kubectl
sudo systemctl daemon-reload
sudo systemctl restart kubelet
kubectl uncordon hk8s-worker1

실재 문제는 위와같이 나오기 때문에 이에 적절히 응하여 업그레이드 진행해주면 된다.