AWS Certified Soultions Architect Associate Day 09(RDS+Aurora+ElastiCache)
88. Amazon RDS 개요


이제 AWS RDS를 개략적으로 살펴보도록 하죠.
RDS는 관계형 데이터베이스 서비스를 나타내며 이는 SQL을 쿼리 언어로 사용하는 데이터베이스를 위한 관리형 데이터베이스를 뜻합니다. SQL은 데이터베이스 쿼리를 위한 구조적 언어입니다. 적용이 용이하며 많은 엔진에서 사용되고 있죠.
이 언어를 이용해서 클라우드에 데이터베이스를 생성할 수 있고 이와 같은 데이터베이스는 AWS 상에서 관리되므로 그 이점이 아주 큽니다.
AWS에서 관리하는 데이터베이스 엔진에는 어떤 유형이 있을까요?
먼저 PostgreSQL를 들 수 있습니다. 그리고 MySQL, MariaDB Oracle, Microsoft SQL Server Aurora까지 추후 Aurora에 대한 코스 섹션이 따로 있으니 지금은 그냥 넘어가겠습니다
처음 나오는 Postgres, MySQL, MariaDB, Oracle, Microsoft SQL Server는 기억해 둘 필요가 있습니다

EC2 인스턴스 상에 자체 데이터베이스 서비스를 배포하지 않고 RDS를 사용하는 이유는 무엇일까요?
가능하기 때문이죠
RDS는 관리형 서비스로 AWS가 데이터베이스뿐만 아니라 여러 기타 서비스 또한 제공하고 있습니다. 가령 해당 데이터베이스의 프로비저닝은 완전히 자동화되어 있고 기본 운영 체제 패치 또한 자동으로 이루어집니다
또한 지속적인 백업이 수행되며 특정 타임스탬프도 복구할 수 있습니다. 이를 지정 시간 복구 PITR이라고 합니다. 모니터링 대시보드를 통해서 데이터베이스 성능을 확인할 수 있고
본 강의 과정에서는 읽기 성능 향상을 목적으로 하는 읽기 전용 복제본에 대한 강의도 따로 마련되어 있습니다
다중 AZ를 설정할 수 있고 재해 복구 시 유용하게 이용하는 다중 AZ에 대한 강의 섹션 또한 찾아보실 수 있습니다
업그레이드를 위한 유지 보수도 존재하고
인스턴스 유형을 늘려서 읽기 전용 복제본을 추가함으로써 인스턴스 유형의 수직 및 수평 확장성을 증가시킬 수도 있습니다.
끝으로 스토리지가 EBS를 기반으로 하는데 gp2 볼륨 또는 io1을 뜻한다는 것은 전에 다룬 바 있어서 다들 알고 계시겠죠.
단 RDS 인스턴스에는 SSH를 따로 가질 수 없습니다. 이는 관리형 서비스로 AWS에서 제공되므로 기본 EC2 인스턴스에 대해서는 사용자가 따로 접근 권한을 갖지 않기 때문이죠. 하지만 EC2에 자체 데이터베이스 엔진을 배포하려면 어차피 모든 사항을 따로 설정해야 하기 때문에 큰 애로사항은 아닙니다.

----[없던 페이지]----
RDS 백업에 대해 잠깐 살펴보고 넘어가죠.
백업은 RDS에서 자동으로 활성화되며 자동으로 생성됩니다. 정의해 놓은 유지 관리 기간 동안 매일 수행되는 데이터베이스 전체에 대한 백업과 트랜잭션 로그, 즉 일일 트랜잭션 로그가 매 오 분마다 RDS에 백업되죠. 이 두 가지를 함께 이용해서 그 어떤 지정 시점으로든 데이터베이스를 복원할 수 있는 겁니다. 가장 오래된 백업에서부터 단 오 분 전 백업으로까지 자유롭게 돌아갈 수 있죠. 자동 백업은 기본적으로는 7일간 보관되지만 최대 35일까지로 보관 기간을 설정할 수 있습니다
또한 데이터베이스 스냅샷이 있는데 스냅샷은 백업과 약간 다릅니다. 스냅샷은 사용자가 수동으로 발동시키는 백업으로 백업 보관 기간을 사용자 임의로 설정할 수 있습니다. 따라서 예를 들어 6개월간의 지정 시점 동안의 데이터베이스 보관도 가능한 겁니다.
----[없던 페이지]----
다음은 시험에 출제될 수 있는 RDS 스토리지 오토 스케일링 기능 중 하나를 살펴보겠습니다.
RDS 데이터베이스를 생성할 때는 원하는 스토리지 용량을 지정해야 합니다. 스토리지를 20GB로 지정하는 것과 같이 말이죠. 단 데이터베이스 사용이 많고 사용 가능한 공간이 부족해지는 경우 바로 이 기능 RDS 스토리지 오토 스케일링이 활성화되어 있으면 RDS가 자동으로 스토리지에 대한 스케일링을 수행하죠. 따라서 스토리지 확장을 위해 데이터베이스를 중단하는 등의 작업을 따로 수행할 필요가 없습니다.
즉 애플리케이션이 RDS 데이터에 다량의 읽기 및 쓰기 작업을 수행할 때에 자동으로 특정한 임계값을 확인해서 스토리지에 대한 오토 스케일링 작업이 수행되는 RDS 기능입니다. 아주 훌륭한 기능이죠
데이터베이스 스토리지를 수동으로 확장하는 작업을 피하는 것이 골자입니다. 이를 위해서는 최대 스토리지 임계값을 설정해야 합니다. 무한대 확장이 불가능하기 때문에 스토리지 확장에 대한 최댓값이 필요하겠죠
가량 사용 가능한 스토리지가 할당된 스토리지의 10% 미만으로 떨어지거나 이처럼 낮은 스토리지 상태가 오 분 이상 지속되며 지난 수정이 여섯 시간 이상 지났을 경우에는 자동으로 스토리지를 수정합니다. 이와 같은 경우에 활성화가 된 상태라면 스토리지가 자동으로 증가하는 겁니다.
이는 워크로드를 예측할 수 없는 애플리케이션에 아주 유용합니다.
또한 MariaDB, MySQL PostgreSQL, SQL Server, Oracle 등 모든 RDS 데이터베이스 엔진을 지원하죠.
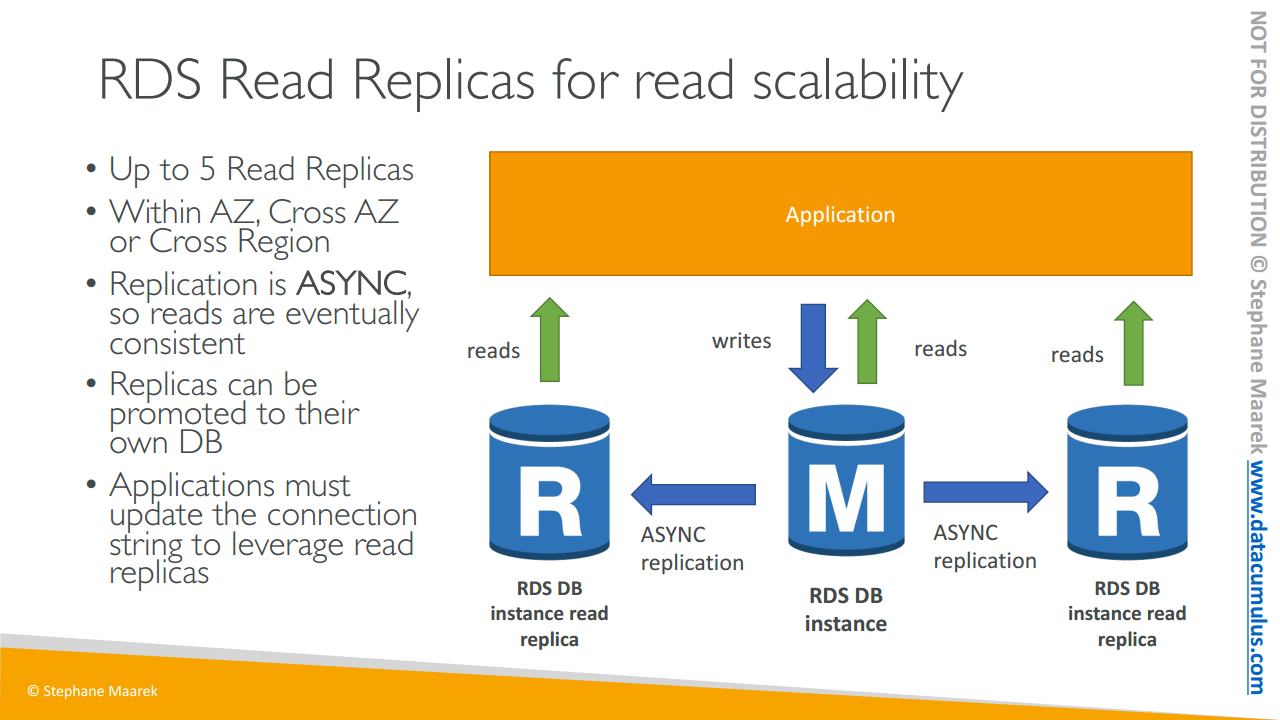
89. RDS 읽기 전용 복제본과 다중 AZ

시험에 응시하기 전 RDS 읽기 전용 복제본과 다중 AZ의 차이를 이해하고 각각의 사용 사례를 제대로 아는 것이 중요합니다. 본 강의에서는 읽기 전용 복제본과 다중 AZ에 집중합니다
그럼 읽기 전용 복제본부터 시작해 보죠. 읽기 전용 복제본은 이름에서 알 수 있듯 읽기를 스케일링합니다.
예시와 함께 보겠습니다. 슬라이드를 보면 애플리케이션과 RDS 데이터베이스 인스턴스가 있습니다. 애플리케이션은 데이터베이스 인스턴스에 대해 읽기와 쓰기를 수행하죠. 하지만 주된 데이터베이스 인스턴스가 너무 많은 요청을 받아서 충분히 스케일링할 수가 없기에 읽기를 스케일링하고자 한다고 해 봅시다.
이때 읽기 전용 복제본을 최대 다섯 개까지 생성할 수 있으며 이들은 동일한 가용 영역 또는 가용 영역이나 리전을 걸쳐서 생성될 수 있습니다. 세 가지 다른 옵션이 있는데 이들을 잘 기억해 둬야 합니다. 두 개의 RDS 인스턴스 읽기 전용 복제본이 있다고 해 봅시다.
이때 주된 RDS 데이터베이스 인스턴스와 두 읽기 전용 복제본 사이에 비동기식 복제가 발생합니다. 비동기식이란 결국 읽기가 일관적으로 유지된다는 것을 뜻합니다. 가령 애플리케이션에서 데이터를 복제하기 전 읽기 전용 복제본을 읽어들이면 모든 데이터를 얻을 수 있다는 것이죠. 이것이 바로 일관적인 비동기식 복제의 의미입니다.
이와 같은 복제본이 읽기 스케일링에 적합할 수 있으나 이를 데이터베이스로도 승격시켜 이용할 수 있습니다. 즉 이들 복제본 중 하나를 데이터베이스로 사용하고자 하며 그에 대한 권한을 획득하면 이를 데이터베이스로 승격시킬 수 있습니다. 그 후에 이 복제본은 복제 메커니즘을 완전히 탈피하죠. 하지만 자체적인 생애 주기를 갖습니다
읽기 전용 복제본을 사용하려는 경우에는 화면 상단의 주요 애플리케이션에 있는 모든 연결을 업데이트해야 하며 이를 통해서 RDS 클러스터 상의 읽기 전용 복제본 전체 목록을 활용할 수 있습니다.
이제 읽기 전용 복제본의 흔한 사용 사례를 하나 알아보죠.
예를 들어서 평균적인 로드를 감당하고 있는 생산 데이터베이스가 있다고 해 봅시다생산 데이터베이스에서는 메인 RDS 데이터베이스 인스턴스에 대한 읽기 및 쓰기가 수행됩니다. 이때 새로운 팀이 와서 여러분의 데이터를 기반으로 몇 가지 보고와 분석을 실시하고자 한다고 해 보죠. 보고 애플리케이션을 메인 RDS 데이터베이스 인스턴스에 연결하면 오버로드가 발생하고 생산 애플리케이션의 속도가 느려질 텐데 이런 현상은 피하고자 합니다. 이때 여러분이 해결사로 나서서 새로운 워크로드에 대한 읽기 전용 복제본을 생성하는 겁니다. 읽기 전용 복제본을 생성하면 메인 RDS DB 데이터베이스 인스턴스와 읽기 전용 복제본 간 비동기식 복제가 발생합니다. 그다음 보고 애플리케이션이 생성한 읽기 전용 복제본에서 읽기 작업과 분석을 실행하게 되는 거죠. 이 경우 생산 애플리케이션은 전혀 영향을 받지 않으니 완벽합니다.
읽기 전용 복제본이 있는 경우에는SELECT 명령문에만 사용하는 점을 명심해야 합니다. SELECT는 SQL의 키워드로 읽기를 의미하죠. 따라서 데이터베이스 자체를 바꾸는 INSERT, UPDATE, DELETE 같은 키워드는 사용이 불가능합니다. 읽기 전용 복제본은 읽기를 위함일 뿐이니 말이죠.

RDS 읽기 전용 복제본과 관련된 네트워킹 비용을 한번 살펴보겠습니다. AWS에서는 하나의 가용 영역에서 다른 가용 영역으로 데이터가 이동할 때에 비용이 발생합니다. 하지만 예외가 존재하며 이 예외는 보통 관리형 서비스에서 나타납니다. RDS 읽기 전용 복제본은 관리형 서비스입니다. 읽기 전용 복제본이 다른 AZ 상이지만 동일한 리전 내에 있을 때는 비용이 발생하지 않습니다. 즉 us-east-1a에 RDS DB 인스턴스가 있고 그에 대한 읽기 전용 복제본은 us-east-1b에 있다고 치면 이는 비동기식 복제로 읽기 전용 복제본의 복제 트래픽이 하나의 AZ에서 다른 AZ로 넘어가더라도 RDS가 관리형 서비스이기 때문에 해당 트래픽은 비용 없이 무료로 이동할 수 있습니다.
하지만 서로 다른 리전에 복제본이 존재하는 경우 즉 us-east-1에 대해서 복제본이 eu-west-1에 존재하는 경우에는 RDS DB 인스턴스와 읽기 전용 복제본이 여러 리전을 넘나들어야 하기 때문에 네트워크에 대한 복제 비용이 발생합니다
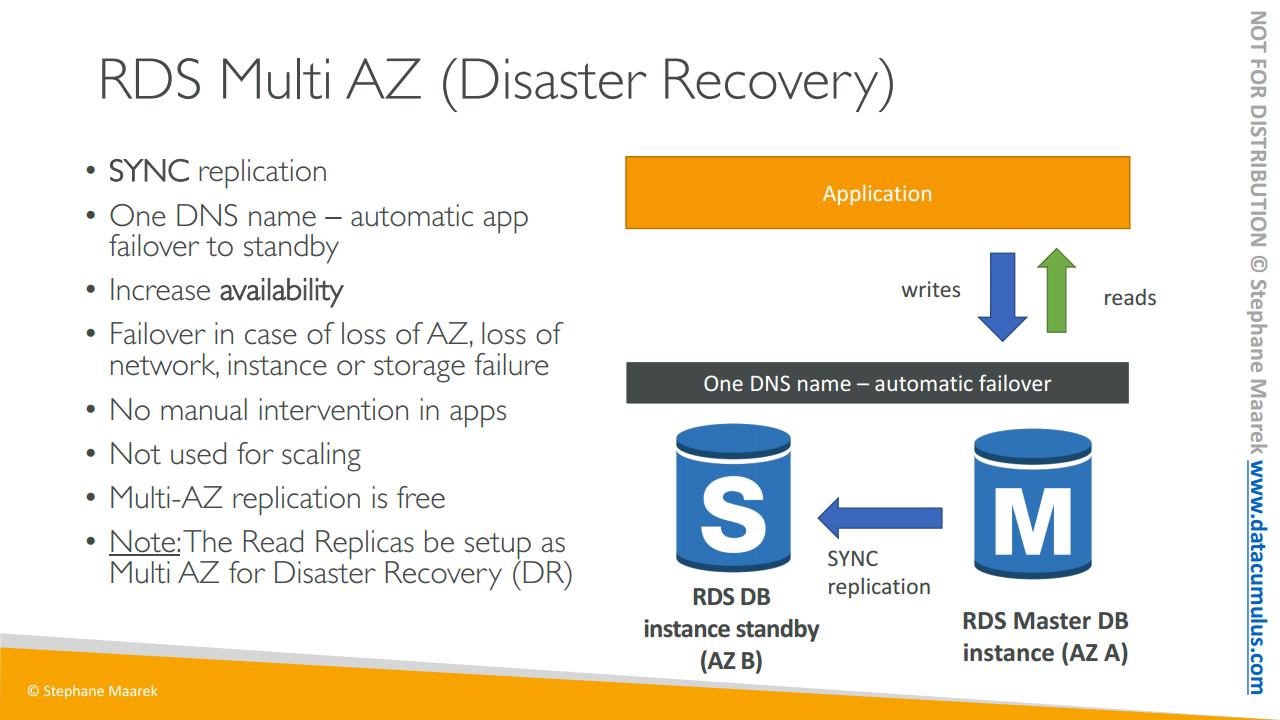
끝으로 RDS 다중 AZ에 대해 알아보죠
다중 AZ는 주로 재해 복구에 사용됩니다. 슬라이드 상의 이 애플리케이션은 가용 영역 AZ A에서 읽기와 쓰기를 수행하는 마스터 데이터베이스 인스턴스입니다. 그리고 동기식으로 이를 AZ B에 스탠바이 인스턴스로 복제합니다. 마스터 데이터베이스의 모든 변화를 동기적으로 복제하는 것인데 이는 애플리케이션의 마스터에 쓰이는 변경 사항이 대기 인스턴스에도 그대로 복제된다는 것을 의미합니다.
즉 하나의 DNS 이름을 갖고 애플리케이션 또한 하나의 DNS 이름으로 통신하며 마스터에 문제가 생길 때에도 스탠바이 데이터베이스에 자동으로 장애 조치가 수행됩니다. 하나의 DNS 이름을 갖기 때문이죠.
이를 통해서 가용성을 높일 수 있기 때문에 다중 AZ라고 불립니다.
전체 AZ 또는 네트워크가 손실될 때에 대비한 장애 조치이자 마스터 데이터베이스의 인스턴스 또는 스토리지에 장애가 발생할 때 스탠바이 데이터베이스가 새로운 마스터가 될 수 있도록 하는 겁니다.
따로 앱에 수동으로 조치를 취할 필요가 없습니다. 자동으로 데이터베이스에 연결이 시도되고 장애 조치가 필요하게 될 때에도 스탠바이가 마스터로 승격되는 과정이 자동으로 이루어질 테니까 말입니다.
스케일링에 이용되지도 않죠. 여기 보이는 대로 스탠바이 데이터베이스는 단지 대기 목적 하나만 수행합니다. 그 누구도 이를 읽거나 쓸 수 없죠. 마스터 데이터베이스에 문제가 발생할 경우를 대비한 장애 조치일 뿐입니다.
간단한 질문을 하나 해 보죠. 재해 복구를 대비해서 읽기 전용 복제본을 다중 AZ로 설정할 수 있을까요? 네 가능합니다 원하는 경우에는 읽기 전용 복제본을 다중 AZ로도 설정할 수 있습니다. 흔히 나오는 시험 문제였습니다
지금까지 읽기 전용 복제본과 다중 AZ의 차이를 알아보았습니다. 시험에 응시하기 전에 둘의 차이를 제대로 이해하셔야 합니다. 많은 시험 문제가 이를 기반으로 하기 때문이죠

시험에서는 단일 AZ에서 다중 AZ로 RDS 데이터베이스 전환이 가능할지 물을 수 있습니다.
이 작업에는 다운타임이 전혀 없는 점을 염두에 둬야 합니다. 즉 단일 AZ에서 다중 AZ로 전환할 때에 데이터베이스를 중지할 필요가 없는 겁니다.
데이터베이스 수정을 클릭하고 다중 AZ 기능을 활성화시키기만 하면 됩니다. 이를 통해서 RDS 데이터베이스 인스턴스는 마스터를 갖고 동기식 복제본인 스탠바이 데이터베이스를 확보하죠. 이때 여러분은 설정을 수정하는 것 외에는 아무 작업도 할 필요가 없습니다. 데이터베이스가 중지될 일이 없죠
시험에서 묻는 내용입니다. 보이지 않는 곳에서는 어떤 작업이 이루어지는지 한번 보여드리겠습니다.
- 다음이 내부적으로 발생하는 일입니다. 기본 데이터베이스의 RDS가 자동으로 스냅샷을 생성합니다.
- 이 스냅샷은 새로운 스탠바이 데이터베이스에 복원되죠.
- 스탠바이 데이터베이스가 복원되면두 데이터베이스 간 동기화가 설정되므로 스탠바이 데이터베이스가 메인 RDS 데이터베이스 내용을 모두 수용하여 다중 AZ 설정 상태가 됩니다
90. Amazon RDS 실습
지금부터 RDS를 사용하여 데이터베이스를 생성해 보겠습니다
RDS를 사용하면
AWS 클라우드에 관리자 데이터베이스를 얻을 수 있습니다
이는 아주 유용한데
기본 서버를 관리할 필요가 없고
백업의 복제본이나 다중 AZ와 같은
기능을 즉시 사용할 수 있습니다
그럼 데이터베이스를 생성해 보죠
여기 보이는 것과 같이 데이터베이스 생성에는 두 옵션이 있습니다
모든 옵션을 이용하는 Standard create와
과정이 신속한 Easy create가 있죠
AWS를 다루고 있으니 Standard 옵션을 선택해 보도록 하겠습니다
엔진 유형은 다음과 같습니다
Aurora, MySQL, MariaDB, PostgreSQL, Oracle, Microsoft SQL Server로
Aurora는 나중에 살펴보도록 하죠
나머지 다섯 개 엔진은 기억해 둘 필요가 있습니다
MySQL, MariaDB, PostgreSQL Oracle, Microsoft SQL Server 중
이번 데모에서는 MySQL을 사용하겠습니다
버전은 설정된 그대로 두겠습니다
MySQL에는 여러 옵션이 있는데
사용 사례에 맞게 지정할 수 있는 템플릿이 존재하며
특정 구성에 대한 구성 매개변수가 다음처럼 지정되어 있기도 합니다
Production, Dev/Test Free tier가 나와 있군요
모든 옵션을 살펴볼 테니 지금은 먼저 Production부터 선택하고
차근차근 하나씩 보도록 하죠
하지만 반드시 AWS RDS의
프리 티어를 사용할 수 있는 인스턴스를 선택해야 합니다
Production을 고른 다음 데이터베이스 식별자를 설정해야 합니다
database-1으로 하죠
그다음으로는 마스터 사용자 이름을 설정할 차례입니다
admin이 좋겠군요
마스터 비밀번호로는
간단히 password로 설정해 보죠
이제 다 끝났습니다
스크롤을 내려 데이터베이스 클래스로 가면
원하는 인스턴스 유형을 선택할 수 있습니다
Standard, Optimized Burstable 클래스가 있습니다
그다음 원하는 vCPU와 RAM 그리고
네트워크 속도를 제공하는 인스턴스 유형을 선택하면 됩니다
단 프리 티어를 사용할 수 있어야 하기 때문에
Burstable 클래스로 고르고 dbt2.micro를 선택해 줍니다
이전 세대를 포함하도록 설정하고 dbt2.micro를 선택합니다
프리 티어를 사용할 수 있도록 설정하기 위함입니다
다음으로 스토리지는 GP2로 고릅니다 다른 옵션 또한 보이는군요
I1이나 Magnetic도 있습니다
하지만 프리 티어 내에 있으려면
범용 SSD 유형인 GP2를 고를 필요가 있습니다
GP2는 20GB의 스토리지를 제공해 주니 양호한 선택이죠
다음은 멋진 기능인 스토리지 오토 스케일링을 볼 텐데
이 기능을 활성화하면 데이터베이스 스토리지에 동적 스케일링이 지원됩니다
즉, 스토리지 사용량이 증가하여 20GB에 가까워지면
AWS 상에서 다른 작업 없이 자동으로 검색량이 증가하는 겁니다
이 또한 스케일 업인 경우에 감소 작업이 뒤따르는 스케일링이죠
최대 스토리지 임계값도 설정할 수 있습니다
1,000GB에서 1TB까지 설정할 수 있죠
크기를 따로 모니터링할 필요가 없기 때문에 아주 유용합니다
워크로드가 증가하면 자동으로 스케일링이 수행된다는 것만 알면 되죠
다음으로는 아주 중요한 가용성과 내구성을 볼 텐데
Production 템플릿을 선택하며 기본적으로 설정되었죠
지금은 다중 AZ를 비활성화 상태로 돌릴 수도 있습니다
다중 AZ를 활성화하면
RDS 데이터베이스에 대한 스탠바이 인스턴스를 갖게 되고
이는 생산에 있어서는 권고되는 사항입니다
데이터 중복에 대하여 이 스탠바이 인스턴스가 제공될 것이며
I/O 동결 시 백업으로 이용되거나
백업 도중 지연 시간의 급증을 최소화할 수 있습니다
해당 스탠바이 인스턴스는 애플리케이션에서 사용되는 것이 아니라
메인 인스턴스에 문제가 생기거나
리부팅이 필요할 때를 대비해서 존재합니다
지금은 다중 AZ를 사용하지 않는다고 설정한 뒤 넘어가죠
다음으로 네트워크 세팅은 RVPC로 하겠습니다
나와 있는 이 서브넷 그룹에서 실행하는 겁니다
그리고 퍼블릭 액세스는
Yes를 선택합니다 이 설정으로 데이터베이스를
공개적으로 테스트해 볼 수 있습니다
VPC 보안 그룹에서는 Create new를 선택해 줍니다
demo-database-mysql로 이름을 지정해 보죠
AZ에 대한 선호 위치는 없으니 No preference로 두고
포트도 표준 포트인 3306 그대로 둡니다
데이터베이스 인증에는 세 가지 옵션이 나와 있는데
비밀번호 인증과
비밀번호 및 IAM 데이터베이스 인증
비밀번호 및 Kerberos 인증이 있습니다
두 번째 옵션인 IAM 자격 증명으로 RDS에 로그인하는 내용이 중요하지만
지금은 간단한 옵션인
비밀번호 인증으로 골라 보겠습니다
그리고 다수의 추가 구성을 설정할 수 있는데
초기 데이터베이스의 이름도 지정이 가능합니다
mydb로 설정해 주도록 하죠
매개변수 그룹도 있지만 본 코스의 범위를 넘어가니 다음으로 가서
백업을 보겠습니다 자동 백업을 활성화하고
백업 보관 기간으로는
7일을 설정합니다 0에서 35일까지로 설정이 가능합니다
백업에 대한 백업 기간을 따로 설정할 수 있습니다
하지만 지금은 없는 것으로 두죠
더 많은 지표를 위해 Enhanced monitoring을 설정하고
CloudWatch 로그로 로그를 내보낼 수 있으며
Audit, Error, General Slow query 옵션이 있죠
유지 보수에서는 오토 마이너 버전 업그레이드를 활성화하도록 하고
이에 대한 유지 보수 기간을 설정할 수도 있습니다
데이터베이스를 실수로 삭제할 때를
대비해서 삭제 보호 기능은 활성화하도록 하겠습니다
이는 매달 예상 비용으로
t2.micro 유형의 인스턴스를 선택하면
프리 티어 내에 속합니다
본 UI의 일부로 월별 비용이
이처럼 표시되는 것을 본 겁니다
다 마쳤다면 데이터베이스를 생성해 보겠습니다
데이터베이스가 생성되는 동안 Sqlectron을 다운로드해 보죠
데이터베이스에 연결할 SQL 클라이언트입니다
간단히 Download GUI를 클릭해 준 다음
여러분이 사용하는 플랫폼에 대한 최신 버전을 받습니다
윈도우 파일도 있고 맥에서 사용하는 dmg 파일도 있군요
저는 맥을 사용하니 dmg 파일을 열어서 설치해 보겠습니다
데이터베이스 생성이 모두 끝났군요
시간이 소요되긴 했으나 이제 사용이 가능한 상태가 됐습니다
몇 가지 옵션을 함께 살펴보도록 하죠
좌측부터 보면 엔드포인트와 3306 포트가 나와 있고
보안 그룹에 연결된 상태입니다
보안 그룹을 클릭한 다음 ID를 누르면 인바운드 규칙이 나오는데
인바운드 규칙에서
TCP와 포트가 3306임을 확인할 수 있습니다
제 IP 주소에서 온 값이죠
여러분의 데이터베이스 인스턴스와 이 보안 그룹이
연결되지 않을 대는 수정이 필요합니다
IPV4로 변경하는 등 말이죠
이제 Sqlectron을 이용해서 이 엔드포인트를 연결해 보겠습니다
Sqlectron를 이용해서 새로운 데이터베이스를 추가해 보죠
RDSdemo로 이름을 지정하고
MySQL 데이터베이스 유형을 입력해 줍니다
서버 주소는
3306 포트로 지정하고
사용자는 admin 비밀번호는 password
그리고 초기 데이터베이스는 앞서 입력한 mydb라고 넣어 줍니다
Test를 눌러 보면 연결이 성공적이었다고 나옵니다
그렇지 못할 경우
먼저 데이터베이스가 공용 데이터베이스로 설정되었는지를 확인하고
다음으로는 보안 그룹에서 해당 IP가
허용된 상태인지 확인하시기 바랍니다
그대로 저장한 다음 데이터베이스에 연결해 보도록 하겠습니다
이제 앞서 생성했던 데이터베이스 mydb에 데이터베이스를
직접 연결해 보겠습니다
표를 생성하기 위한 명령문을 입력해 볼 텐데
CREATE TABLE MY TABLE 다음에
이름으로는 (name VARCHA(20))
first_name VARCHA(20)를 입력해 줍니다
SQL의 원리를 살펴보기 위한 간단한 명령문이었지만
시험 범위에는 속하지 않습니다
실행하고 보면 mytable이 생성되어 있습니다
안에 든 내용은 없죠
Insert Statement로 표에 데이터를 입력할 수 있습니다
VALUES에는 maarek과
Stephane을 입력하고 실행해 보죠
이제 Select Rows를 클릭해서 보면 표에
name과 first_name에 maarek과 Stephane이 표시됩니다
MySQL을 사용해서 RDS 데이터베이스를 이용한 모습입니다
시험 범위에 속하지는 않으나
Sqlectron을 사용했을 때의 전체적인 그림을 보여 드리고자 했습니다
다시 RDS로 돌아오면 RDS 데이터베이스는 완벽히 관리 중에 있습니다
좋습니다 이제 사용할 수 있겠네요
데이터베이스에서 직접
읽기 전용 복제본을 생성해 보는 것도 좋습니다
Create read replica를 눌러서
읽기 전용 복제본을 생성하면
데이터베이스에 대한 읽기 용량이 더 늘어나므로
아주 유용한 기능입니다
복구 목적으로
데이터베이스에 대한 다중 AZ를 생성할지에 대한 질문에는 NO를 고르고
Cancel을 눌러서 나가 보죠
다음으로는 Monitoring으로 가 보겠습니다
여기서는 CPU 사용률과 같은 수치를 볼 수 있습니다
데이터베이스에 대한 CPU 사용률이 모니터링되면서
연결이 너무 많은 경우에는
스케일링이 수행될 수도 있고
DB Connections를 통해
데이터베이스에 연결된 클라이언트의 수와
전체 지표 수를 확인할 수도 있습니다
RDS를 사용해서 스냅샷을 생성할 수도 있습니다
스냅샷을 생성하면 데이터베이스가 스냅샷으로 저장되어서
원할 때에 이를 복구할 수 있습니다
지정한 시점으로 데이터베이스를 복원하거나
스냅샷을 다른 리전으로
옮기는 등의 작업도 가능합니다
이와 같은 여러 옵션을 직접 이용해 볼 수 있죠
하지만 RDS의 목적이라 함은 데이터베이스를 관리하고
읽기 전용 복제본이나 다중 AZ를 생성하는 데에 있습니다
앞으로 인스턴스의 유형은 증가시킬 수 있으며
관리형 서비스에 있어서 아주 유용한 기능이 될 겁니다
지금까지 RDS 데이터베이스에서 필요한 모든 내용을 살펴봤습니다
유익한 시간이었길 바라며
데이터베이스는 필히 삭제하시기 바랍니다
삭제를 위해서는 먼저 삭제 보호를 제거해야 합니다
Modify로 가서 스크롤을 내리면 가장 마지막에
Deletion Protection 설정을 찾을 수 있습니다
활성화를 해제하고 Continue를 누릅니다
바로 적용되는 모습을 볼 수 있죠
삭제 보호가 비활성화된 뒤에는
이 데이터베이스를 삭제할 수 있습니다
Create final snapshot 옵션은 해제한 다음
delete me를 입력합니다 모든 사항이
삭제된다는 점을 확인 및 체크해 주고
Delete를 클릭하면 모든 작업이 끝납니다
오늘은 여기까지로 유익한 시간이었길 바라며
다음 시간에 뵙도록 하겠습니다
91. RDS 암호화 + 보안[없는 페이지]
RDS 보안에 관해 살펴보겠습니다
첫 번째로 살펴볼 주제는 암호화입니다.
먼저, 사용하지 않는 데이터인 미사용 데이터 암호화는
- AES 256비트 암호화를 사용하는 AWS의 키 매니지먼트 서비스인 AWS KMS로 마스터 데이터베이스와 읽기 전용 복제본을 암호화할 수 있습니다
- 따라서 암호화 실행 시 실행 시간을 정의해야 하며
- 마스터 데이터베이스를 암호화하지 않으면 복제본도 암호화할 수 없습니다. 시험에 자주 나오는 상황이죠
- Oracle과 SQL 서버에서 TDE라고 하는 투명한 데이터 암호화를 활성화할 수 있고 이는 데이터베이스 암호화의 대안을 제공합니다.
또, 늘 SSL 인증서가 필요한 전송 중 암호화도 있고
- 이는 데이터 전송 중에 RDS로 암호화를 사용하는데 클라이언트에서 데이터베이스로 전송 중인 것을 말합니다
- 데이터베이스에 연결 시 신뢰할 수 있는 인증서로 SSL 옵션을 제공하면 SSL을 연결할 수 있습니다
- 모든 클라이언트가 SSL을 사용하도록 하려면 PostgreSQL에서는 rds.force_ssl=I인 콘솔 매개변수 그룹을 설정해야 하며
꽤 명시적입니다
- MySQL 사용 시 GRANT USAGE ON *.* TO 'mysqluser'@%'REQUIRE SSL이라는 명령문을 데이터베이스 내부에서 실행해야 합니다. 이 또한 꽤 명시적이죠. PostgreSQL은 매개변수 그룹이고 MySQL은 데이터베이스 내에서 SQL 명령문이 됩니다.
여기서 꼭 알아야 할 몇 가지의 RDS 작업이 있습니다
첫 번째는 RDS 백업을 암호화하는 방법입니다
- 여기서 알아야 할 것은 암호화 되지 않은 RDS 데이터베이스에서 스냅샷을 생성하면 스냅샷 자체는 암호화되지 않는 것입니다.
- 마찬가지로 암호화된 RDS 데이터베이스에서 스냅샷을 생성하면 모든 스냅샷이 기본으로 암호화되는데 이는 항상 기본 값은 아닙니다.
- 그래서 암호화되지 않은 스냅샷을 암호화된 스냅샷으로 복제해야 합니다. 암호화되지 않은 RDS 데이터베이스의 스냅샷을 생성해 복제한 뒤 이 스냅샷의 암호화된 버전을 쉽게 만들 수 있는 것이죠.
다음은 암호화되지 않은 RDS 데이터베이스의 암호화 방법입니다
- 지금까지 배운 것으로 암호화 되지 않은 RDS 데이터베이스의 스냅샷을 생성해야 하고 이는 암호화되지 않습니다
- 그리고 스냅샷을 복제하고 복제한 스냅샷의 암호화를 활성화합니다. 이제 복제된 암호화 스냅샷이 생겼습니다
- 이 암호화된 스냅샷으로 암호화된 스냅샷에서 데이터베이스를 복원할 수 있으며 이는 암호화된 RDS 데이터베이스를 제공합니다.
- 이제 모든 애플리케이션을 이전의 암호화되지 않은 RDS 데이터베이스에서 새 암호화된 RDS 데이터베이스로 옮기고 이전 데이터 베이스를 삭제합니다. 이 작업은 꼭 알아야 합니다. 한 번 살펴보시고 시험에 나오면 알고 있어야 합니다.'
이제 네트워크와 IAM 보안을 살펴보겠습니다
- 네트워크 보안의 RDS 데이터베이스는 대게 퍼블릭 서브넷이 아닌 프라이빗 서브넷에서 배포됩니다. 따라서 데이터베이스가 WWW에 노출되지 않도록 해야 합니다
- 그리고 RDS 보안은 RDS 인스턴스에 연결되어 있는 보안 그룹을 활용해 실행됩니다. EC2 인스턴스와 동일한 개념이죠. RDS와 통신할 수 있는 IP 또는 보안 그룹을 제어합니다
그리고 사용자 관리 등과 권한인 액세스 관리에는
- IAM 정책이 있습니다. 이 정책은 AWS RDS를 관리하는 사람만 제어할 수 있습니다. 데이터를 생성하고 삭제할 수 있으며 읽기 전용 복제본 생성 등을 할 수 있는 것이죠
- 기존의 방식으로 데이터베이스를 연결하려면 데이터 베이스에 로그인하기 위해 기존 사용자 이름과 암호를 사용하거나
- 다음 슬라이드에서 살펴볼 RDS MySQL과 PostgreSQL과 같은 IAM 기반의 인증을 사용할 수 있습니다.
결국 데이터베이스 보안은 주로 데이터베이스 안에서 이루어지는 것이죠
이제 IAM 인증을 사용한 RDS 연결법을 살펴보겠습니다
- 말씀드린 대로 MySQL과 PostgreSQL에서만 실행되며
- 암호는 필요하지 않고 인증 토큰이라는 것이 필요한데 RDS API 호출을 사용해서 IAM으로 직접 얻을 수 있습니다. 잠시 후에 도표로 확인해 보겠습니다
- 인증 토큰은 수명이 짧은데 수명은 15분입니다
예시를 살펴보죠
여기 EC2 보안 그룹과 RDS 보안 그룹이 있고 RDS 보안 그룹에는 MySQL RDS 데이터베이스가 있습니다. EC2 인스턴스에는 IAM 역할이 생성되고 이는 EC2 IAM 역할을 다룰 때 그 의미를 자세히 살펴보겠습니다.
여기서의 개념은 EC2 인스턴스가 IAM 역할 덕분에 RDS 서비스에 API 호출을 실행해서 인증 토큰을 다시 받을 수 있다는 것입니다. 이 토큰을 사용하면 MySQL 데이터베이스에 연결하는 동안 토큰을 끝까지 전달하는데 연결이 암호화됐는지 확인해야 합니다. 그러면 MySQL 데이터베이스에 안전하게 연결됩니다.
이러한 접근법의 장점은
- 네트워크 안팎이 SSL로 암호화된다는 것입니다.
- IAM은 데이터베이스 내부에서의 사용자 관리 대신 중앙에서의 사용자 관리에 사용합니다. 조금 더 중앙 집중화된 인증 유형인 것입니다.
- IAM 역할과 EC2 인스턴스 프로파일로 쉽게 통합할 수 있습니다. IAM 역할과 EC2 인스턴스 프로파일은 곧 살펴보겠습니다. RDS 보안을 다시 정리해 보죠.
미사용 데이터 암호화는
- 데이터베이스 인스턴스를 처음 생성할 때만 실행되며
- 암호화되지 않았으면 스냅샷을 생성해야 합니다. 그리고 스냅샷을 복제해 암호화 한 다음에 암호화된 스냅샷에서 새 데이터베이스를 생성하면 데이터베이스를 암호화하죠
여러분은 모든 포트와 IP 보안 그룹, 인바운드 규칙
- 사용 가능한 데이터베이스의 보안 그룹을 확인하고
- 내부 데이터베이스의 모든 사용자 생성 및 권한을 관리하거나 MySQL과 PostgreSQL 용 IAM으로 관리해야 합니다
- 또, 퍼블릭 액세스가 있고 없는 데이터베이스를 생성해 프라이빗 서브넷이나 퍼블릭 서브넷으로 가게 합니다
- 그리고 파라미터 그룹과 데이터베이스가 SSL 연결만 허용하도록 구성되어 암호화되는지 확인해야 합니다
AWS에서는 무엇을 할까요?
- SSH 액세스가 발생하지 않도록 하고
- 데이터베이스 패치나 OS 패치를 할 필요가 없습니다
- 모두 AWS에서 해주죠. 기본 인스턴스도 확인하지 않아도 됩니다. 이것도 AWS의 의무입니다. 그래서 RDS 서비스를 사용하거나 안 할 수도 있지만 저는 AWS의 최고 서비스 중 하나라고 생각합니다. 그러니 RDS를 사용해야겠죠?
??????????? 이거 슬라이드 왜 남음?

92. Amazon Aurora

Amazon Aurora를 살펴보겠습니다
여기에 관련된 문제가 시험에 많이 출제되거든요. 깊게 알아야 할 필요는 없지만 정확한 작동 방식을 이해하려면 전반적인 내용을 알아야 합니다. 바로 그게 이번 강의의 목적이에요
- Aurora는 AWS의 독점 기술입니다. 오픈 소스는 아니지만
- MySQL 및 Postgres와 호환되죠. Aurora 데이터베이스에 호환 드라이버가 있어요. 그러므로 여러분이 Postgres나 MySQL의 데이터베이스에 연결하면 작동됩니다
- Aurora는 아주 특별해요 자세히 다루지는 않겠지만 클라우드에 최적화되었고 다양한 최적화와 스마트 작업을 통해서 RDS의 mySQL보다 성능이 5배나 향상되며 RDS의 Postgres보다는 3배 향상됩니다. 그 외에도 많은 부분에서 성능 향상을 이루고 있습니다. 정말 훌륭한 기능이지만 너무 깊게 들어가지는 않을게요
- Aurora 스토리지는 자동으로 커지며 이는 꽤 좋은 기능 중 하나입니다. 10 GB로 시작하여 데이터베이스에 더 많은 데이터를 넣을수록 최대 128 TB까지 자동으로 커지게 됩니다. 설계 방식에 따라 다르지만 여기서 대단한 점은 DB 또는 SysOps가 여러분이 디스크를 모니터링하지 않아도 시간에 따라 자동으로 커진다는 점입니다
- 또한 15개의 읽기 전용 복제본을 가지는데, MySQL은 5개예요. 그리고 복제 속도도 훨씬 더 빠릅니다. 전반적으로 Aurora가 좋습니다
- Aurora에서는 장애 조치가 즉각적으로 이루어집니다. mySQL나 RDS의 다중 AZ에 대한 장애 조치보다 훨씬 빨라요. 기본적으로 클라우드 네이티브라 고가용성을 얻을 수 있습니다
- 비용은 RDS보다 20% 정도 더 높지만 훨씬 더 효율적이어서 규모가 클 경우, 비용 절감이 가능하죠.

그러면 매우 중요한 부분인 고가용성 및 읽기 스케일링을 살펴봅시다
Aurora가 특별한 이유는 쓰기 요청을 할 때 마다 6개의 데이터 복제본을 3개의 AZ에 걸쳐 저장하기 때문이죠.
- Aurora가 6개의 복제본을 만들지만 쓰기에는 6개 중 4개의 복제본만 있으면 됩니다. 즉 하나의 AZ가 다운되더라도 괜찮은 거예요
- 그리고 읽기에는 6개 중 3개의 복제만 필요합니다. 다시 말해 쓰기에 대한 가용성이 높다는 뜻입니다.
- 그리고 자가 복구 과정이 있어서 어떤 데이터가 손상되거나 잘못되었을 경우에 백엔드에서 P2P 복제를 통해 자가 복구를 할 수 있어 좋습니다
- 또한 하나가 아닌 수백 개의 볼륨에 의지할 수 있어요. 여러분이 관리하지 않고 백엔드에서 이루어지므로 많은 위험을 줄였다고 할 수 있겠습니다.
도식으로 살펴보겠습니다 3개의 AZ가 있어요. 공유 스토리지 볼륨이 있고 이는 논리 볼륨입니다. 복제, 자가 복구, 자동 확장 등 많은 기능을 가집니다. 여러분이 파란색 데이터를 쓰기 한다면 보다시피 3개의 AZ에 6개의 복제가 생깁니다. 오렌지색 데이터를 쓰기 하면 각 AZ에 6개의 복제가 생기죠. 더 많은 데이터를 쓰기 할수록 각 3개의 AZ에 계속 6개씩의 복제가 나타납니다. 좋은 점은 서로 다른 볼륨으로 나뉘고 잘 실행된다는 겁니다
스토리지에 관해서 알아야 할 건 여기까지입니다. 스토리지에 실제로 접속하는 게 아니라 Amazon이 만든 설계일 뿐이니까요 그러면 Aurora에서 무엇을 필요로 하는지 알려드리겠습니다.
Aurora는 RDS를 위한 다중 AZ라고 할 수 있습니다. 하나의 인스턴스만 쓰기를 할 수 있습니다. 즉 Aurora에 마스터가 있고 거기에 쓰기를 하는 거예요.
마스터가 작동하지 않으면 평균적으로 30초 안에 장애 조치가 이루어집니다. 정말 빠른 속도예요
그리고 마스터 외에도 읽기를 할 수 있는 15개의 읽기 전용 복제본을 가질 수 있죠. 아주 많은 숫자예요 이렇게 읽기 워크로드를 확장합니다. 모든 읽기 전용 복제는 마스터에 장애 발생 시 마스터를 대체할 수 있죠. RDS 작동 방식과는 조금 다르지만 기본적으로 마스터는 하나뿐입니다
읽기 전용 복제의 좋은 점은 리전 간 복제를 지원한다는 거예요. Aurora의 오른쪽 도식에서 다음을 기억해 두세요. 하나의 마스터와 여러 복제가 있고 스토리지는 작은 블록으로 복제, 자가 복구, 확장됩니다
이제 클러스터로서의 Aurora는 어떤지 볼까요
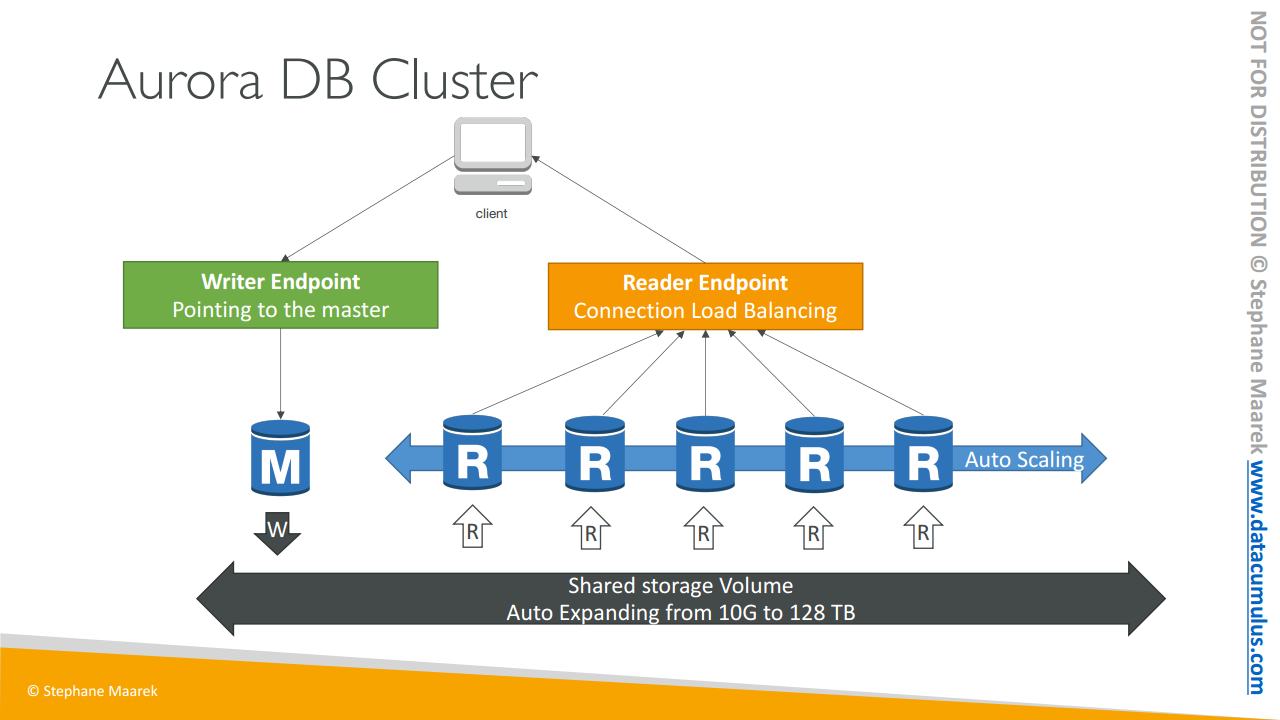
주로 클라이언트가 있을 때 Aurora가 작동하는 방식입니다. 모든 인스턴스와 어떻게 연결할까요?
앞서 말했지만 공유 스토리지 볼륨은 10GB에서 128TB로 자동 확장됩니다, 멋진 기능이죠. 이때 마스터가 유일하게 스토리지에 쓰기를 할 수 있고 변경 및 장애 조치를 할 수 있기 때문에 Aurora는 라이터(Writer) 엔드포인트를 제공합니다. DNS 이름인 라이터 엔드포인트는 항상 마스터를 가리킵니다. 마스터 장애 조치 중에도 클라이언트는 계속 라이터 엔드포인트와 통신해서 자동으로 올바른 인스턴스에 리디렉션되죠.
앞서 말씀드렸듯 읽기 전용 복제가 많이 생기는데 사실 읽기 전용 복제에 오토 스케일링이 있을 수 있어요. 최대 15개의 읽기 전용 복제에 오토 스케일링을 설정할 수 있지요. 따라서 읽기 전용 복제에 적정한 개수를 설정하면 됩니다.
오토 스케일링 때문에 여러분의 애플리케이션이 복제본의 위치와 URL을 추적 및 연결하기는 어렵습니다. 이때 쓰는 방법을 꼭 기억하세요 시험에도 출제될 겁니다. 바로 리더(Reader) 엔드포인트라는 것입니다. 리더 엔드포인트의 기능은 라이터 엔드포인트와 동일합니다. 로드 밸런싱 연결을 도와주고 모든 읽기 전용 복제본에 자동으로 연결합니다. 그래서 클라이언트가 리더 엔드포인트에 연결할 때마다. 읽기 전용 복제본 중 하나에 연결되고 로드 밸런싱 할 수 있게 되지요. 여기서 중요한 건 로드 밸런싱이 이루어지는 곳이 문장 수준이 아니라 연결 수준이라는 사실입니다.
여기까지 Aurora 작동 방식이었어요. 라이터 엔드포인트와 리더 엔드포인트, 그리고 오토 스케일링 및 자동으로 확장되는 공유 스토리지 볼륨과 이 도식을 기억하시면 Aurora를 이해할 수 있을 거예요.

이제 기능에 대해 자세히 보면 말씀드린 내용이 나오는데
-자동 장애 조치, 백업 및 복구 격리와 보안, 산업 규정 준수, 푸시 버튼 스케일링과 다운타임 없는 자동 패치 등 이런 기능이 백엔드에서 이루어지니 멋진 일입니다. 확장 모니터링과 정기 유지 보수 등의 모두가 여러분에 도움을 주고 또한 백트랙이라는 기능이 있어서 언제든 데이터를 복원할 수 있습니다. 이 기능은 백업에 의존하는 게 아닙니다
어제 오후 4시로 복원한다고 말한 다음에 갑자기 어제 오후 5시로 바꿔서 복원하고 싶어져도 아주 깔끔하게 처리됩니다
- 보안의 경우 RDS와 유사합니다 같은 엔진을 사용하거든요. Postgres와 MySQL과 같지요
- KMS를 사용해 암호화합니다
- 자동 백업 및 스냅샷 그리고 복제본도 암호화되는데,
- SSL을 통해 전송 중 암호화가 이루어져요. MySQL 및 Postgres와 정확히 같은 과정입니다
- IAM 토큰을 사용하는 인증도 있습니다. RDS와 같은 방식이에요. MySQL과 Postgres RDS의 통합에 의해 가능하죠
- 보안 그룹을 사용한 인스턴스 보호는 여전히 여러분의 몫이며
- 인스턴스에 SSH 할 수 없습니다. 즉 Aurora 보안은 전부 RDS 보안과 동일합니다
93. Amazon Aurora - Hands On
이제 오로라 데이터베이스를 생성해 보겠습니다
모든 옵션 사용을 위해 Standard create로 하죠
그리고 Amazon Aurora를 선택합니다
두 가지의 오로라 에디션이 있는데요
MySQL-Compatible 에디션과
PostgreSQL-Compatible 에디션입니다
MySQL-Compatible 에디션을 사용하겠습니다
보여드릴 기능이 더 많기 때문입니다
먼저, 용량 유형입니다
다음 강의에서 고급 기능을 살펴보겠지만
이번 실습에서도 미리 확인할 수 있습니다
서버 인스턴스의 크기를 관리하는 프로비저닝과
데이터베이스의 로드를 기반으로 오로라에서 자동으로 용량을 늘리는
서버리스 기능이 있으며 이는 간헐적이거나
예측 불가능한 워크로드에 매우 적합합니다
간략하게 진행하기 위해 많은 기능을 제공하는
프로비저닝을 선택하겠습니다
서버리스는 꽤 어려운 기능입니다
또, 복제 기능이 있는데요
여기 단일 마스터가 있는데요 말씀드린 대로
단일 라이터 인스턴스에만 기록할 수 있으며
대부분의 워크로드의 범용 옵션으로 적합합니다
다중 마스터는 다중 라이터 인스턴스에
기록하는 것을 지원합니다
지속적인 기록이 필요할 때 적합합니다
최대한 많은 기능을 유지하기 위해서
단일 마스터를 선택하겠습니다
다음은 엔진 버전입니다
보시다시피 버전이 53개가 있습니다
다양한 버전이 있는데요
각 버전은 각기 다른 기능을 지원합니다
그리고 필터도 있습니다
필터를 사용하면
전역 데이터베이스를 지원하는 버전을 선택해
오로라 데이터베이스를 다양한 AWS 리전으로 확장하거나
병렬 쿼리만 지원하는 버전 등을 선택할 수 있습니다
지금은 전역 데이터베이스 기능을 지원하는 버전을 선택하고
Amazon 오로라가 추천하는 것을 선택하겠습니다
이 버전을 선택하겠습니다
이제 스크롤을 내리면
제작 또는 개발 및 테스트의 템플릿이 있고
오로라용 프리 티어는 없습니다
제작으로 선택하고 모든 기능을 확인하겠습니다
데이터베이스 식별자는 database-2로 하고
사용자 이름은 admin으로 하겠습니다
암호는 password로 하죠
암호를 입력하겠습니다
스크롤을 더 내려서
데이터베이스 인스턴스 클래스를 선택하겠습니다
확장 가능 클래스와 메모리가 있는데
비용을 최소한으로
계속 유지하려면
db.t3.small을 선택하세요
가장 작은 인스턴스입니다
하지만 여기서 데이터베이스를 생성하면
비용이 조금 발생되는 것을 다시 알려드립니다
다음은 가용성과 내구성입니다
다중 AZ 배포를 생성할 때
가장 좋은 방법입니다
오로라 복제를 하지 않거나
복제를 설정하거나 다른 AZ에서 리더 노드를 설정할 수 있습니다
확장된 가용성에도 적합하므로 이것을 선택하겠습니다
빠른 장애 조치와 고가용성도 제공합니다
하지만 비용이 더 듭니다
오로라 복제본 생성을 선택하지 않으면
스토리지 계층에서 3개의 AZ에 전반적으로
무엇이 복제됐는지는 상관없습니다
저는 복제본 생성을 선택하겠습니다
그리고 VPC와 서브넷 그룹을 설정합니다
공용 액세스도
설정해야 하는데요
저는 Yes를 선택하지 않지만 여러분은 선택해도 됩니다
다음은 보안 그룹입니다
새 보안 그룹을 생성하죠
demo-aurora-mysql로 이름을 설정하고
3306번 포트로 설정하겠습니다
데이터베이스 인증에서는
알고 있는 암호 또는 매우 편리한
암호와 IAM 데이터베이스 방식을 선택할 수 있습니다
추가 옵션에서는 초기 데이터베이스 이름을 설정할 수 있습니다
제 DB와 같은 이름으로도요 지금은 상관없는 매개변수 그룹과
장애 조치도 설정할 수 있습니다
백업은 인스턴스에 백업을 보관하는 기간을 나타내며
1일이면 충분하지만 35일까지 선택할 수 있습니다
데이터베이스 암호화를 선택하고
AWS KMS 키는
선택된 것으로 하겠습니다
어느 시점에서 빠르게 이 데이터베이스를 백트랙하려면
데이터베이스의
백트랙 기능을 활성화하고
백트랙 시간은 72시간까지로 설정합니다
비활성화할 수 있는데 지금은 비활성화하죠
세분화된 모니터링을 위해
강화된 모니터링을 선택하고
로그 관련해서는
CloudWatch로 전송을 설정하죠
유지 보수와 기간도 설정하고
삭제 방지도 활성화할 수 있는데
지금은 비활성화하겠습니다
이제 데이터베이스를 생성하죠
보시다시피 시간이 조금 소요됩니다
잠깐 영상을 멈추고 생성되면 다시 돌아오겠습니다
오로라 데이터베이스가 생성됐습니다
라이터 인스턴스와 리더 인스턴스의
리전 클러스터가 있습니다
여기서 중요한 것은
기록하고 읽는 인스턴스가 각기 다른 인스턴스와
다른 AZ에 있는 것입니다
이것이 오로라의 전체 권한입니다
database-2를 클릭하면
연결성에 엔드 포인트가 2개 있습니다
리더 엔드 포인트와 라이터 엔드 포인트입니다
매우 편리한 엔드 포인트인데요
각각 언제나 올바른 라이터 인스턴스와
리더 인스턴스로 연결되기 때문입니다
이 엔드 포인트는 애플리케이션을 오로라로 연결할 때 사용해야 합니다
하지만 이쪽 인스턴스를 클릭하면
전용 엔드 포인트가 있고
이쪽 인스턴스 또한
전용 엔드 포인트가 생성 중이며
이렇게 모두 생성됐습니다
이런 훌륭한 기능뿐만 아니라
또 다른 기능도 있는데
리더 클러스터에 더 많은 리더를 추가해
스케일링 용량을 추가할 수 있습니다
다른 리전에 복제본을 얻으려면
리전 간 읽기 전용 복제본을 생성할 수 있습니다
언제든지 복원할 수도 있습니다
복제본 자동 스케일링 추가할 수 있습니다
정말 중요한 기능인데요
정책을 생성할 수 있기 때문이며
오로라 복제본의 평균 CPU 사용량을 기반으로 하거나
오로라 복제본으로의 평균 연결 수를 기반으로
읽기 전용 복제본을 스케일링할 수 있죠
ReadReplicasScalingPolicy로 이름을 설정하겠습니다
그리고 읽기 전용 복제본이 60%의 목푯값을 갖도록 하겠습니다
이쪽에서 읽기 전용 복제본을 추가 생성할 수 있습니다
또한, 타당한 정책을 찾기 위해
기간별 스케일을 정의할 수 있습니다
최소, 최대 용량은 어떨까요?
최소 1개에서 15개까지 오로라 복제본을 가질 수 있습니다
이는 데이터베이스로 읽기 전용 복제본을 오토 스케일링하는데 매우 편리합니다
지금은 취소하겠습니다
이제 데이터베이스와 엔드 포인트가 사용 가능한지 확인했습니다
이제 다 됐습니다
마지막으로 보여드릴 것은
AWS 리전을 추가하고 작업을 수행하는 오로라의 전체 권한입니다
이는 전역 데이터베이스 기능을
활성화 한 버전의 오로라를 선택한 경우에만 가능합니다
여기서 다른 리전에 데이터베이스를 추가하면
각각의 전역 데이터베이스를 얻게 됩니다
보시다시피 이 클러스터로는 불가능한데요
호환 가능한 크기의 인스턴스가 필요하기 때문입니다
그래서 인스턴스를 변경해야 하는데
예를 들어, 더 큰 유형의 인스턴스로 변경하면
데이터베이스 클러스터에 리전을 추가할 수 있습니다
이 기능도 있다는 것을 알려드리려고 보여드렸습니다
오로라는 여기까지입니다
놀라운 성능을 가진
놀라운 데이터베이스의 모든 것을 살펴봤고
스케일링 용량, 전역, 서버리스 등을 살펴봤습니다
완벽한 데이터베이스죠
AWS의 이 서비스가 정말 좋습니다
이제 실습을 마치면서
이 데이터베이스를 삭제해야 하는데
보시다시피 불가능합니다
먼저 리더 인스턴스를 삭제해야 합니다
delete me를 입력해 삭제하고 라이터 인스턴스를 삭제하려면
다시 Action에서 delete me를 입력해 삭제합니다
전체 인스턴스가 삭제되면
전체 클러스터를 삭제할 수 있습니다
94. Amazon Aurora - Advanced Concepts

이제 시험에서 꼭 알아야할 오로라의 심화된 개념을 살펴보겠습니다
오토 스케일링 복제본에 대해 알아보겠습니다. 클라이언트가 있고 오로라 인스턴스가 세 개 있다고 가정해 보겠습니다. 하나는 라이터 엔드 포인트를 통해 쓰고 다른 두 개는 리더 엔드 포인트 통해 읽습니다. 리더 엔드 포인트에서 너무나도 많은 읽기 요청이 있어서 Amazon 오로라 데이터베이스의 CPU 사용량이 증가했다고 합시다. 이 경우 오토 스케일링 복제본을 설정할 수 있습니다. 그렇게 하면 Amazon 오로라 복제본이 추가되고 그러면 자동으로 리더 앤드 포인트가 이 새 복제본을 포함할 수 있도록 확장될 겁니다. 이 새 복제본은 트래픽을 수신하기 시작하고 전체 CPU 사용량을 낮추기 위해 좀 더 분산된 방식으로 읽기를 수행합니다. 이것이 오토 스케일링 복제본입니다

두 번째로 사용자 지정 앤드 포인트입니다
동일한 설정이지만 이번에는 두 종류의 복제본이 있다고 해보겠습니다. 보시듯 db.r3.large와 db.r5.2xlarge가 있습니다. 따라서 일부 읽기 전용 복제본은 다른 것보다 용량이 큽니다. 이는 오로라 인스턴스의 서브셋을 사용자 지정 앤드 포인트로 정의하기 위함입니다 이 두 개의 더 큰 오로라 인스턴스에서 사용자 지정 엔드 포인트를 정의한다고 하겠습니다
그렇게 하는 이유는 이 인스턴스가 더 강력하기 때문에 특정 복제본에 대한 분석 쿼리를 실행하는 것이 더 낫기 때문입니다 . 그렇게 하면 정의된 사용자 지정 앤드 포인트가 생기고 그렇게 사용자 지정 앤드 포인트를 갖게 되면 보통 리더 앤드 포인트 자체는 사용자 지정 앤드 포인트를 정의한 후 사용되지 않습니다 사라지진 않지만 사용되진 않는 거죠. 실무에서는 다양한 워크로드에 대한 많은 사용자 지정 앤드 포인트를 설정하여 오로라 복제본의 하위 집합만을 쿼리할 수 있습니다
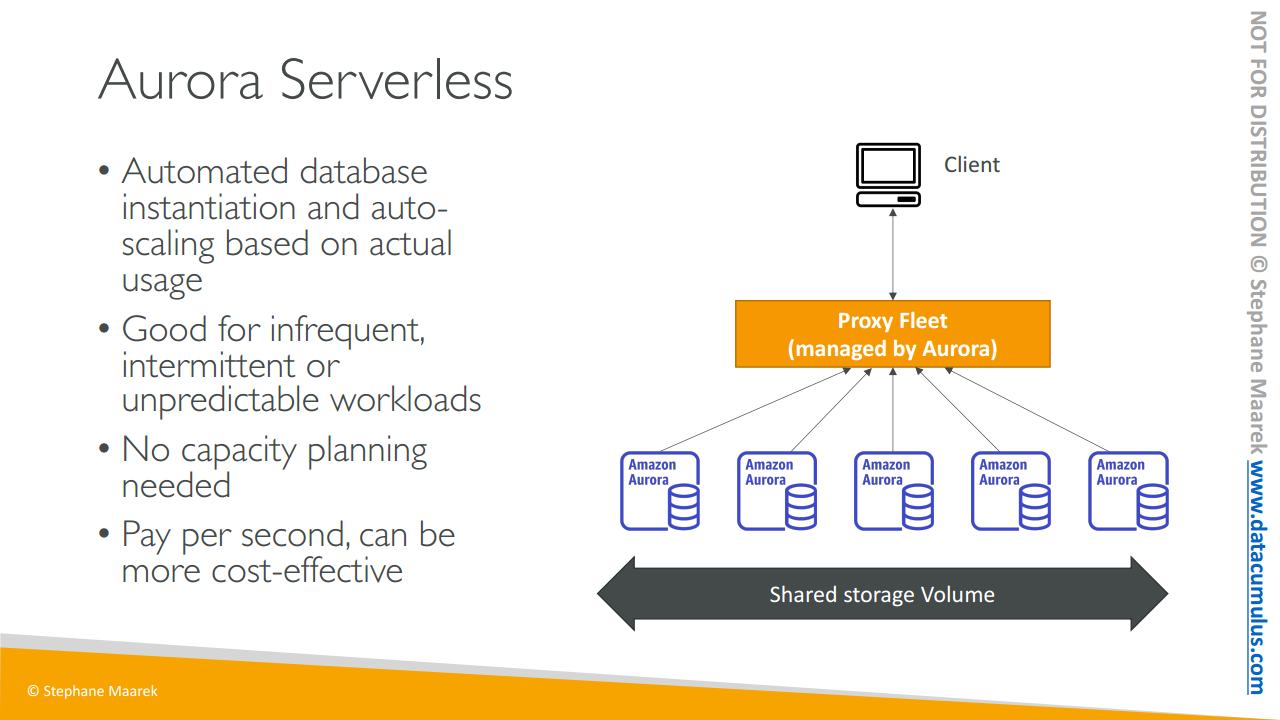
다음은 서버리스 개념입니다
- 이는 자동화된 데이터베이스 인스턴스화와 실제 사용을 기반으로 한 오토 스케일링을 제공합니다.
- 드물거나 간헐적이거나 예측할 수 없는 워크로드가 있을 때 유용하죠.
- 그래서 용량 계획을 수행할 필요가 없습니다
- 서스핀 업 중인 각 오로라 인스턴스의 초당 비용을 지불하기 때문에 훨씬 더 비용면에 효율적일 수 있죠
어떻게 작동할까요?
클라이언트는 오로라에서 관리하는 프록시 플릿과 통신하고 백엔드에서는 서버리스 방식으로 워크로드를 기반으로 많은 오로라 인스턴스가 생성됩니다. 그래서 미리 용량을 프로비저닝할 필요가 없습니다.
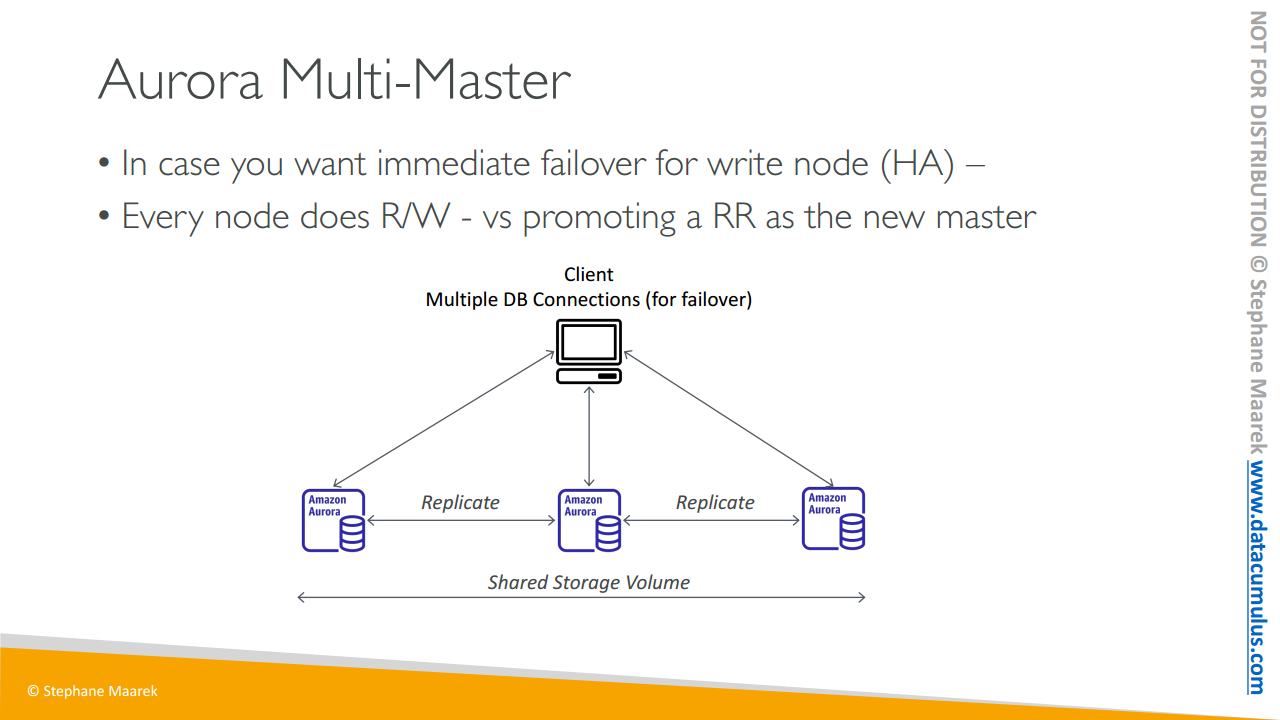
다음으로 다중 마스터가 있습니다
라이터 노드에 대한 즉각적인 장애 조치를 원하는 경우 즉 라이터 노드에 대한 높은 가용성을 원하는 경우에 씁니다
이 경우 오로라 클러스터에 있는 모든 노드가 읽기와 쓰기 작업을 합니다. 이 때 쓰기 노드가 하나만 있고 다운돼서 실패하게 되면 읽기 복제본을 새로운 마스터로 승격시킵니다.
여기 오로라 인스턴스가 세 개 있습니다. 서로 복제를 수행하고 있죠. 공유 스토리지 볼륨이 있고 클라이언트는 데이터베이스 연결을 여러 개 갖습니다. 모든 오로라 인스턴스는 쓰기 작업을 수행할 수 있고 만일 어떤 오로라 인스턴스가 실패하면 라이터 노드에 대한 즉각적인 장애 조치를 제공하는 다른 노드로 자동 장애 조치를 수행할 수 있습니다.
이는 시험에서 출제될 사용 사례와 시나리오의 종류입니다

마지막으로 글로벌 오로라에 대해 살펴보겠습니다
오로라 리전 간 읽기 전용 복제본이 있다면
- 재해 복구에도 유용하고
- 아주 간단하게 구현할 수 있습니다
그러나 오늘날 권장되는 작업 방식인 오로라 글로벌 데이터베이스를 설정할 수도 있죠.
- 이 경우 모든 읽기 및 쓰기가 발생하는 하나의 기본 리전이 있지만
- 최대 다섯 개의 보조 읽기 전용 리전을 설정할 수도 있습니다. 보조 리전당 복제본 랙이 1초 미만이어야 하고
- 최대 16개의 읽기 전용 복제본을 가질 수 있습니다
- 그러면 전 세계의 읽기 전용 복제본에 대한 지연 시간을 줄일 수 있습니다
- 또 재해 복구 목적으로 다른 리전을 승격하는 어떤 리전에서 데이터베이스의 중단이 발생하더라도 RTO가 있으므로 복구 시간 목표는 1분 미만이 될 겁니다. 즉 다른 라전으로 복구하는 데 1분 미만이 소요된다는 거죠
한 번 같이 살펴보죠. 애플리케이션이 읽기 및 쓰기를 수행하는 기본 리전으로 us-east-1이 있습니다. 그런 다음 eu-west-1에 보조 리전을 설정합니다. 여기에서 오로라의 글로벌 데이터베이스에서 복제가 일부 일어나고 그 리전의 애플리케이션은 이 설정에서 읽기 작업만 수행할 수 있습니다. 그러나 us-east-1이 실패하는 경우 eu-west-1를 읽기-쓰기 오로라 클러스터로 승격하여 장애 조치할 수 있죠.
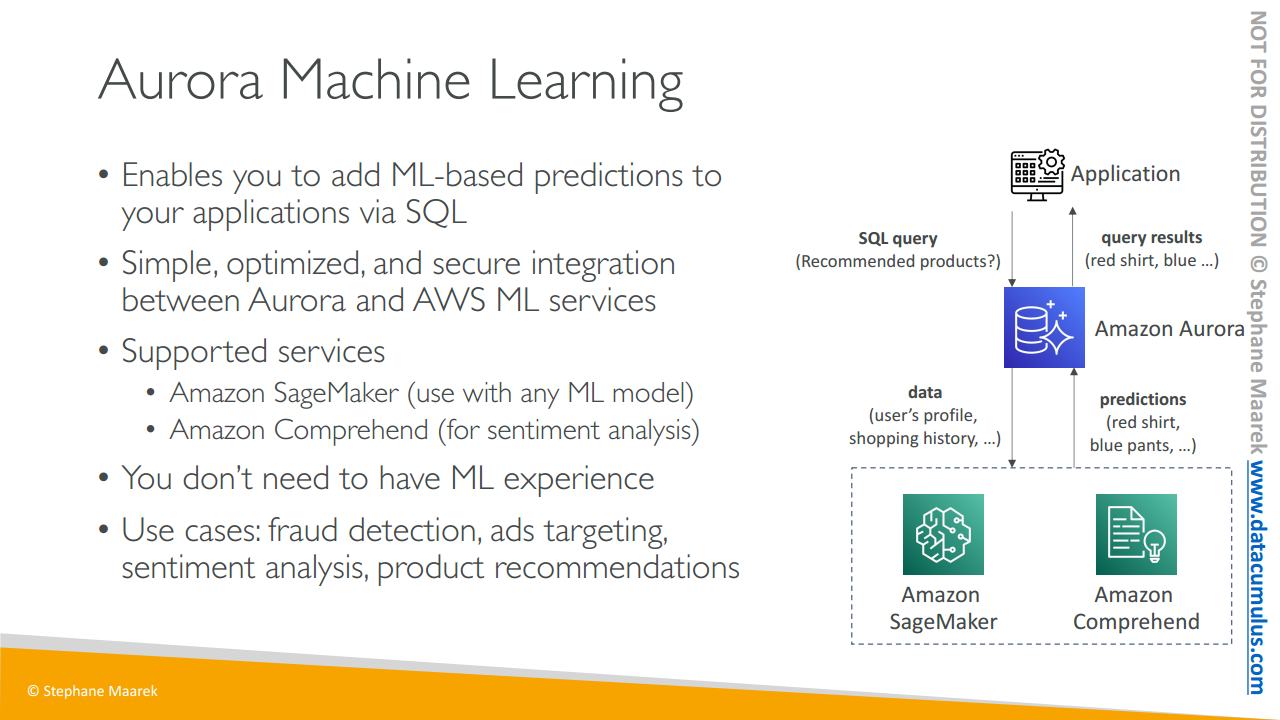
또한 오로라는 AWS 내의 머신 러닝 서비스와 통합됩니다
오로라 머신 러닝은 SQL 인터페이스를 통해 애플리케이션에 ML 기반 예측을 추가할 수 있는 개념입니다
오로라와 다양한 AWS 머신 러닝 서비스 간의 간단하고 최적화된 안전한 통합입니다
지원되는 두 서비스는 백엔드에서
- 모든 종류의 머신 러닝 모델을 사용할 수 있는 SageMaker와
- 감정 분석을 수행할 때 쓰는 Amazon Comprehend가 있죠. SageMaker나 Comprehend를 아주 잘 알 필요는 없습니다. 오로라가 이들과 통합되어 있다는 사실만 알면 됩니다
오로라 머신 러닝을 사용하기 위해 머신 러닝 경험은 필요 없습니다
사용 사례는 오로라 내에서 하는 사기 탐지, 광고 타겟팅 감정 분석 그리고 제품 추천입니다
즉 아키텍처 아이디어를 제공하기 위해 오로라는 AWS의 머신 러닝 서비스에 연결되고 애플리케이션은 매우 간단한 SQL 쿼리를 실행할 수 있습니다. 예를 들어 추천 제품은 무엇입니까? 같은 쿼리죠. 오로라는 사용자 프로필 쇼핑 내역 등과 같은 데이터를 머신 러닝 서비스로 보냅니다. 그러면 머신 러닝 서비스가 예측을 오로라에 직접 반환합니다. 가령 사용자는 빨간 셔츠와 파란 바지를 구매해야 한다는 예측이 나오면 오로라가 이 SQL 쿼리의 결과를 애플리케이션에 반환합니다. 매우 편리한 기능이죠
여기까지가 시험을 위해 알아야할 기능들이었습니다




95. ElastiCache 개요

Amazon 일래스틱 캐시를 살펴보겠습니다
- RDS와 동일한 방식으로 관계형 데이터베이스를 관리할 수 있죠
- 또한, 일래스틱 캐시는 레디스 또는 멤캐시트와 같은 캐시 기술을 관리할 수 있도록 합니다
- 캐시란 무엇일까요? 캐시는 높은 성능과 낮은 지연 시간을 가진 인 메모리 데이터베이스입니다
- 그리고 일래스틱 캐시를 사용하면 읽기 집약적인 워크로드의 부하를 줄이는데 도움이 됩니다. 이 개념은 일반적인 쿼리가 캐시 되어 데이터베이스가 매번 쿼리 되지 않는 것이며 캐시는 이러한 쿼리의 결과를 검색할 때 사용할 수 있는 것입니다
- 애플리케이션의 상태를 Amazon 일래스틱 캐시에 저장해 애플리케이션을 무상태로 만들 수 있도록 합니다
- RDS와 같은 장점을 갖기 때문에 AWS는 동일한 유지 보수를 수행합니다. 운영 체제, 패치, 최적화와 설정, 구성, 모니터링, 장애 회복 그리고 백업을 수행하죠.
- 일래스틱 캐시를 사용할 때 애플리케이션에 관한 몇 가지 어려운 코드 변경을 요청할 수도 있습니다. 단순한 활성화가 아니라 캐시를 사용합니다. 데이터베이스 쿼리 전과 후에 캐시를 쿼리하도록 애플리케이션을 변경해야 하죠.
그 방법은 잠시 후에 확인하겠습니다

이제 일래스틱 캐시 사용을 위한 아키텍처를 살펴보겠습니다. 여러 가지 중에서 예시를 하나 들어보죠
- 일래스틱 캐시와 RDS 데이터베이스 그리고 애플리케이션이 있고 애플리케이션은 일래스틱 캐시를 쿼리합니다. 쿼리가 이미 생성됐는지 이미 생성되어 일래스틱 캐시에 저장됐는지 확인하는 것은 캐시 히트(cache hit)고 이는 일래스틱 캐시에서 바로 응답을 얻어서 쿼리하기 위해 데이터베이스로 이동하는 동선을 줄여줍니다.
캐시 미스(cache miss)의 경우에는 데이터베이스에서 데이터를 가져와서 데이터베이스에서 읽습니다. 동일한 쿼리가 발생하는 다른 애플리케이션이나 인스턴스에서는 데이터를 캐시에 다시 기록하여 다음에는 같은 쿼리로 캐시 히트를 얻도록 합니다.
- 이는 RDS 데이터베이스에서 부하를 줄이는데
- 도움을 주는데 데이터를 캐시에 저장하기 때문에 캐시 무효화 전략이 있어야 하며 가장 최근 데이터만 사용하는지 확인해야 합니다. 이것이 캐싱 기술 사용과 연관된 어려움이라고 할 수 있죠
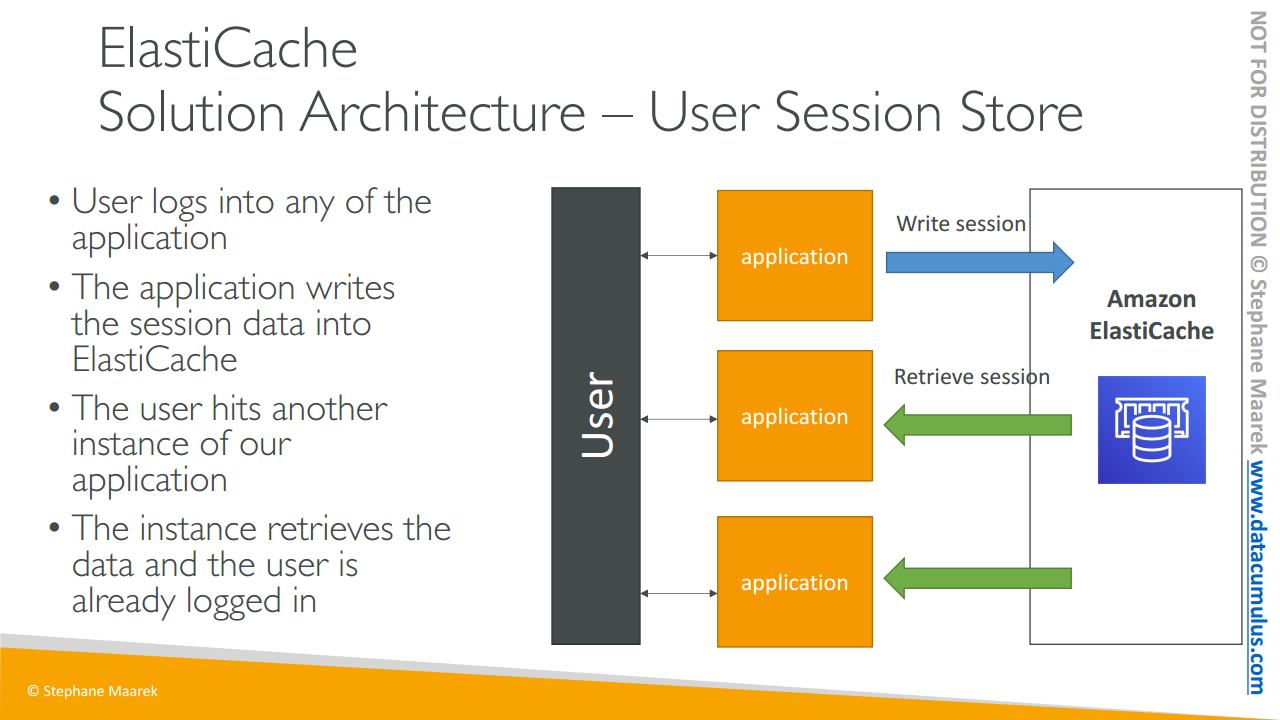
- 다른 아키텍처는 사용자 세션을 저장해 애플리케이션을 무상태로 만드는 것입니다.
- 사용자가 애플리케이션의 모든 계정에 로그인하면 애플리케이션이 일래스틱 캐시에 세션 데이터를 기록하는 것입니다
- 사용자가 애플리케이션의 다른 인스턴스로 리디렉션 되면 애플리케이션은 일래스틱 캐시에서 직접 세션 캐시를 검색할 수 있습니다.
- 그래서 사용자는 계속 로그인한 상태로 한 번 더 로그인 할 필요가 없죠
사용자의 세션 데이터를 일래스틱 캐시에 기록해서 애플리케이션을 무상태로 만든 것입니다

레디스와 멤캐시트의 차이를 전반적으로 이해하는 것도 시험에 출제될 수 있습니다
- 레디스(Redis)는 자동 장애 조치로 다중 AZ를 수행하는 기술이며
- 읽기 전용 복제본은 읽기 스케일링에 사용되며 가용성이 높습니다. 약간 RDS와 비슷합니다.
- 그리고 지속성으로 인해 데이터 내구성도 있으며
- 백업과 기능 복원 기능도 있습니다
RDS와 많이 유사합니다
- 멤캐시트(Memcached)는 데이터 분할에 다중 노드를 사용하고 이를 샤딩(sharding) 이라고 합니다
- 가용성이 높지 않고 복제도 발생하지 않습니다
- 지속적인 캐시가 아닙니다
- 백업과 복원 기능도 없죠
- 그리고 다중 스레드 아키텍처로
몇몇 샤딩과 함께 캐시에서 함께 실행되는 여러 인스턴스가 있습니다
여기서 기억해야 할 것은 레디스는 고가용성과 백업 읽기 전용 복제본 등이 있고 멤캐시트는 데이터를 손실할 수 없는 단순한 분산 캐시입니다. 가용성이 높지 않고 백업과 복원 기능도 없습니다. 바로 이것이 두 기술의 가장 큰 차이점입니다
여기까지입니다 즐거우셨길 바랍니다
다음 강의에서 뵙겠습니다
96. ElasticCache - 실습
이제 ElastiCache 서비스를 사용하여 연습해 보겠습니다
첫 Redis 데이터베이스를 생성해 봅시다
Get started를 누르면
클러스터를 생성하는 두 가지 옵션이 있습니다
Redis 또는 Memcached인데 Create cluster를 클릭하고
Redis 클러스터로 설정합니다
나중에 Memcached 옵션을 살펴봐도 좋아요
여기가 클러스터 생성 UI입니다
새 클러스터를 구성하고 만들거나 백업에서 복원할 수 있습니다
기존에 만든 백업이 있다면 가능해요
다음은 Cluster mode를 활성화 옵션이 있는데요
활성화하면 여러 복제가 생기고
확장성 및 가용성을 향상시킵니다 아니면 비활성화해서
단일 샤드, 즉 단일 노드 그룹과 최대 1개의 기본 노드 및
최대 5개의 읽기 전용 복제를 얻게 됩니다
기능을 간단하고 무료로 쓰기 위해 클러스터 모드를 비활성화합시다
다음은 Cluster info입니다 demo-radis로 하고 Location은
ElastiCache 서비스가 클라우드에 위치하는지
혹은 AWS Outposts에 의해 온프레미스에 위치하는지 선택합니다
단순한 기능에 온프레미스도 없으니 클라우드를 사용하겠습니다
Multi-AZ는 향상된 고가용성을 제공하는데 AZ 간 읽기 전용 복제의
자동 장애 조치를 통해 실행됩니다
혹은 이런 기본 노드 장애 조치를 비활성화할 수 있어요
그렇지 않고 활성화하면 비용을 더 지불해야 하는데
우리는 ElastiCache 클러스터를 만드는 데모만 실행하면 됩니다
그리고 Auto-failover로 고가용성을 얻을 수 있습니다
읽기 전용 복제에 대해 자동 장애 조치가 이루어지거든요
여기는 이대로 둘게요
Cluster settings에서 엔진 버전과 포트를
기본값으로 지정하고 매개변수 그룹도 기본값으로 합니다
이때 노드 유형은 우리가 필요한 것보다 너무 높아서
따라서 micro 유형의 cache를 사용하겠습니다
t2.micro를 사용합니다 프리 티어가 적용되거든요
프리 티어인 것들이 더 있긴 할 거예요 복제본의 수는 0에서 5사이고
만약 복제가 두 개 있다면
당연히 다중 AZ를 설정합니다
하지만 복제를 하나로 설정하면 다중 AZ를 활성화할 수 없어요
보다시피 옵션이 모두 비활성화되었습니다
프리 티어에서 사용해야 하니
복제를 만들지 않겠습니다 따라서 개수는 0입니다
다음은 Subnet group인데 서브넷 컬렉션을 뜻합니다
my-first-subnet-group
그러면 ElastiCache 서비스가 서브넷 그룹에서 노드를 실행하죠
기본 VPC를 선택하고 나면
서브넷 세 개가 기본으로 생성 및 선택됐으니, Next를 클릭합니다
원한다면 키를 사용하여 저장된 암호화를 활성화하거나
전송 중 암호화를 선택해도 됩니다
전송 중 암호화를 활성화하면 액세스 제어를 얻을 수 있어요
사용자 액세스의 Redis AUTH로 하고 토큰을 지정할 수 있습니다
클러스터 연결에 그 토큰을 사용할 수 있지만 비활성화할게요
Backup 설정에서 데이터베이스에서 자동 백업을 활성화할까요?
비활성화하겠습니다
Maintenance에서도 업그레이드를 수행할 수 있고, Logs, Tags
보다시피 RDS와 비슷하죠 모두 만들어졌습니다
계속해서 ElastiCache 노드를 생성해 보겠습니다, 하나만 있어요
즉 하나의 노드에 대한 클러스터가 됩니다
ElastiCache 데이터베이스가 생성되었으며 클릭할 수 있습니다
코드로 작성한 애플리케이션이 있다면
기본 엔드포인트를 사용할 수 있고
읽기 전용 복제라면 캐시에서 리더 엔드포인트로 읽기 가능해요
그런데 당장 Redis 캐시에 연결하는 방법을
보여드리기는 힘든데요 쉽지가 않고
코드도 작성해야 해서
너무 복잡해질 겁니다 그러나 AWS 관점에서 보면
이 콘솔에서 모든 세부 사항을 확인할 수 있습니다
Nodes, Metrics, Logs Network security도 마찬가지죠
그리고 RDS와 비슷합니다 RDS와 매우 유사한 서비스지만
Redis와 Memcached를 대상으로 하는 서비스예요
마지막으로 Redis 클러스터에서 Actions에서 Delete를 누릅니다
백업은 생성하지 않고 클러스터 이름을 적고 Delete으로 삭제하겠습니다
97. 솔루션 설계자를 위한 ElastiCache

시험에 출제될 일래스티 캐시에 대해 알아야 할 몇 가지 추가 정보에 대해 이야기해 보겠습니다
우선 일래스티 캐시의 모든 캐시는
- IAM 인증을 지원하지 않습니다
- 일래스티 캐시에서 정의할 IAM 정책은 AWS API 수준 보안에만 사용됩니다. 즉 캐시 생성, 캐시 삭제 같은 종류의 작업을 의미합니다. 그러나 캐시 내의 모든 작업은 IAM을 사용하지 않습니다
레디스를 인증하려면 레디스 AUTH를 사용하여
- 레디스 클러스터를 생성할 때 비밀번호나 토큰를 설정할 수 있습니다. 이렇게 하면 캐시에 들어갈 때 비밀번호를 사용할 수 있습니다
- 이는 캐시에 사용할 수 있는 보안 그룹에 대한 추가적인 수준의 보안입니다
- 그리고 전송 중 암호화를 위해 SSL 보안을 지원할 수 있습니다
반면 멤캐시트는
- 좀 더 높은 수준인 SASL 기반 인증을 지원합니다. 상당히 고급이라 다른 종류의 인증 메커니즘이죠
캐시의 보안을 살펴보면 EC2 인스턴스에는 자체 보안 그룹도 레디스에 액세스할 수 있는 자체 보안 그룹이 있습니다. 그래서 일래스티 캐시를 사용하여 보안 그룹 수준의 보안을 수행할 수 있죠. 다음 전송 중 암호화를 위해 SSL 암호화가 있습니다. 또 인증을 위해 일래스티 캐시에서 레디스 종류의 캐시를 사용할 때 레디스 AUTH를 가질 수 얻을 수 있습니다

일래스티 캐시에 데이터를 불러오는 패턴에는 세 가지가 있습니다
첫 번째는 레이지 로딩으로 모든 읽기 데이터가 캐시되고 데이터가 캐시에서 부실해질 수 있습니다
라이트 스루는 데이터를 오래된 데이터가 없는 데이터베이스에 기록될 때마다 캐시에 데이터를 추가하거나 업데이트하는 겁니다
그리고 이전에 보셨듯 일래스티 캐시를 세션 저장소로 쓸 수 있고 Time To Live(TTL) 속성으로 세션을 만료시킬 수 있습니다.
캐싱은 아주 어려워서 컴퓨터 과학 분야에서 유명한 인용구가 있습니다. '컴퓨터 과학에는 어려운 일이 두 개가 있다. 바로 캐시 무효화와 이름을 짓는 일이다' 이렇듯 캐싱은 아주 복잡한 주제며 제가 보여드린 건 아주 간단한 개요입니다
어쨌든 레이지 로딩의 전략을 설명드리겠습니다. 일래스티 캐시에 캐시가 히트하면 애플리케이션이 캐시로부터 데이터를 받습니다. 만일 캐시 미스가 있으면 데이터베이스에서 데이터를 읽고 캐시에 씁니다. 이전에 이미 봤던 것들이죠. 캐시 히트가 없을 때만 발생하기 때문에 레이지 로딩이라고 합니다. 그런 다음 데이터를 Amazon 일래스티 캐시에 불러옵니다
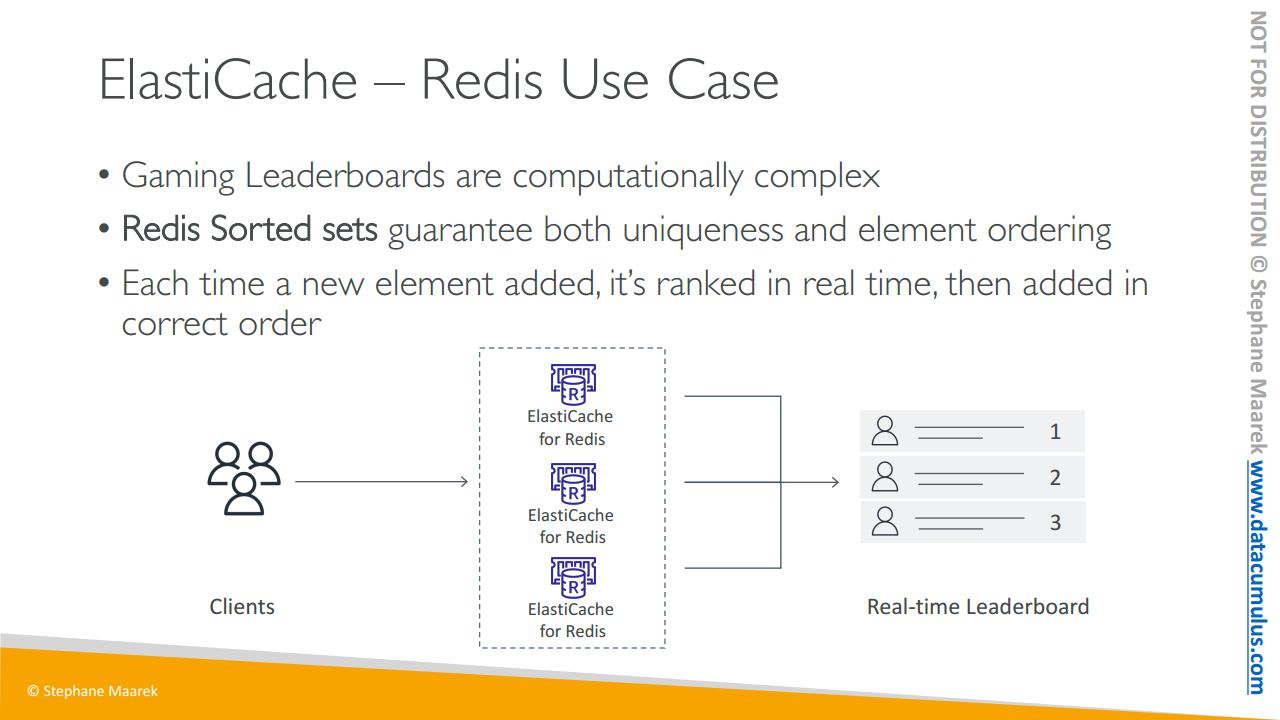
이제 레디스의 사용 사례에 대해 얘기해 볼텐데요. 시험을 위해 알아두셔야 할 부분이 있습니다
게임 리더보드 생성에 대한 겁니다. 매우 복잡합니다. 게임의 어느 시점에서든 누가 1위고 누가 2위고 3위인지 가려내는 개념입니다
그래서 레디스에는 고유성과 요소 순서를 모두 보장하는 정렬된 집합이라는 기능이 있습니다
요소가 추가될 때마다 실시간으로 순위가 매겨진 다음 올바른 순서로 추가됩니다.
레디스 클러스터가 있는 경우 실시간으로 1위, 2위, 3위 플레이어가 있는 실시간 리더보드를 생성한다는 개념인 거죠. 그리고 모든 레디스 캐시는 동일한 리더보드를 사용할 수 있습니다. 즉 레디스로 Amazon 일래스티 캐시와 통신할 때 클라이언트는 이 실시간 리더보드에 액세스할 수 있고 애플리케이션 측에서 이 기능을 프로그래밍할 필요가 없습니다. 실시간 리더보드에 액세스하기 위해 레디스의 정렬된 집합을 활용할 수 있습니다
이것은 시험에 나올 수 있는 부분입니다
여기까지입니다
재밌으셨길 바라며 다음 강의에서 뵙겠습니다
다음은 적어도 한 번은 봐야 할 표준 포트 리스트입니다. 암기할 필요는 없지만(시험을 위해 암기할 필요는 없습니다), 그러나 중요 포트(HTTPS - 포트 443)와 데이터베이스 포트(PostgreSQL - 포트 5432)를 구별할 수 있어야 합니다.
중요 포트:
- FTP: 21
- SSH: 22
- SFTP: 22(SSH와 동일)
- HTTP: 80
- HTTPS: 443
vs RDS 데이터베이스 포트:
- PostgreSQL: 5432
- MySQL: 3306
- Oracle RDS: 1521
- MSSQL 서버: 1433
- MariaDB: 3306(MySQL과 동일)
- Aurora: 5432(PostgreSQL 호환 시) 또는 3306(MySQL 호환 시)
이것들을 암기하기 위해 스트레스 받을 필요없이 오늘 한 번, 그리고 시험에 들어가기 전에 한 번만 이 목록을 읽으세요. 그러면 모든 준비가 완료될 것입니다. :)
"중요포트"와 "RDS 데이터베이스포트"를구별할수있어야함을기억하세요.