Cloud 10 - DAS, NAS, SAN, NFS, ISCSI, 3-tier, NIC 가상화 방법, HAProxy
웹서버 SSH(ssh-copy-id, 테라폼 || 앤서블 + )
만약 1000대의 서버에 동일한 명령을 한번에 전달하고 싶다면? (shell script 를 작성하여 전송한다)
-> 테라폼 | 앤서블 => 내가 하는 명령어가 특정 서버에만 전달되도록 하는 것.
클라우드의 핵심 3가지
개인적으로
- 파일 스토리지 : 한대를 가지고 공유하는거
- 블록 스토리지 : 한대를 잘라서 쓰는거
- 오브젝트 스토리지 : 몰라
Block Storage vs. File Storage - YouTube
10분만에 배우는 스토리지! NAS,DAS,SAN이란 뭘까요? - YouTube
DAS : Direct Access Storage : 그냥 연결해서 쓰는 거(블록단위 전송으로 빠름)
NAS : Network Access Storage : 네트워크로 연결해서 데이터를 받아 쓰는 거(얘만 OS 탑제됨 - 포토 스테이션 등)
SAN : Storage Area Network : 광케이블을 연결하는 제품(SAN Switch를 통해 공유되는게 아닌 SAN의 스토리지 공간을 각각 할당해주는 것이다 - 실제 스토리지에서 데이터를 볼 수 없고 서버를 통해서만 볼 수 있다 - 블록단위 전송으로 빠름) 원래 공유되지 않지만 공유를 시킬 수 있는 솔루션도 있다.
ISCSI : IP 기반의 스토리지 네트워크
NFS(파일 스토리지) -> 그냥 폴더를 공유하는 것
파일들이 스토리지에 공유되어 있다.
scalable이 높다. 다수가 한번에 접근 가능, 동기화 가능
그래서 웹호스팅서버나 자료공유, 협력공간이 필요하면 사용한다.
블록 스토리지(볼륨) -> 서버에게 가상의 디스크를 제공하는 것 -> 위치에 의존

SAN(Storage Area Network)를 통해 서버들이 접근한다. 그리고 SAN은 다시금 스토리지들에 연결되어 있다. 이렇게 해서 장점은 Latency를 줄이고 퍼포먼스를 늘리고 Redundant(중복)를 높일 수 있다. 그 결과 한쪽 디바이스에 문제가 생기면 복구시키기 편하다.
그래서 Boot Volume이나 Lowest Latency가 필요할때 사용한다.
오브젝트 스토리지 -> 사람(계정)에게 일정 저장공간을 제공한다 -> 위치에 비의존
일반적 DB보다 훨씬 큰 데이터를 사용하는 관점에서 봤을때 기존의 방식은 너무 비쌈. 그래서 데이터를 저장하기 적합한 플랫폼
오브젝트는 하나의 파일이 여러개의 청크로 쪼개지고 청크가 분산저장된 방식 각 청크마다 메타데이터 값을 가지고 있기 떄문에 NAS와 SAN보다는
3-tier
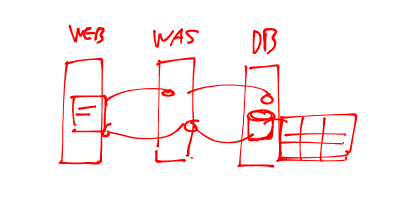
앞에 web server, 연산과 db 연계를 해주는 WAS, 그리고 DB로 구성됨
---
오픈스택
자체적인 클라우드환경
최적의 인프라 환경 구축(HAProxy, Infra, NFS, Load Balancer)

L4/L7 스위치의 대안, 오픈 소스 로드 밸런서 HAProxy (naver.com)
위와같이 인터페이스에 서버들이 연결되어 있다고 하자
프록시는 자기의 BE에 Web1, Web2를 연결한다. 프록시는 RR이기 때문에 Web1에 먼저 보내고 그 다음에 Web2에 보낸다. 그런데 우리가 처음 접근했을때 Web1 가면 세션이 연결되는데 중간에 웹서버2번으로 바뀌었을때의 세션정보와 관련하여서도 LB가 처리해준다.
web1은 nfs에 마운트해서 index.html을 가져와서 LB에 보여준다.

위와같이 LB가 3개정도는 만들어져야 한다. 그런데 이렇게 구분하는게 힘드니 일단 interface를 3개를 만드는 방법도 존재한다.
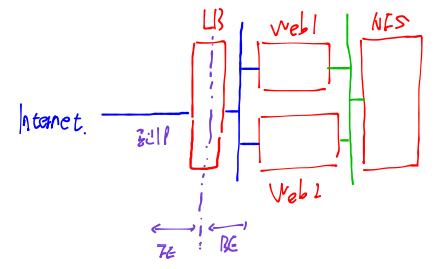
그럼 이제 위와같이 만들것이다. FE, BE가 존재하는데 웹서버는 LB의 접속만을 허용해주어야한다. 그리고 NFS 역시 웹서버의 접근만을 허용해주어야한다.
일단 아키텍처 구성을 위해 기존에 있던 VM들은 모두 삭제하자.


VMnet2가 생기었다. 서브넷 주소는 다를 수 있다.

얘만 구별하기 쉽도록 192.168.2.0으로 만들어주자. 중요한건 VMnet8이 NAT로 되어 있어야한다.
그럼 저기에서 이야기 하는 Type이 뭔지 정의를 해보자
NIC(Network Interface Card) 가상화 방법
1. 브릿지

위와같이 진짜 pc와 VM이 있다고 하자.
여러대의 장비를 한대의 장비에 Multi Access 할 수 있도록 스위치 장비에 진짜 컴퓨터를 연결하고
NIC을 잘라서 하나는 진짜에 나머지는 VM에 껴주는데 이 VM도 Bridge로 연결해버리면 이 PC는 스위치에 연결된것처럼 사용하게 된다.
바로 옆에 가상의 pc가 있는것처럼 사용하는 것은 브릿지 방식이다.
진짜 pc에 물리 NIC을 공유해서 사용하는 방식으로 진짜 PC와 VM은 동일한 Switch에 연결되는 효과를 갖는다. 우리 실습에서는 가상머신이 10.5.1.x 또느 10.5.4.x 주소를 갖는다.
2. NAT(주소변환)

진짜 PC는 NAT를 따라 인터넷으로 나갈 수 있다. VM을 만들었는데 여기에 꽂힌 NIC은 NAT에 연결되어 있다. 진짜 PC역시 NAT에 연결되어 있다. 그럼 진짜 pc를 절반으로 나누어 절반은 공인 나머지는 사설들로 채운다.
VMnet8은 NAT로 되어 있는데 이 친구는 자신만의 ip를 가지고 있다.
본인의 ip로 인터넷 접속은 불가능하다.
즉, VM들이 가상 NAT에 연결되어 진짜 PC를 타고 인터넷으로 나감
3. Host-Only(isolated network)

컴퓨터에 진짜 NIC이 꽂혀있고 내부에 독립내트워크가 있을때 Switch에 VM이 연결되어 있다. 하지마 진짜 PC는 스위치에 연결되지 않은 상황이기에 내부 VM들은 외부 인터넷으로 나갈 수가 없다.
독립적인 네트워크를 구성하지만 외부 네트워크와의 연결점은 없다. 결국 위의 종류중 bridge, NAT는 인터넷 연결이 가능하지만 Host-Only는 불가능하다.
즉, VM끼리만 연결된 방식
환경 구축하기
이제 새로운 VM을 만들자





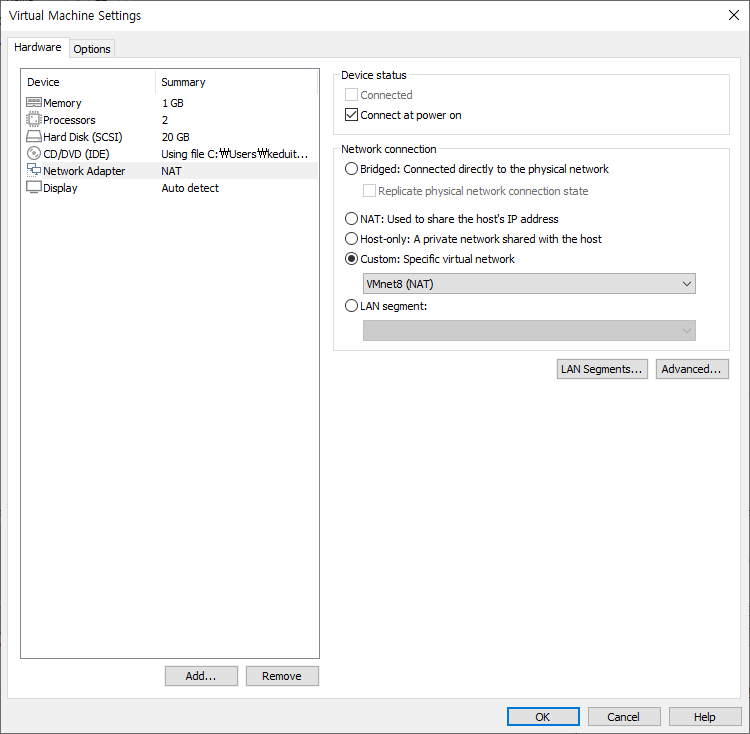

NAT를 선택하면 VMNet 중에 8번(NAT)를 선택하게 되는데 가끔 못찾을때가 있어서 Custom으로 처리한다.
네트워크 2개 더 추가해주자.

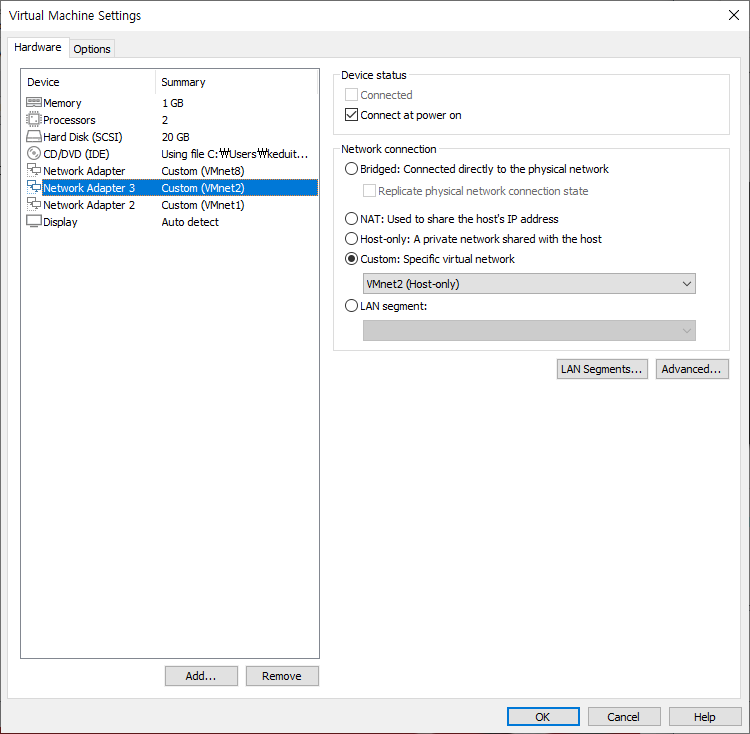
snapshot을 만들기 위해 설치까지 진행




파워를 켰을 때 위와같이 ens32은 8점대 ens33은 1점대 ens34는 2점대여야한다.

ens32의 Automcatically를 클릭

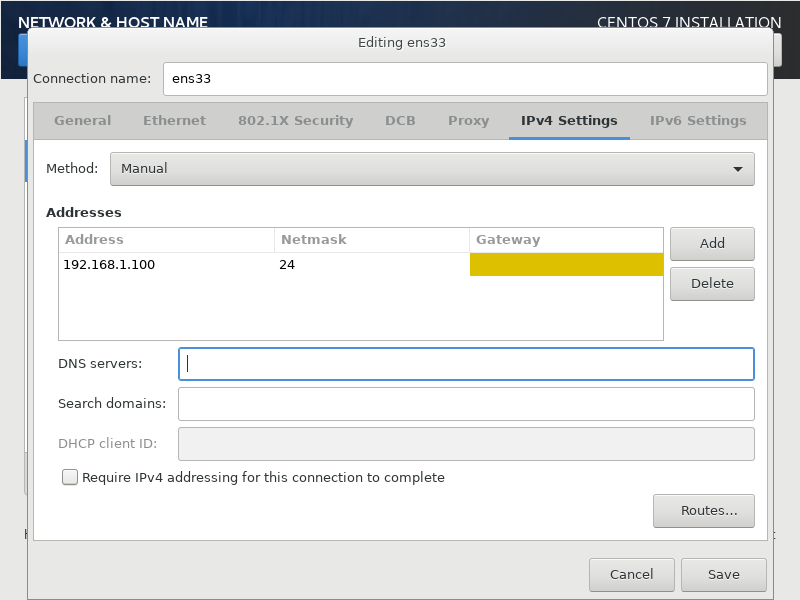
ens33은 네트워크에 연결되는 놈이 아니라서 게이트웨이, DNS가 없다.
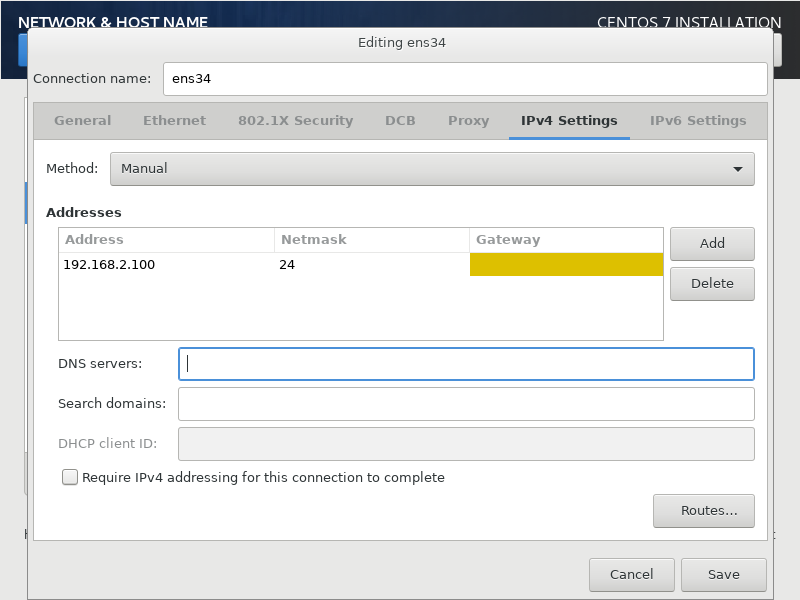
ens34는 2점대를 사용하면 된다. 여기에서도 게이트웨이와 DNS 가 없다.

호스트네임을 lb로 바꾸어놓자.

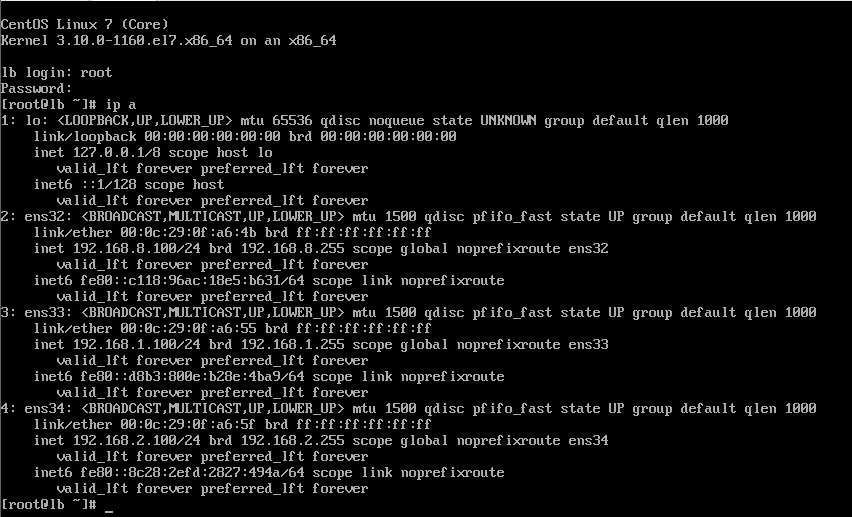
완성해서 로그인 후
ip a
를 입력하자
그리고 다음의 것들을 설치하자
# Starter Pack
yum install -y vim net-tools curl wget git tree nfs-utils httpd && yum update -y && poweroff
yum install -y squid # proxy 서버용
yum install -y nfs-utils # nfs용(기본)
yum install -y haproxy # load-balaner용
yum install -y httpd # 클론용(기본)
마지막으로 bashrc에 alias vi 추가하기

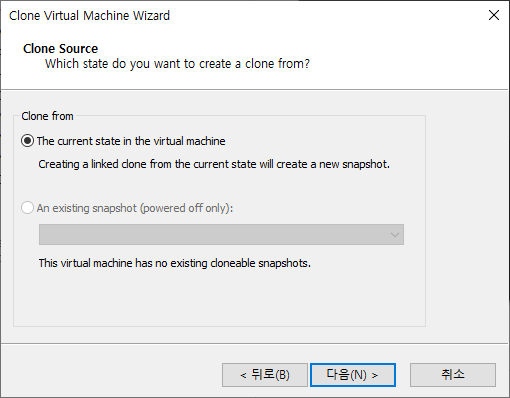

create a linked clone : 가상머신을 연결해서 쓰는거
create a full clone : 독립된 가상머신 만드는 거
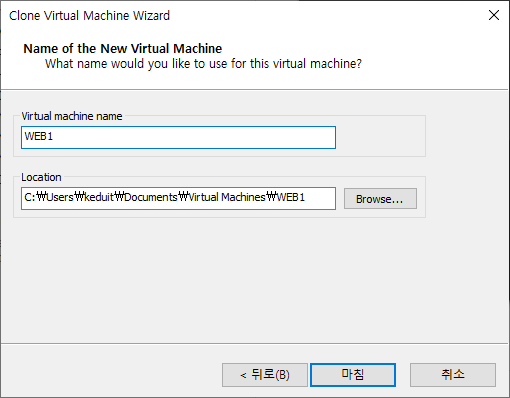
| VM이름 | hostname | ens32 | ens33 | ens34 | |
| LB | lb | 192.168.8.100 | 192.168.1.100 | 192.168.2.100 | |
| WEB1 | web1 | 192.168.8.101 | 192.168.1.101 | 192.168.2.101 | |
| WEB2 | web2 | 192.168.8.102 | 192.168.1.102 | 192.168.2.102 | |
| NFS | nfs | 192.168.8.103 | 192.168.1.103 | 192.168.2.103 |
위와같이 만든다음 4대 다 실행한다.
hostnamectl set-hostname web1 && su1
vi /etc/sysconfig/network-scripts/ifcfg-ens32
vi /etc/sysconfig/network-scripts/ifcfg-ens33
vi /etc/sysconfig/network-scripts/ifcfg-ens34
ip 주소 변경후에는 모든 VM을 재부팅 해주기
단 모든 vm은 방화벽을 종료
SELINUX도 종료 (setenforce 0 && vi /etc/selinux/config 파일을 열어 SELINUX=enforcing을 SELINUX=disabled로 변경)
대충 쉘스크립트를 짜서 만들었다.

개꿀이었다. 이렇게하니 일일히 확인할 필요도 없고 개좋았음
문법은 별거 없다. sed 빼고는 그냥 명령어 나열했다.
이제 네트워크 비활성화를 해놓자

ifdown ens32
포트중 유일하게 ens32만 게이트웨이랑 DNS를 가지고 있기 때문에 web1, web2, nfs가 인터넷으로 가는걸 차단해놓자.
이제부터 이미지 아래 어디에서 활동한건지 나온다.
nfs 서버는 /cloud 라는 디렉토리를 생성하고 index.html 파일을 위치시킨다.
두 대의 웹서버는 웹 접속을 위한 기본 홈 디렉토리인 /var/www/html을 nfs 서버의 /cloud와 마운트한다. 정상적으로 마운트가 되었다면 web1/web2는 /var/www/html 에서 index.html 파일을 볼 수 있어야 한다.

```
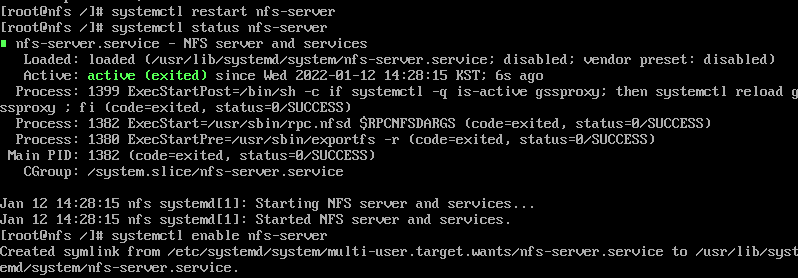
systemctl status nfs-server
```
로 현재 nfs서버가 동작중인지 확인하자
이제 Cloud 디렉토리 만들고 /etc/exports 파일에 접근할 수 있는 IP 주소를 등록해주기
???
그럼 위와같은 구성을 만들어 주면된다.
```
vi /etc/exports
```

```
systemctl restart nfs-server
systemctl enable nfs-server
```
이제 /cloud를 /var/www/html에 마운트하자
먼저 해당 서버에서 마운트를 할 수 있는지 확인하자
```
showmount -e 192.168.2.103
```

```
mount -t nfs 192.168.2.103:/cloud /var/www/html
systemctl start httpd
systemctl enable httpd
```
를 두개의 web1, web2에 해주면된다.
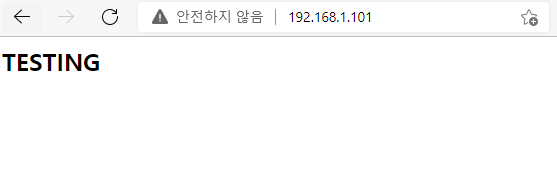

둘다 연결된걸 확인할 수 있다.
LB입장에서 Front End(클라이언트가 접속하는 주소)? Back End(로드 밸런서가 누구에게 넘겨줄 것인가)?
FE : 192.168.8.100
BE : 192.168.1.X
실제로 Backend에 접속하는 호스트의 주소는 무엇인가? 192.168.1.100
HAProxy
이제 HAProxy 구성을 해보자
이번에도 putty를 이용해 ssh>kex에서 Diffie-Hellman group 14,1을 최상위로 올리어 사용하자
```
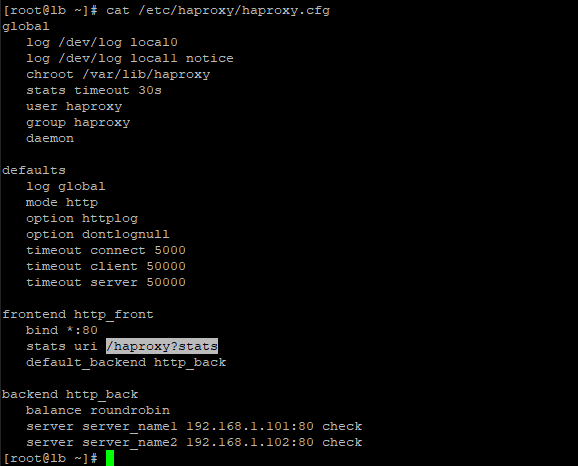
vi /etc/haproxy/haproxy.cfg
```

```
명령어 모드에서 d G # 내용이 모두 삭제되었다.
```
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats timeout 30s
user haproxy
group haproxy
daemon
defaults
log global
mode http #http에 대해서 트래픽 분배예정 -> FE와 BE 설정 필요
option httplog
option dontlognull
timeout connect 5000 # 서버한테 생존여부를 물어본다. 5초마다(5000)
timeout client 50000
timeout server 50000
frontend http_front
bind *:80 # 80번 포트로 접속하면
stats uri /haproxy?stats
default_backend http_back # 이걸 http_back 으로 보내겠다.
backend http_back
balance roundrobin # 이 트래픽을 roundrobin으로 처리하겠다.
server web1 192.168.1.101:80 check # 여기에다가 서버 ip 입력 # 서버한테 생존여부를 물어본다.
server web2 192.168.1.102:80 check #"backup"이 붙으면 대기상태로 남는다. 서버1이 죽으면 active로 바뀐다.
# 만약 죽으면 제외시킨다. 나중에 생존 여부를 받으면 다시 보낸다.
저장하고 그 다음 일을 수행하자
고가용성 : 클라이언트가 필요로 하는 서비스, 리소스등을 적절한 시간에 즉시 제공해 줄 수 있는가? -> 고가용성은 일반적으로 Active/Standby(Active/Active)를 준비하여 Active가 처리하고 문제가 발생하면 대기중이던 Standby가 이를 이어바3아 Active가 된다. 클라이언트는 Active가 활성화, 비활성화 된 것에는 관심을 둘 필요 없이 서비스를 이용하기만 하면 된다.
standby는 두가지가 있다.1. cold standby : 죽었을때 부팅된다.2. hot standby : 전원키고 상시 대기
```
systemctl restart haproxy
systemctl enable haproxy
```
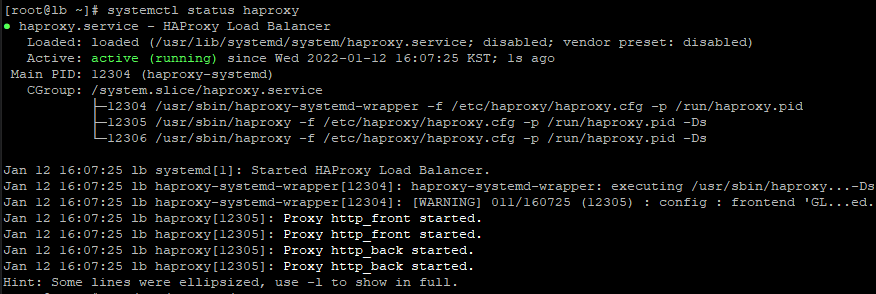
주의할 점!!!
LB는 80번 포트로 들어온 웹접속 요청을 자신이 처리하는 것이 아니라 Backend로 포워딩해서 넘겨주어야 한다. 따라서 LB가 웹서비스(tcp/80)를 제공하고 있다면 자신이 그냥 처리를 해 버리므로 절대 웹서비스를 실행해서는 안된다.
HAProxy란?
HAProxy HAProxy를 공부하기 앞서 로드밸런싱(Load Balancing)을 알아야한다. 로드밸런싱이란? 하나의 서비스에 대한 부하를 여러 서버로 분산하는 것 왜 로드밸런서가 필요할까 위 사진처럼 클라이언트
dev-youngjun.tistory.com
10.5 Load Balancer 만들기 - TheKoguryo's 기술 블로그
10.5 Load Balancer 만들기 - TheKoguryo's 기술 블로그
10.5 Load Balancer 만들기 Load Balancer 만들기 OCI 콘솔에서 내비게이션 메뉴를 엽니다. [Core Infrastructure] >> [Networking] >> [Load Balancers] 항목으로 이동합니다. Load Balancers를 생성할 Region과 Compartment를 확인
thekoguryo.github.io

보다시피 LB로 접속했는데 서버1 또는 서버2 중 하나가 동작했다.
서버에 접속해서 다음을 입력해서
```
tail -1f /var/log/httpd/access_log
```
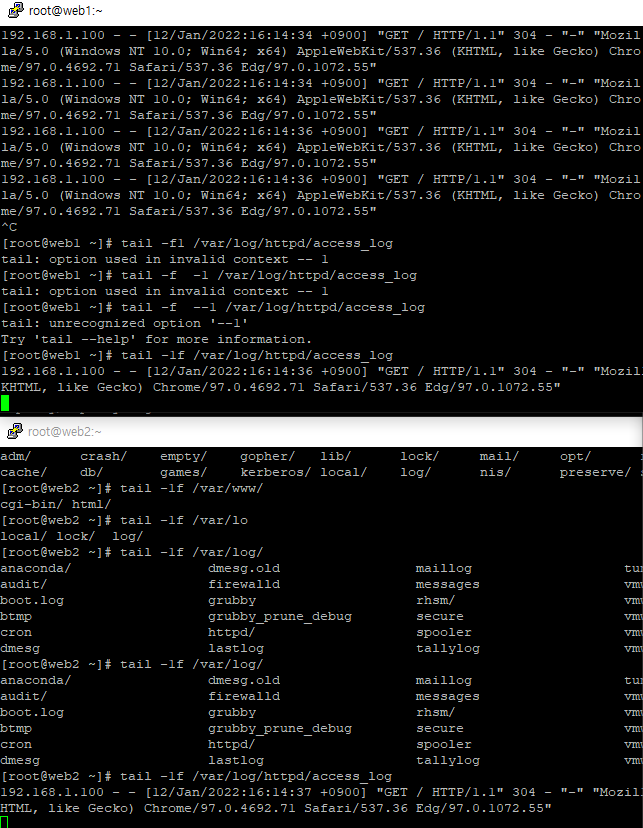
위와같이 마지막 한줄짜리 접속 로그를 실시간 확인할 수 있다.

재접속해보니 첫번쨰 서버에 반응이 왔다.
전체 동작 원리
1. 클라이언트가 http://www.test.com 에 접속
2. 클라이언트의 NIC에 저장된 DNS 서버인 8.8.8.8에게 www.test.com 의 주소를 물어본다.
3. DNS 서버는 www.test.com의 의 주소가 192.168.8.100이라고 알려준다.
4. 클라이언트는 192.168.8.100으로 웹접속하면 Load Balancer는 해당 연결을 일시적으로 대기시킨다.
5. backend 서버쪽으로 LB가 연결한다. 첫번째 연결은 BE의 첫번째 서버로 두번째 연결은 두번째 BE 서버로 연결된다.
6. BE에 있는 웹서버에게 index.html 파일을 요청하고 해당 내용을 lb에게 대기하고 있는 클라이언트에게 제공한다.
7. lb로 부터 index.html 내용을 전달받은 클라이언트는 해당 내용을 자신의 브라우저에 띄운다.
가용성 동작 상태 확인하기
1. web1의 192.168.1.101을 down 시킨다. ifdown ens33
2. 브라우저에서 웹접속을 계속해서 시도해 본다. 페이지는 정상적으로 연결되어야 한다.
3. 192.168.8.100/haproxy?stats 로 접속하여 session 수를 확인하며 한쪽만 올라가는 것을 확인할 수 있다.
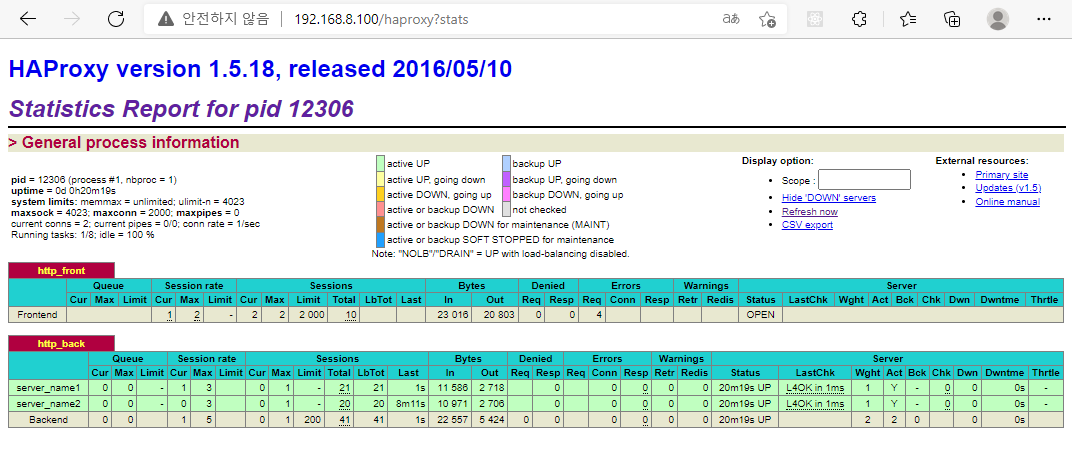
위와같이 해당 주소로 가보니 접속 세션등의 정보를 확인할 수 있다.
그런데 우리는 NFS 가 없을때 서버를 어떻게 업데이트 할 것인가? 이건 git을 이용하면 된다.
자 이걸 AWS에 이 짓거리를 해보자
AWS에서 만들기
도쿄에서 인스턴스를 만들어보겠다.

두번째꺼
flavor 넘기기

인스턴스 2개
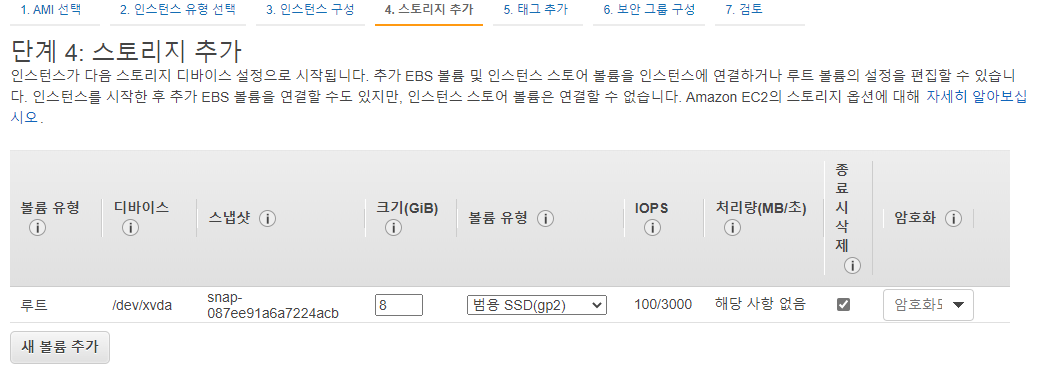
EBS에서 8G 짜리 볼륨 2개 만들어줌.

보면 종류도 다양한데 내려갈수록 가격이 높아진다.
자주 넣고 빼는거면 SSD
장기보존은 마그네틱을 쓰면 좋다.
암튼 넘기기

넘기기

보안그룹에 HTTP 열어놓기
그리고 SSH은 내 IP로 해놓기. 참고로 저거 보여지면 위험해서 감추었다.